本地对象存储导入导入数据
在 MatrixOne 分布式集群中,除了本地导入数据和从公有云对象存储 S3 导入数据到 MatrixOne,还可以通过本地 Minio 组件导入数据。
通过本地 Minio 组件导入数据到 MatrixOne 适用于:遇到没有公网访问或导入文件过大超出本地磁盘空间等情况。
本篇文章将指导您如何使用本地 Minio 导入 CSV 文件。并且本篇文档所介绍到的环境将基于 MatrixOne 分布式集群部署的环境,请确保整个 MatrixOne 已经安装完毕。
步骤
导入数据
你可以通过访问 http://192.168.56.10:32001 来登录 Minio 的图形化界面。账户和密码可以参考 MatrixOne 分布式集群部署章节中安装和部署 Minio 过程中创建的 rootUser 和 rootPassword。登录后,你需要创建一个专属的存储桶 load-from-minio,并将相应的 CSV 文件上传到该存储桶中。
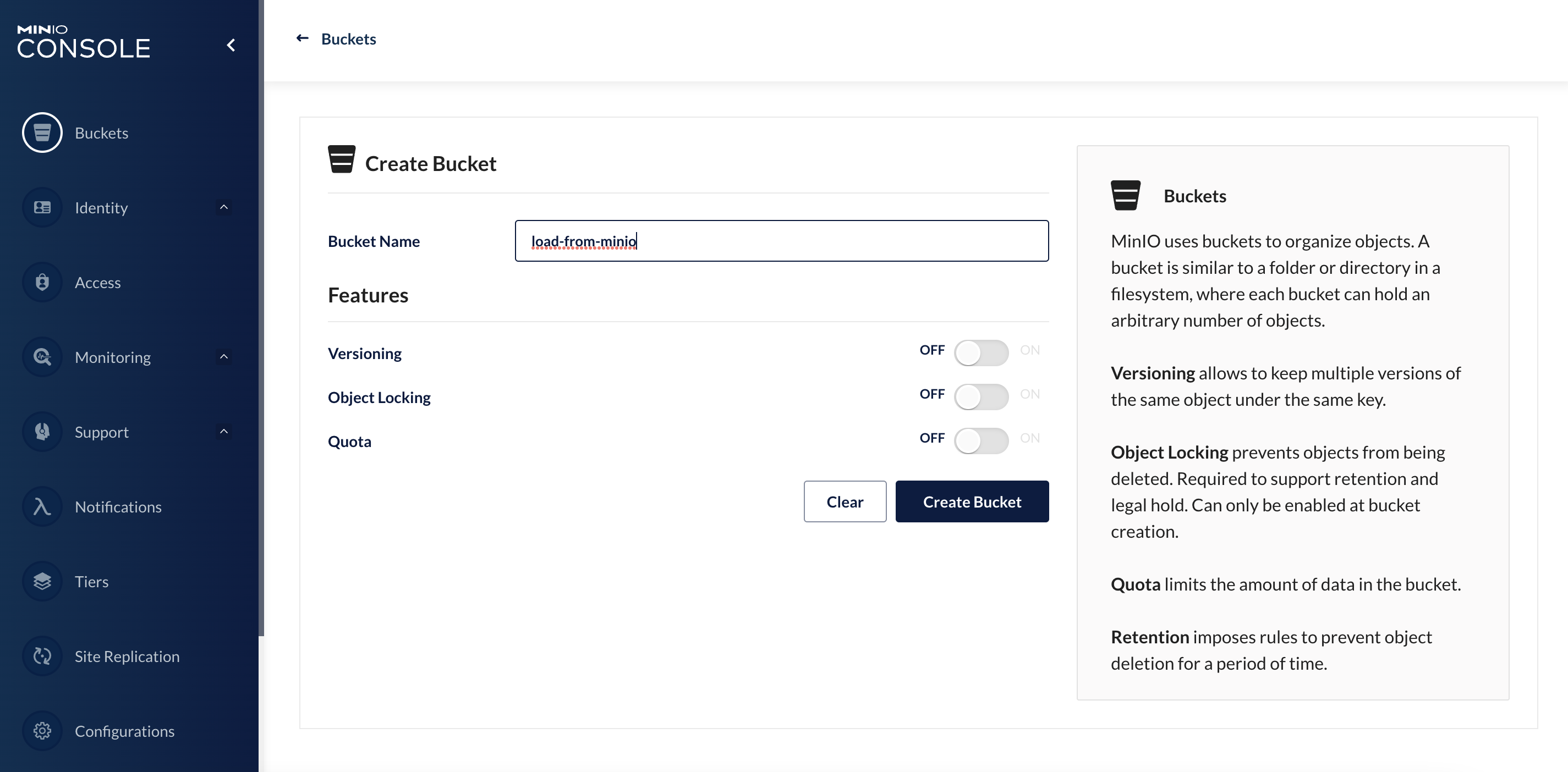
这里我们使用的案例为一个仅包含 6 行数据的简单 addresses.csv 案例。
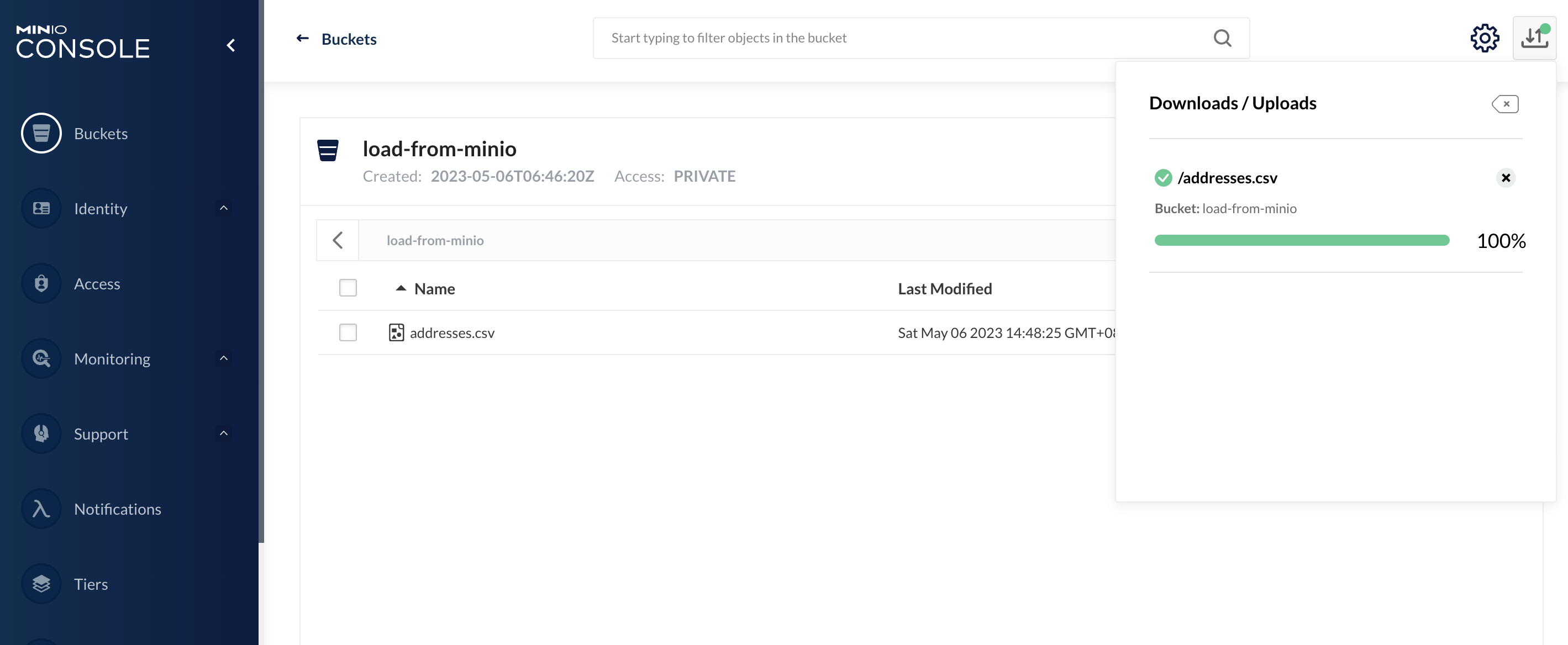
获取 Minio 的 endpoint
从本地 Minio 里加载数据到 MatrixOne 集群的原理与从公有云的对象存储 S3 中加载数据方式完全相同,他们的语法结构一样。但是公有云方式其中的参数会有公有云厂商给出,而本地 Minio 中的参数需要自行设置。
LOAD DATA
| URL s3options {"endpoint"='<string>', "access_key_id"='<string>', "secret_access_key"='<string>', "bucket"='<string>', "role_arn"='xxxx', "external_id"='yyy', "filepath"='<string>', "region"='<string>', "compression"='<string>', "provider"='<string>'}
