Logservice 架构详解
Logservice 在 MatrixOne 中扮演着非常重要的角色,它是一个独立的服务,通过 RPC 的方式供外部组件使用,用于日志管理。
Logservice 使用基于 Raft 协议的 dragonboat 库(multi-raft group 的 Go 语言开源实现),通常使用本地磁盘以多副本的方式存储日志,类似于对 WAL(Write-Ahead Log)的管理。事务的提交只需要写入 Logservice 中,而无需将数据写入 S3。另外的组件会异步地将数据批量写入 S3 上。这样的设计保证了事务提交时的低延迟,并且多个副本确保了数据的高可靠性。
Logservice 架构
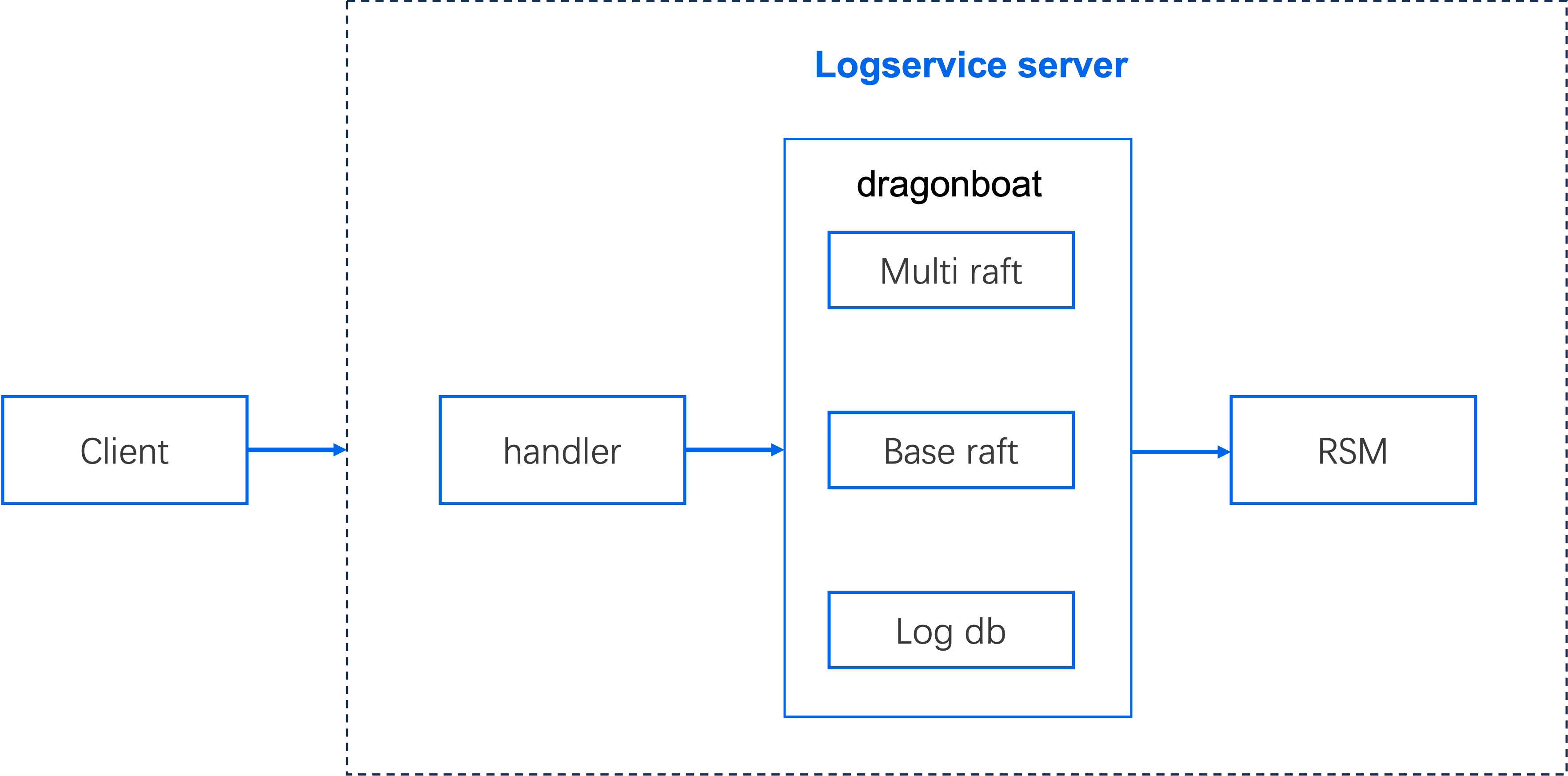
Logservice 的架构由客户端和服务端两部分组成。服务端包括 handler、dragonboat 和 RSM(Replicated State Machine)等模块,而客户端则包含多个关键接口。它们之间的协作关系如下图所示:
客户端
Logservice 客户端主要由 TN(事务节点)调用,并提供以下关键接口:
Close():关闭客户端连接。Config():获取客户端相关配置。GetLogRecord():返回一个pb.LogRecord变量,其中包含 8 字节的 LSN(日志序列号)、4 字节的记录类型和 1 个类型为[]byte的数据字段。