聚类中心
什么是聚类中心
在使用聚类算法,特别是 K-means 算法时,聚类数量 K 代表了你想要将数据集分成的簇(cluster)的数量。每个簇由其聚类中心(centroid)代表,聚类中心是簇内所有数据点的中心点或平均位置。
在 K-means 算法中,K 的选择对聚类结果有很大影响。选择合适的 K 值可以帮助你更好地理解数据的结构和模式。如果 K 值选择不当,可能会导致以下问题:
- K 值太小:可能会导致不同的簇合并在一起,从而丢失数据中的重要模式。
- K 值太大:可能会导致数据过度细分,每个簇只包含很少的数据点,这可能会掩盖数据中的一般趋势。
Matrixone 提供聚类中心查询用于确定向量列的 K 个聚类中心。
聚类中心的应用场景
聚类在数据分析和机器学习领域扮演着重要角色。以下是聚类中心的一些主要应用场景:
-
市场细分:在市场分析中,聚类中心可以帮助识别不同的客户群体特征,从而为每个群体定制营销策略。
-
图像分割:在图像处理中,聚类中心用于区分图像中不同的区域或对象,常用于图像压缩和分割。
-
社交网络分析:通过聚类中心可以识别社交网络中具有相似行为或兴趣的用户群体。
-
异常检测:聚类中心可以帮助识别数据中的异常点,因为异常点通常远离所有聚类中心。
-
天文数据分析:在天文学中,聚类中心可以用于识别星系团或恒星群的特征。
涉及算法
在 Matrixone 中确定向量数据集的聚类中心,涉及到以下算法:
-
Random (随机初始化):在随机初始化中,算法从数据集中随机选择 n_clusters 个观测值作为初始质心点。这种方法简单快速,但可能导致聚类结果的质量依赖于初始质心的选取,因为随机选择可能不会落在数据的稠密区域。
-
K-means++(k-means++ 初始化):k-means++ 是一种更高级的初始化方法,旨在改善随机初始化的不足,它通过多步骤过程来选择初始质心,以增加选择的质心点能够代表数据整体分布的概率。
-
Regular Kmeans(常规 K-means 算法):是一种广泛使用的聚类方法,旨在将数据点划分为 K 个簇,使得簇内的数据点尽可能相似,而簇间的数据点尽可能不同。这种方法基于欧几里得距离来衡量数据点之间的相似性,因此它更适合于在平面空间中处理数据。
-
Spherical Kmeans(球形 K-means):是一种对数据点进行聚类的算法,Spherical K-means 算法计算聚类中心的过程涉及到对数据点进行归一化处理。特别适用于高维且稀疏高维且稀疏的,或者数据点的方向性比距离更为重要的数据,如文本数据、地理位置或用户兴趣模型。
示例
示例 1
假设我们有一组客户的年度购物数据,包括他们的年收入和年度消费总额。我们想要通过这些数据了解客户的消费行为,并将其分成不同的消费行为群体。
步骤
-
建立客户表并插入数据
准备一个名为
customer_table的表,插入 10 条顾客数据。二维向量代表客户的年收入和年度消费总额。CREATE TABLE customer_table(id int auto_increment PRIMARY KEY,in_ex vecf64(2)); INSERT INTO customer_table(in_ex) VALUES("[120,50]"),("[80,25]"),("[200,100]"),("[100,40]"),("[300,120]"),("[150,75]"),("[90,30]"),("[250,90]"),("[75,20]"),("[150,60]"); mysql> select * from customer_table; +------+------------+ | id | in_ex | +------+------------+ | 1 | [120, 50] | | 2 | [80, 25] | | 3 | [200, 100] | | 4 | [100, 40] | | 5 | [300, 120] | | 6 | [150, 75] | | 7 | [90, 30] | | 8 | [250, 90] | | 9 | [75, 20] | | 10 | [150, 60] | +------+------------+ 10 rows in set (0.01 sec) -