INTO TABLE tbl_name
[{FIELDS | COLUMNS}
[TERMINATED BY 'string']
[[OPTIONALLY] ENCLOSED BY 'char']
[ESCAPED BY 'char']
]
[IGNORE number {LINES | ROWS}]
[PARALLEL {'TRUE' | 'FALSE'}]
要从本地 Minio 加载数据,首先需要找到 Minio 的 endpoint。在实际操作之前,我们先了解一下整个调用链路的架构。
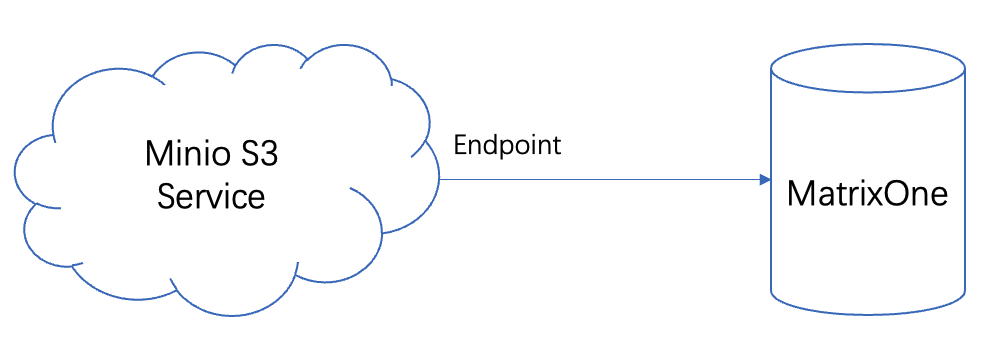
Minio 访问架构
逻辑上来说,MatrixOne 通过 Minio 的访问端口 endpoint 与 Minio 通信,并从中获取数据,如下图所示:
实际上,Minio 在 Kubernetes(K8s)中被纳管,对外提供服务必须通过 K8s 的 Service(SVC)访问。任务的实际执行是在 K8s Pod 中完成的。SVC 可以保证不管 Pod 如何变化,对外部应用来说始终保持统一端口。SVC 与 Pod 的关联需要通过 K8s 中的 Endpoint(EP)来建立规则。因此,MatrixOne 实际上是通过 SVC 与 Minio 服务连接的,具体架构如下图所示:
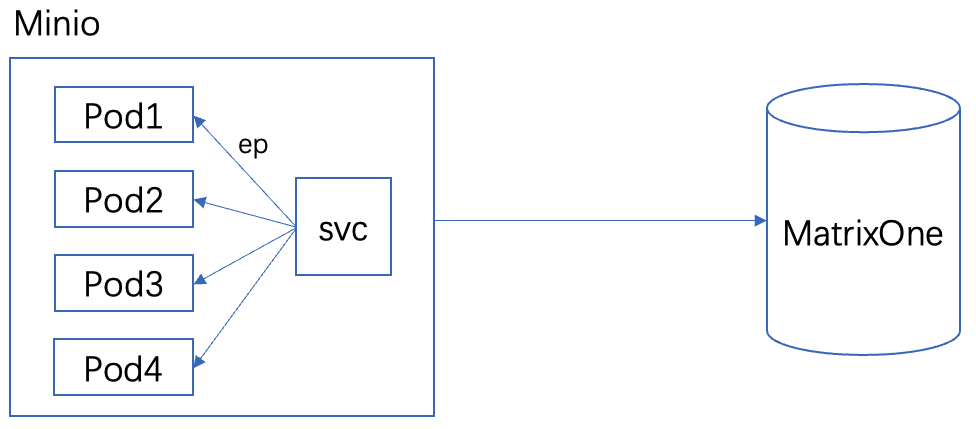
实际命令
我们在安装 Minio 的时候创建了名为 mostorage 的命名空间,我们可以通过以下几条 K8s 命令来找出这个 endpoint。
kubectl get svc -n${ns}:列出这个命名空间下所有的 SVC。kubectl get pod -n${ns}:列出这个命名空间下所有的 Pod。kubectl get ep -n${ns}:列出这个命名空间下所有的转发规则关系。
示例如下:
root@VM-32-16-debian:~# ns="mostorage"
root@VM-32-16-debian:~# kubectl get svc -n${ns}