数据字段包括 4 字节的pb.UserEntryUpdate、8 字节的副本 TN ID,以及payload []byte。Append():将pb.LogRecord追加到 Logservice,并返回 LSN。在调用端,参数pb.LogRecord可以复用。Read():从 Logservice 中读取从指定firstLsn开始的日志,直到达到maxSize为止。返回的 LSN 作为下一次读取的起点。Truncate():删除指定 LSN 之前的日志,释放磁盘空间。GetTruncatedLsn():返回最近删除的日志的 LSN。GetTSOTimestamp():向 TSO(Timestamp Oracle)请求指定数量的时间戳。调用者占用[returned value, returned value + count]的范围。目前该方法暂未使用。
Logservice 客户端通过 MO-RPC 向 Logservice 服务端发送请求,服务端与 Raft/dragonboat 进行交互并返回结果。
服务端
Server Handler
Logservice 的服务器端接收来自客户端的请求并进行处理。入口函数为 (*Service).handle(),不同的请求会调用不同的方法进行处理:
- Append:将日志追加到 Logservice,最终调用 dragonboat 的
(*NodeHost) SyncPropose()方法进行同步提交 propose 请求。需要等待日志提交并应用后才能返回,返回值是成功写入日志后的 LSN(日志序列号)。 - Read:从日志数据库中读取日志条目。首先调用
(*NodeHost) SyncRead()方法从状态机中进行线性读取到当前的 LSN,然后根据 LSN 调用(*NodeHost) QueryRaftLog()方法从日志数据库中读取日志条目。 - Truncate:截断日志数据库中的日志,释放磁盘空间。需要注意的是,这里只是更新状态机中可以截断的最新 LSN,而不是真正执行截断操作。
- Connect:建立与 Logservice 服务器的连接,并尝试读写状态机以进行状态检查。
- Heartbeat:包括对 Logservice、CN 和 TN 的心跳。该请求会更新 HAKeeper 的状态机中各自的状态信息,并同步 HAKeeper 的 tick。在 HAKeeper 进行检查时,根据 tick 比较离线时间,如果离线,则触发移除(Remove)或关闭(Shutdown)等操作。
- Get XXX:从状态机中获取相关信息。
Bootstrap
Bootstrap 是在 logservice 服务启动时进行的过程,通过 HAKeeper 分片(shard ID 为 0)完成。入口函数为 (*Service) BootstrapHAKeeper。
