数据缓存及冷热数据分离架构详解
数据缓存及冷热数据分离是 MatrixOne 的一项关键特性,该特性将数据分为热数据和冷数据,以使用频率为区分标准,并将它们以不同的存储方式进行管理。这一设计使得 MatrixOne 在保持优异性能的同时也维持了较低的运行成本。
技术架构
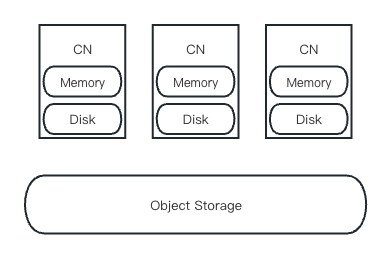
在 MatrixOne 的整体架构中,有两个部分负责持久化数据存储,一个是全体 MatrixOne 分布式集群共享的对象存储,它也是集群的主要存储设备;另一个是各计算节点(CN)上的本地存储,主要用于数据缓存。主存储包含整个集群的全量数据,而缓存则仅保存最近查询时从主存储中提取的数据。此外,CN 节点的内存也作为数据缓存的一部分来使用。
当用户发起查询时,系统首先会检查用户所连接的 CN 的缓存中是否已经包含所需数据。如果存在,系统将直接返回结果给用户,查询优先级是先内存后磁盘。如果在当前连接的 CN 的缓存中没有找到所需数据,系统会查询全局元数据信息,看该用户其他可用的 CN 缓存中是否存在所需数据,检查顺序同样是先内存后磁盘。如果存在,系统将请求转向包含此数据的 CN,由它处理请求,并将结果返回给用户。如果所有可用 CN 的缓存中都没有所查找的数据,系统将发起对对象存储的读取请求,并将结果返回给用户。
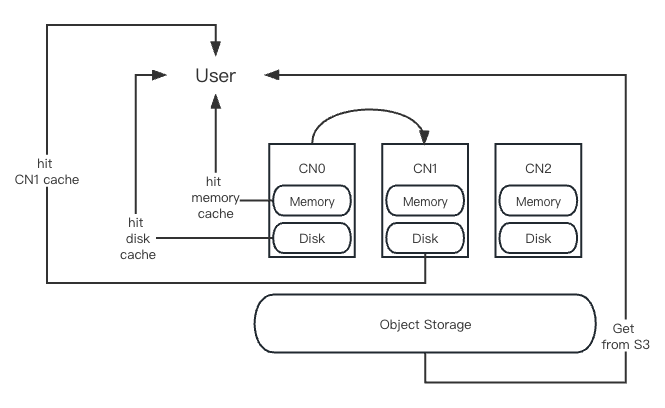
当用户查询对象存储的数据时,查询到的数据块 (block) 会根据缓存的查询顺序,依次填充到相应位置。例如,用户从对象存储中查询出了 100M 的数据,这 100M 的数据会首先写入用户所连接的 CN 节点的内存,然后再写入这个 CN 节点的磁盘缓存。每次有新查询产生时,都会按照这个规则更新缓存中的数据。无论是内存还是磁盘,CN 缓存中数据的替换都遵循 LRU(最近最少使用)原则。通过这样的机制,最新的数据始终处于最易获取的位置,而相对冷门的数据则会逐步从缓存中移除。
产品特性
数据缓存及冷热数据分离的特性为产品带来了一些独特优势。为了具体说明,我们将以一个简单的实例进行展示。
环境配置
本章所介绍到的环境将基于 MatrixOne 分布式集群部署的环境,请确保整个 MatrixOne 已经安装完毕。
-
准备一个名为
pe的表格以及对应的 csv 数据。这个 csv 数据表的大小为 35.8MB,共有 1,048,575 行数据。我们将使用以下的 SQL 语句创建两个数据库,并将相同的数据表加载至这两个数据库中的pe表。create database stock; drop table if exists stock.pe; create table stock.pe ( ts_code VARCHAR(255) DEFAULT null, trade_date VARCHAR(255) DEFAULT null, pe FLOAT DEFAULT null, pb FLOAT DEFAULT null ); load data local infile '/XXX/pe.csv' into table stock.pe fields TERMINATED BY '\t'; create database stock2; drop table if exists stock2.pe; create table stock2.pe ( ts_code VARCHAR(255) DEFAULT null, trade_date VARCHAR(255) DEFAULT null, pe FLOAT DEFAULT null, pb FLOAT DEFAULT null ); load data local infile '/XXX/pe.csv' into table stock.pe fields TERMINATED BY '\t'; -
接下来进行相应的缓存配置。在 MatrixOne 的集群 yaml 设置中,TN、Log Service 以及 CN 都有与缓存相关的设置,但你只需关注与查询直接相关的 CN 缓存,主要的缓存大小由
memoryCacheSize和diskCacheSize来管理。metadata: name: mo namespace: mo-hn spec: cnGroups: - name: cn-set1 # 中间配置省略 sharedStorageCache: # 配置 CN 缓存的核心参数 memoryCacheSize: 250Mi # CN 的内存缓存,Mi 代表 MB diskCacheSize: 1Gi # CN 的磁盘缓存,Gi 代表 GB
当这两个参数都被设置为 "1" 时,即代表关闭了缓存,MatrixOne 的所有查询请求将直接与底层对象存储进行交互,查询效率将大大降低。
为了简化展示,你可以在此先将内存缓存关闭,仅设置一定大小的磁盘缓存。由于原始数据在入库后会根据数据类型有一定的压缩比例,所以你需要先将将磁盘缓存设置为 20MB,这大概足以存放压缩后的 35.8MB 数据文件。
metadata:
name: mo
namespace: mo-hn
spec:
cnGroups:
- name: cn-set1
##省略中间配置
sharedStorageCache: #调配 CN 缓存的核心参数
memoryCacheSize: "1" #CN 的内存缓存,Mi 代表 MB
diskCacheSize: 20Mi #CN 的磁盘缓存,Gi 代表 GB