确定聚类中心
mysql> SELECT cluster_centers(in_ex kmeans '2,vector_l2_ops,random,false') AS centers FROM customer_table; +------------------------------------------------------------------------+ | centers | +------------------------------------------------------------------------+ | [ [109.28571428571428, 42.857142857142854],[250, 103.33333333333333] ] | +------------------------------------------------------------------------+ 1 row in set (0.00 sec) -
检查聚类中心
一个好的聚类通常会在可视化中显示为明显的分离群组。由下图观察可得,聚类中心选择较为适当。
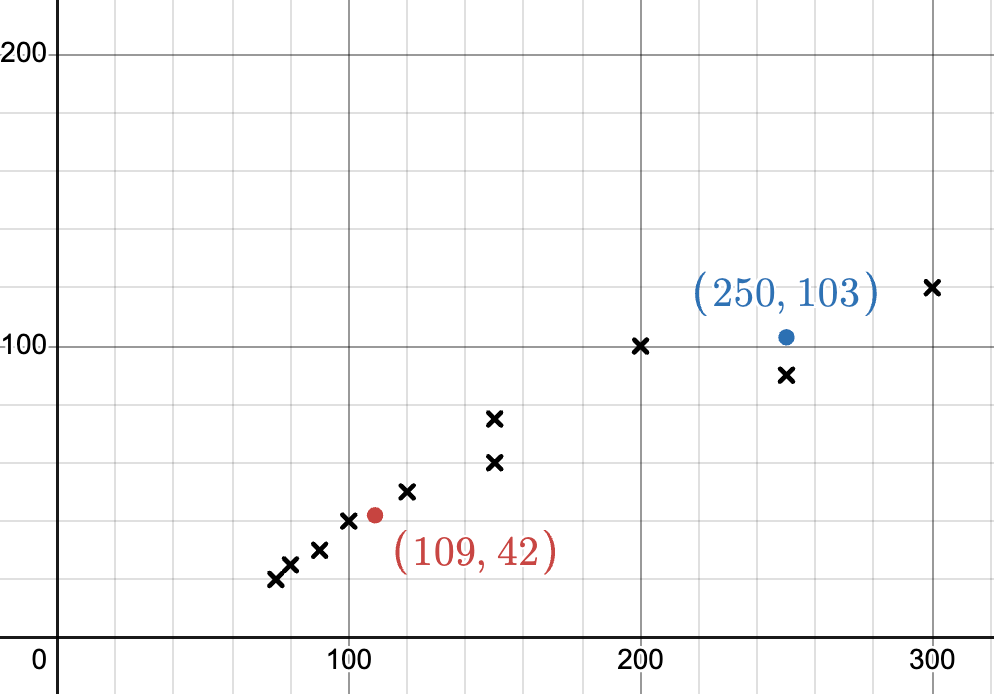
通过聚类中心的确定,我们可以将客户分为两个群体:一个群体是中等收入和中等消费水平的客户(聚类中心 A),另一个群体是较高收入和较高消费水平的客户(聚类中心 B)。商家可以根据每个群体的消费特征调整产品定位,比如为聚类中心 A 提供性价比较高的产品,而为聚类中心 B 提供高端或奢侈品牌。
示例 2
一家音乐流媒体服务想要根据用户对不同音乐类型的偏好将他们分为几个群体,以便提供个性化的播放列表。他们收集了用户对以下 5 种音乐类型的偏好评分(1 分表示不感兴趣,5 分表示非常喜欢):摇滚、流行、爵士、古典和嘻哈。
步骤
-
建立音乐类型表并插入数据
准备一个名为
music_table的表,插入 5 条用户数据。五维向量对应用户对摇滚、流行、爵士、古典和嘻哈五种类型音乐的偏好评分。CREATE TABLE music_table(id int,grade vecf64(5)); INSERT INTO music_table VALUES(1,"[5,2,3,1,4]"),(2,"[3,5,2,1,4]"),(3,"[4,3,5,1,2]"),(4,"[2,5,4,3,1]"),(5,"[5,4,3,2,5]"); mysql> select * from music_table; +------+-----------------+ | id | grade | +------+-----------------+ | 1 | [5, 2, 3, 1, 4] | | 2 | [3, 5, 2, 1, 4] | | 3 | [4, 3, 5, 1, 2] | | 4 | [2, 5, 4, 3, 1] | | 5 | [5, 4, 3, 2, 5] | +------+-----------------+ 5 rows in set (0.01 sec) -
查看向量归一化结果