无论配置中设置了多少个副本,每个 logservice 进程在启动时都会启动一个 HAKeeper 的副本。每个副本在启动时都会设置成员(members),HAKeeper 分片以这些成员作为默认的副本数启动 Raft。
在完成 Raft 的领导者选举后,执行设置初始集群信息(set initial cluster info),设置日志和 TN 的分片数以及日志的副本数。
设置完成副本数后,多余的 HAKeeper 副本将被停止。
心跳(Heartbeat)
该心跳是由 Logservice、CN 和 TN 发送到 HAKeeper 的心跳,而不是 Raft 副本之间的心跳。它主要有两个作用:
- 通过心跳将各个副本的状态信息发送给 HAKeeper,使得 HAKeeper 的状态机更新副本信息。
- 在心跳返回时,从 HAKeeper 中获取需要副本执行的命令。
Logservice 的心跳流程如下图所示,CN 和 TN 的流程类似。
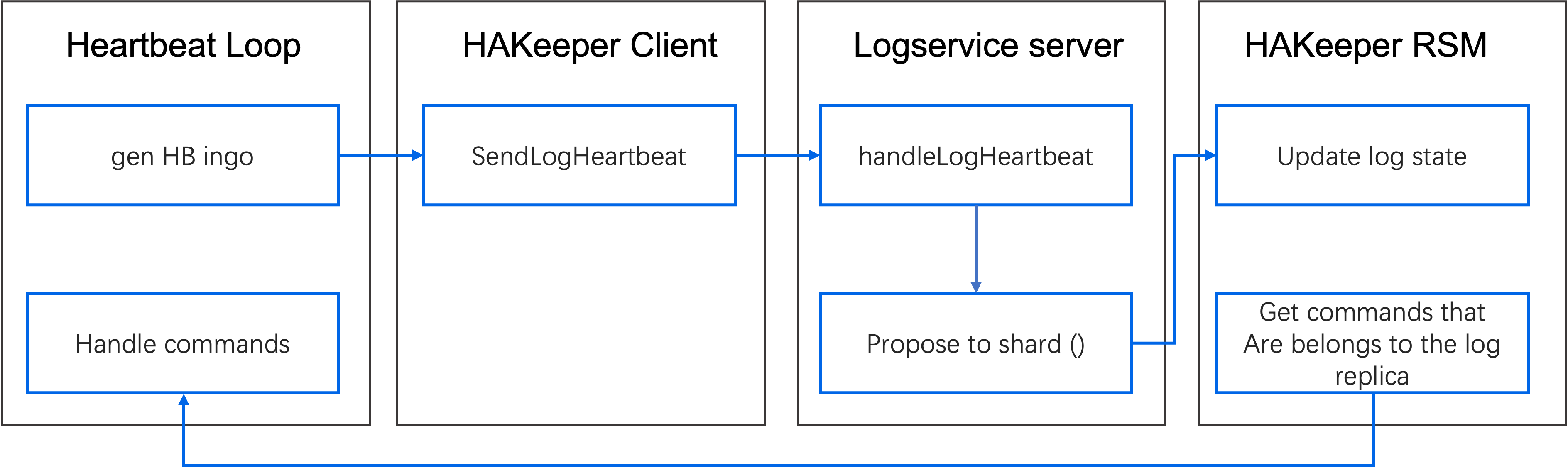
默认情况下,心跳每秒执行一次,其原理如下:
- 在存储级别生成该存储上所有分片副本的心跳信息,包括分片 ID、节点信息、term、leader 等。
- 将请求发送到 Logservice 的服务器端。
- 服务器收到请求后调用
(*Service) handleLogHeartbeat()方法进行处理,并调用 propose 将心跳发送到 Raft。 - HAKeeper 的状态机接收到心跳后,调用