查询加速
完成以上设置并启动 MatrixOne 集群后,你可以通过多次查询的结果来体验缓存加速的效果。这里,你可以连续运行多次 stock.pe 的全表扫描。
mysql> select * from stock.pe into outfile "test01.txt";
Empty set (6.53 sec)
mysql> select * from stock.pe into outfile "test02.txt";
Empty set (4.01 sec)
mysql> select * from stock.pe into outfile "test03.txt";
Empty set (3.84 sec)
mysql> select * from stock.pe into outfile "test04.txt";
Empty set (3.96 sec)
从上述结果中,你可以看到第一次查询时,由于需要从对象存储中获取数据,速度明显较慢。然而,在后续的三次查询中,由于数据已被缓存至磁盘,查询速度显著提升。
缓存置换
接下来,你可以交替运行多次 stock.pe 及 stock2.pe 的全表扫描。
mysql> select * from stock2.pe into outfile "test05.txt";
Empty set (5.84 sec)
mysql> select * from stock2.pe into outfile "test06.txt";
Empty set (4.27 sec)
mysql> select * from stock2.pe into outfile "test07.txt";
Empty set (4.15 sec)
mysql> select * from stock.pe into outfile "test08.txt";
Empty set (6.37 sec)
mysql> select * from stock.pe into outfile "test09.txt";
Empty set (4.14 sec)
mysql> select * from stock.pe into outfile "test10.txt";
Empty set (3.81 sec)
你可能会注意到,每次切换查询的数据表时,查询效率有显著下降。这是因为缓存有置换机制,你只设定了一块较小的缓存,只足够存放一张表的全量数据,因此每次交替查询时,旧的缓存数据会被置换出去,新的查询需要从对象存储中获取数据,而再次查询时,由于数据已被缓存,查询速度得到提升。
查询预热
在许多业务场景中,由于数据量庞大或查询复杂,我们常常需要加速查询。而 MatrixOne 的缓存机制可以通过预热数据来实现查询加速。
例如,以下的 SQL 查询:
SELECT pe1.ts_code, pe1.pe, pe1.pb
FROM stock2.pe as pe1
WHERE pe1.pe = (SELECT min(pe2.pe)
FROM stock2.pe as pe2
WHERE pe1.ts_code = pe2.ts_code)
ORDER BY trade_date
DESC LIMIT 1;
如果未进行优化,直接执行的速度如下:
SELECT pe1.ts_code, pe1.pe, pe1.pb
FROM stock2.pe as pe1
WHERE pe1.pe = (SELECT min(pe2.pe)
FROM stock2.pe as pe2
WHERE pe1.ts_code = pe2.ts_code)
ORDER BY trade_date
DESC LIMIT
1;
+-----------+------+--------+
| ts_code | pe | pb |
+-----------+------+--------+
| 000038.SZ | 0 | 1.2322 |
+-----------+------+--------+
1 row in set (5.21 sec)
这条 SQL 查询仅涉及 stock2.pe 表的查询,我们可以通过预先扫描全表数据,将表数据预热到缓存中,这样再进行查询就可以大幅提高这条 SQL 的查询速度。
mysql> select * from stock2.pe into outfile "test11.txt";
Empty set (6.48 sec)
mysql> SELECT pe1.ts_code, pe1.pe, pe1.pb FROM stock2.pe as pe1 WHERE pe1.pe = (SELECT min(pe2.pe) FROM stock2.pe as pe2 WHERE pe1.ts_code = pe2.ts_code) ORDER BY trade_date DESC LIMIT 1;
+-----------+------+---------+
| ts_code | pe | pb |
+-----------+------+---------+
| 000068.SZ | 0 | 14.6959 |
+-----------+------+---------+
1 row in set (2.21 sec)
此功能尤其适用于一些固定的报表计算场景,用户可以通过预热查询涉及的数据,然后再进行查询,这样可以显著提升查询效果。