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
minio ClusterIP 10.96.1.65 <none> 80/TCP 127d
minio1-console NodePort 10.96.3.53 <none> 9090:30869/TCP 127d
minio1-hl ClusterIP None <none> 9000/TCP 127d
root@VM-32-16-debian:~# kubectl get pod -n${ns}
kubectl get ep -n${ns}NAME READY STATUS RESTARTS AGE
minio1-ss-0-0 1/1 Running 0 106d
minio1-ss-0-1 1/1 Running 0 106d
minio1-ss-0-2 1/1 Running 0 106d
minio1-ss-0-3 1/1 Running 0 106d
root@VM-32-16-debian:~# kubectl get ep -n${ns}
NAME ENDPOINTS AGE
minio 100.92.250.195:9000,100.92.250.200:9000,100.92.250.201:9000 + 1 more... 127d
minio1-console 100.92.250.195:9090,100.92.250.200:9090,100.92.250.201:9090 + 1 more... 127d
minio1-hl 100.92.250.195:9000,100.92.250.200:9000,100.92.250.201:9000 + 1 more... 127d
SVC 的访问地址是在 Load 语句中需要添加的终端地址。要构建 SVC 地址,可以使用 ${service_name}.{namespace}.svc.cluster.local 的方式(后三位可省略)。以上命令的结果表明,minio1-hl 的 SVC 使用 9000 作为对外转发端口,minio 的 SVC 使用 80 作为对外转发端口。因此,连接 Mostorage 的 Minio 的最终 endpoint 为:http://minio1-hl.mostorage:9000 或者 http://minio.mostorage:80。
构建并执行 Load 语句
-
按照
addresses.csv的数据结构构建好相应的表:create table address (firstname varchar(50), lastname varchar(50), address varchar(500), city varchar(20), state varchar(10), postcode varchar(20)); -
参照 Load S3 的语法结构,将参数信息填入
Load语句中其中:- access_key_id:为 minio 的登录账号
- secret_access_key:为 minio 的登录密码
- bucket:存储桶的名称
- filepath:为导入文件的路径
需要注意的是,从本地 Minio 带入需要在参数串中增加一条
"provider"="minio"来指明底层存储来源是本地 Minio,最终形成如以下的 SQL 语句。MySQL [stock]> load data url s3option{"endpoint"='http://minio.mostorage:80',"access_key_id"='rootuser', "secret_access_key"='rootpass123',"bucket"='load-from-minio', "filepath"='/addresses.csv', "compression"='none', "provider"="minio"} INTO TABLE address FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' LINES TERMINATED BY '\n' PARALLEL 'TRUE'; Query OK, 6 rows affected (2.302 sec)
Note
"provider"="minio" 仅在本地 Minio 环境中生效,如果从公有云的对象存储中导入数据无需加该参数。