(*stateMachine) handleLogHeartbeat()方法进行处理,主要执行以下两个任务:- 更新状态机中的 LogState:调用
(*LogState) Update()方法更新存储和分片的信息。 - 从状态机的
ScheduleCommands中获取命令,并返回给发起端执行。
- 更新状态机中的 LogState:调用
CN 和 TN 向 HAKeeper 发送心跳的原理也类似。
状态机(RSM)
Logservice 和 HAKeeper 的状态机都是基于内存的状态机模型,所有数据仅保存在内存中。它们都实现了 IStateMachine 接口,其中关键的方法如下:
Update():在完成一次 propose 并提交(即多数副本完成写入)后,会调用Update()方法来更新状态机中的数据。Update()方法的实现由用户完成,必须是无副作用的(Side effect),即相同的输入必须得到相同的输出结果,否则会导致状态机不稳定。Update()方法的结果通过 Result 结构返回,如果发生错误,则 error 不为空。Lookup():用于查找状态机中的数据。通过interface{}参数指定要查找的数据类型,返回的结果也是interface{}类型。因此,用户需要自己定义状态机中的数据,并传入相应的数据类型,再进行类型断言。Lookup() 是只读方法,不应修改状态机中的数据。SaveSnapshot():创建快照,将状态机中的数据写入io.Writer接口,通常是文件句柄。