mysql> select normalize_l2(grade) from music_table; +---------------------------------------------------------------------------------------------------------+ | normalize_l2(grade) | +---------------------------------------------------------------------------------------------------------+ | [0.6741998624632421, 0.26967994498529685, 0.40451991747794525, 0.13483997249264842, 0.5393598899705937] | | [0.40451991747794525, 0.6741998624632421, 0.26967994498529685, 0.13483997249264842, 0.5393598899705937] | | [0.5393598899705937, 0.40451991747794525, 0.6741998624632421, 0.13483997249264842, 0.26967994498529685] | | [0.26967994498529685, 0.6741998624632421, 0.5393598899705937, 0.40451991747794525, 0.13483997249264842] | | [0.562543950463012, 0.4500351603704096, 0.3375263702778072, 0.2250175801852048, 0.562543950463012] | +---------------------------------------------------------------------------------------------------------+ 5 rows in set (0.01 sec) -
确定聚类中心
mysql> SELECT cluster_centers(grade kmeans '2,vector_l2_ops,kmeansplusplus,true') AS centers FROM music_table; +------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | centers | +------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | [ [0.3370999312316211, 0.6741998624632421, 0.40451991747794525, 0.26967994498529685, 0.3370999312316211],[0.5920345676322826, 0.3747450076112172, 0.4720820500729982, 0.16489917505683388, 0.4571945951396342] ] | +------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ 1 row in set (0.00 sec) -
检查聚类中心
使用 t-SNE 将高维数据降到 2D,并可视化聚类结果。从下图可看到数据点在降维后的空间中按聚类中心明显分开,这增加了聚类中心正确性的信心。
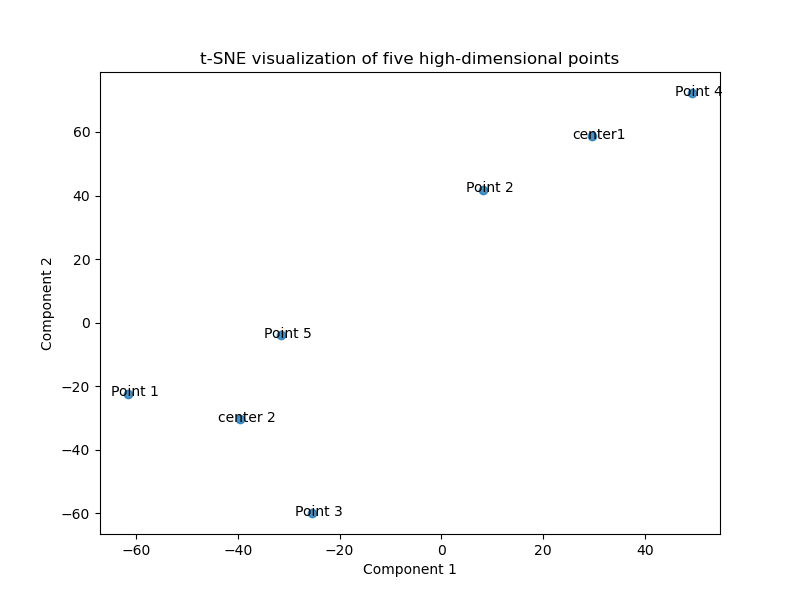
通过聚类中心的确定,我们可以将用户分为两个群体:簇 1 主要由喜欢摇滚和嘻哈音乐的用户组成,这可能代表了一个寻求现代和节奏感强烈音乐的用户群体。簇 2 则由喜欢流行和爵士音乐的用户组成,这可能代表了一个偏好旋律和轻松氛围音乐的用户群体。媒体公司可以根据用户喜好来为他们推送相应风格的音乐类型。