因此,最终会保存到本地磁盘文件中。ISnapshotFileCollection表示状态机以外的文件系统中的文件列表(如果有),这些文件也会一并存储到快照中。第三个参数用于通知快照过程,Raft 副本已停止,终止快照操作。RecoverFromSnapshot():恢复状态机数据,从io.Reader中读取最新的快照数据。[]SnapshotFile表示一些额外的文件列表,直接复制到状态机数据目录中。第三个参数用于控制,在进行 Raft 副本时也停止恢复快照的操作。Close():关闭状态机,执行一些清理工作。
读写流程
在 Logservice 中,一次读写请求的大致流程如下:
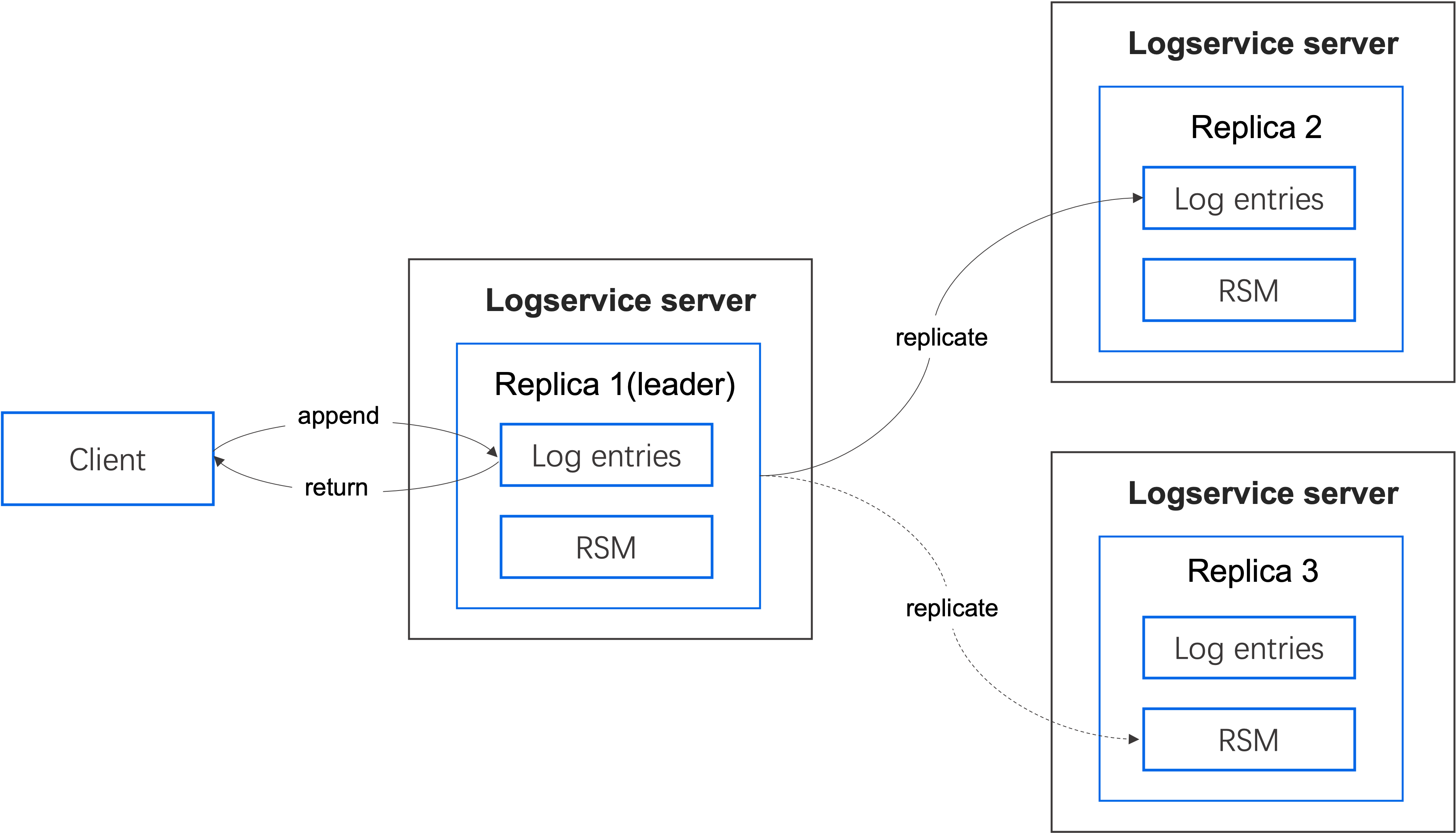
写流程
- 如果连接的节点不是 leader,请求会被转发到 leader 节点;当 leader 节点接收到请求后,将日志条目写入本地磁盘。
- 同时,异步地将请求发送给 follower 节点;当 follower 节点接收到请求后,将日志条目写入本地磁盘。
- 当本次写入在大多数节点上完成后,更新提交索引(commit index),并通过心跳通知其他 follower 节点。
- Leader 在提交后开始执行状态机操作(apply)。
- 当状态机操作完成后,将结果返回给客户端。
- Follower 节点在接收到来自 leader 的提交索引后,各自执行自己的状态机操作。
读流程
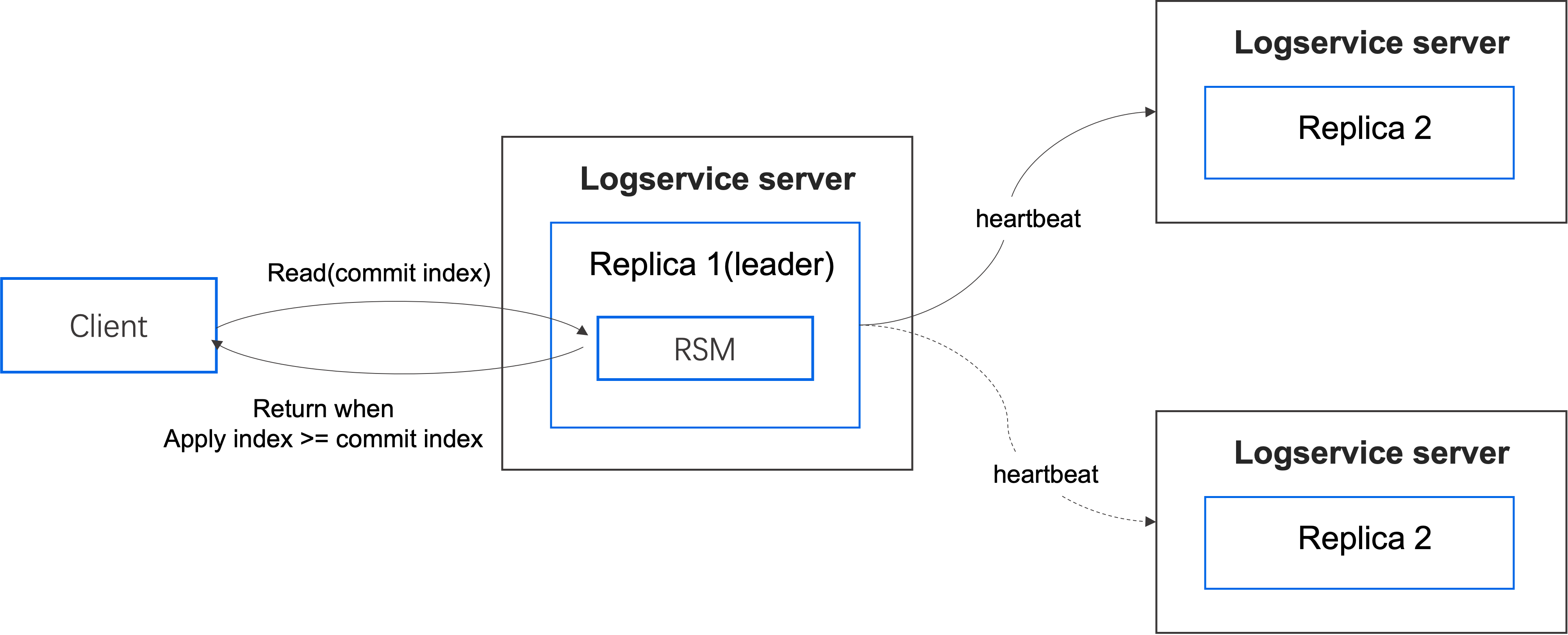
读取数据分为两种情况:
-
从状态机中读取数据。
- 客户端发起读取请求,当请求到达 leader 节点时,会记录当前的提交索引(commit index)。
- Leader 节点向所有节点发送心跳请求,确认自身的 leader 地位,当大多数节点回复后确认仍为 leader,可以回复读取请求。
- 等待应用索引(apply index)大于或等于提交索引(commit index)。
- 一旦满足条件,可以读取状态机中的数据,并返回给客户端。
-
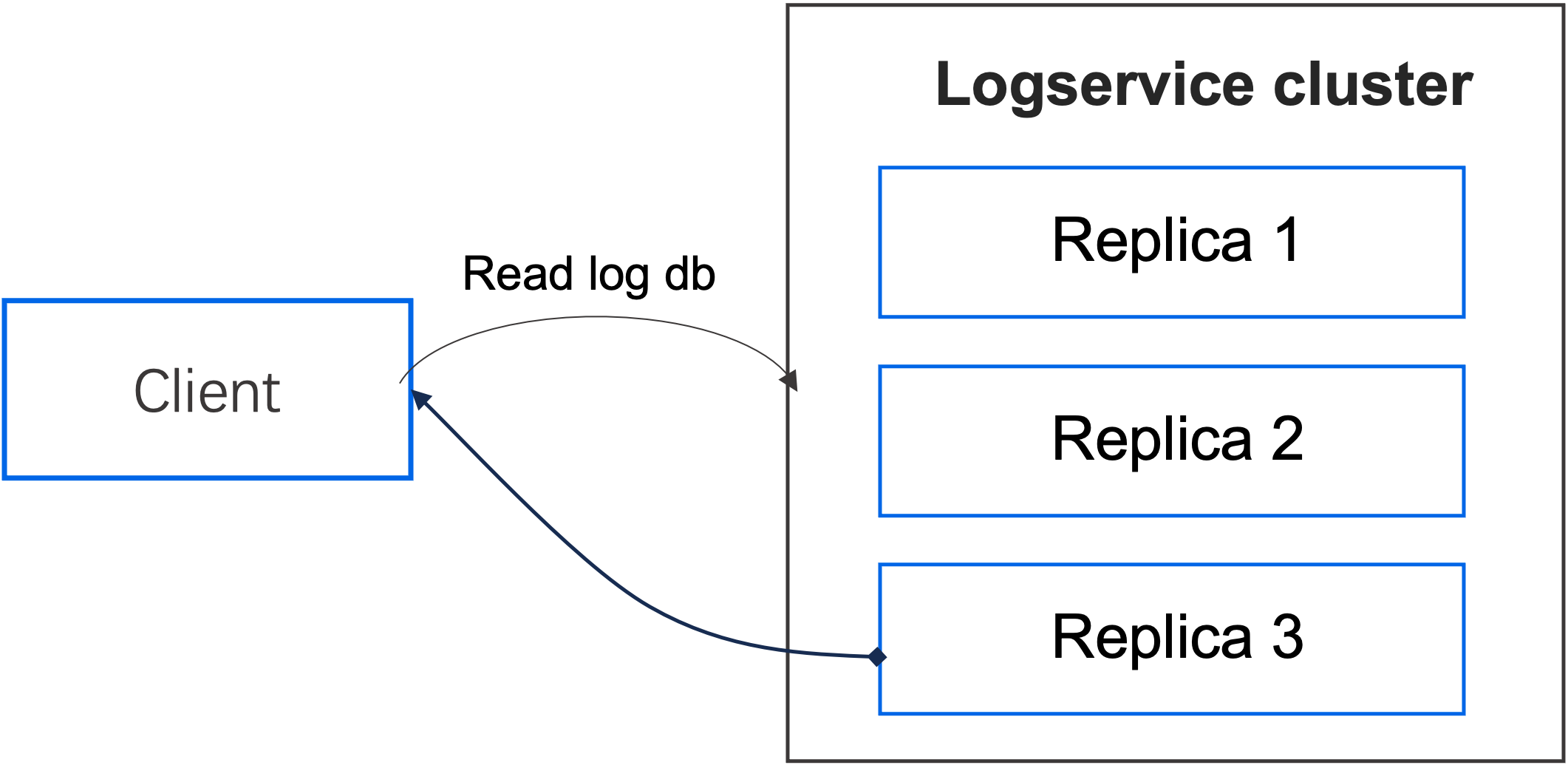
从日志数据库(log db)中读取日志条目。
- 该过程通常发生在集群重启时。
- 在重启时,副本需要先从快照(snapshot)中恢复状态机的数据,然后从快照中记录的索引位置开始读取日志数据库中的日志条目,并应用到状态机中。
- 该操作完成后,副本才能参与 leader 的选举。
- 当集群选举出 leader 后,数据节点(TN)会连接到 logservice 集群,并从一个副本的日志数据库的上一次检查点位置开始读取日志条目,并将其回放(replay)到数据节点自身的内存数据中。
截断(Truncation)
当 logservice 的日志条目在 log db 中不断增长时,会导致磁盘空间不足。因此,需要定期释放磁盘空间,这通过截断(truncation)来完成。
logservice 使用基于内存的状态机,状态机中只记录了一些元数据和状态信息,例如 tick、state 和 LSN 等,并没有记录用户数据,这些数据由数据节点(TN)自己记录。可以将其理解为在主从架构中,状态机是分离的,TN 和 logservice 分别维护各自的状态机。
在这种状态机分离的设计下,简单的快照(snapshot)机制会导致问题:
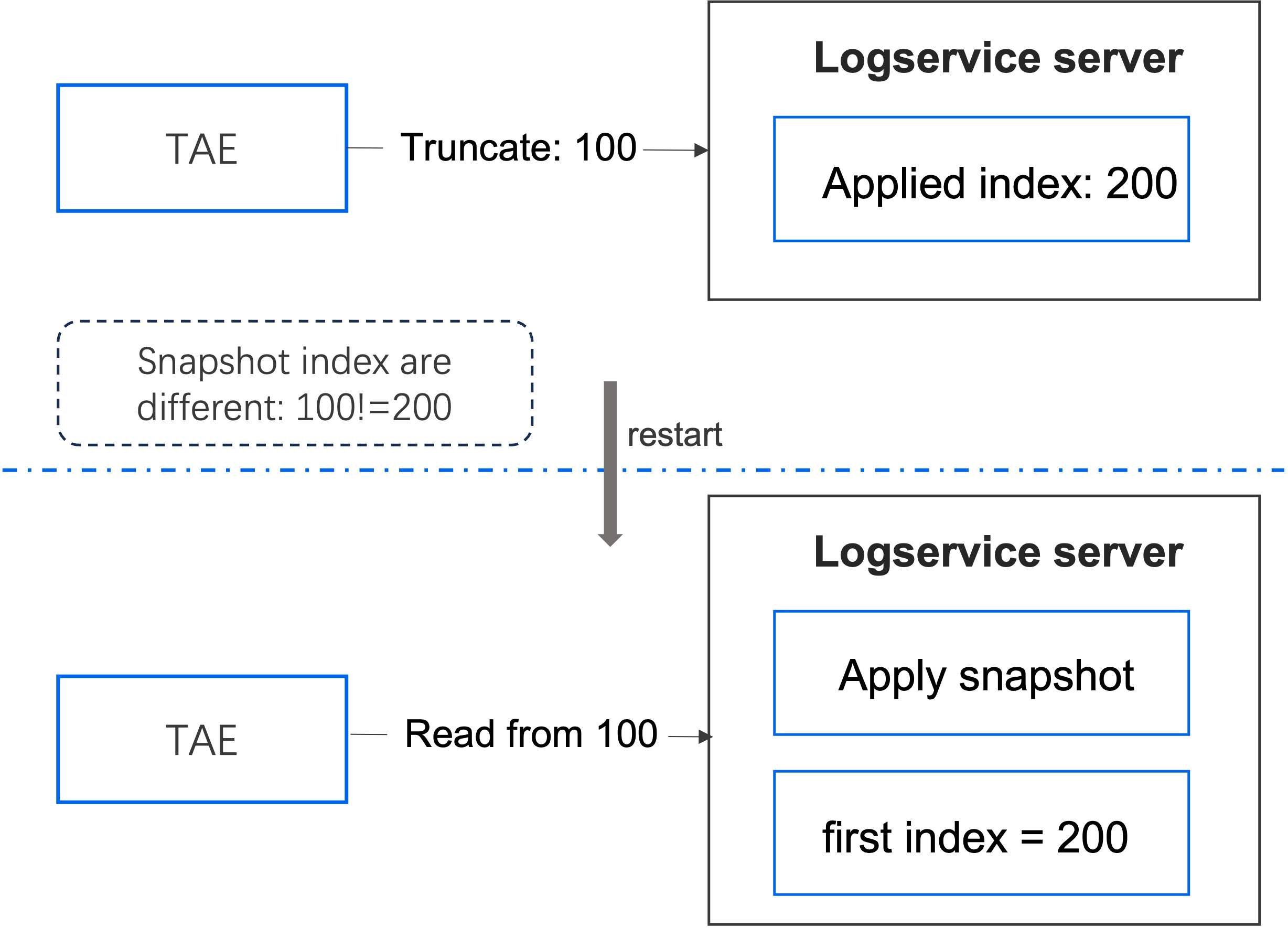
- 当 TN 发送一个截断请求时,截断索引(truncate index)设为 100,但此时 logservice 状态机的应用索引(applied index)是 200,即会删除 200 之前的日志,并在该位置生成快照。注意:截断索引不等于应用索引。
- 集群重启。
- logservice 状态机应用快照,索引为 200,并设置首个索引(first index)为 200(删除了 200 之前的日志),然后状态机开始回放日志,回放完成后提供服务。
- TN 从 logservice 读取日志条目,起始位置为 100,但无法读取,因为 200 之前的日志已被删除,出现错误。
为解决上述问题,当前的截断工作流程如下:
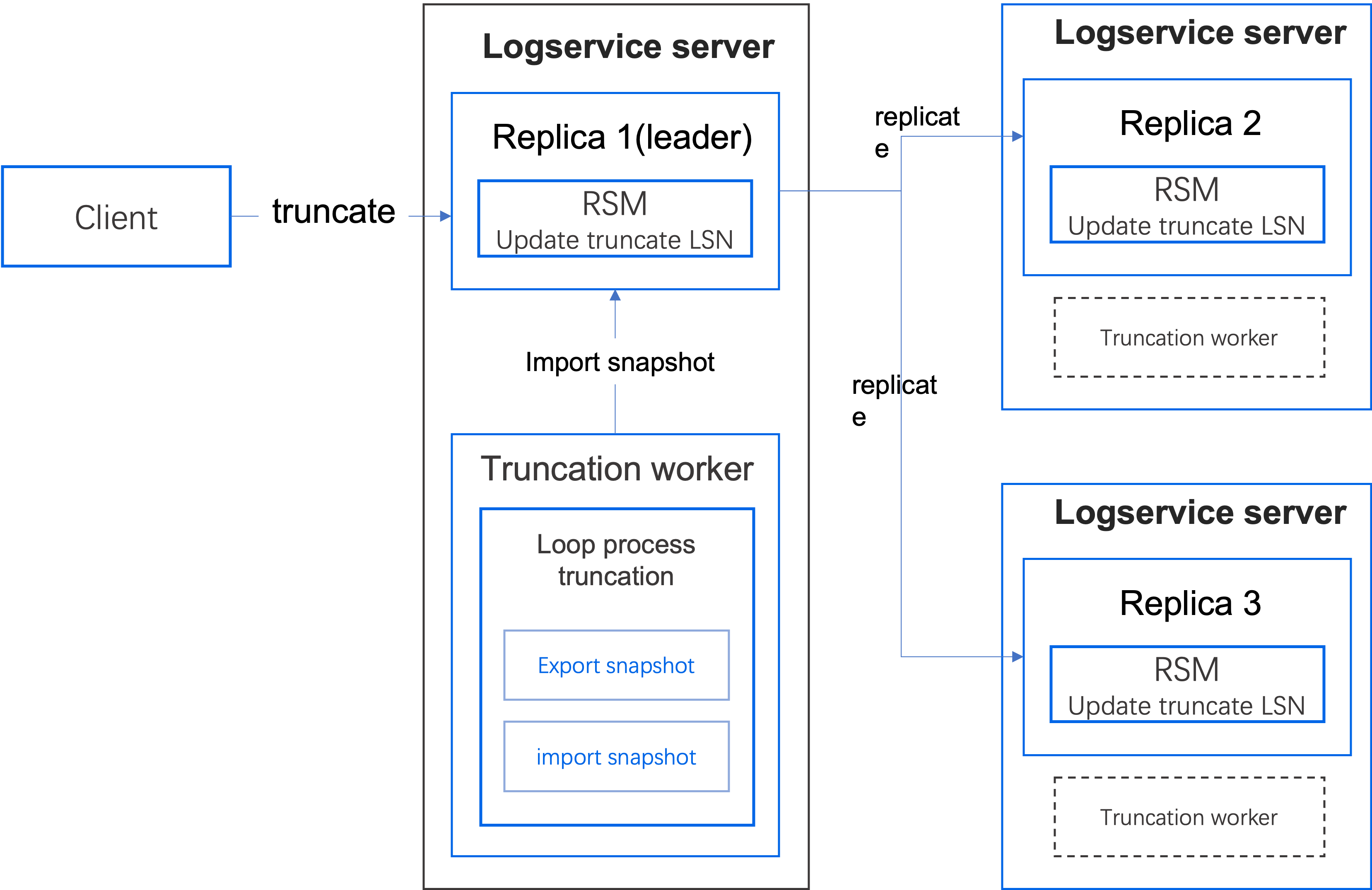
- TN 发送截断请求,更新 logservice 状态机中的截断 LSN(truncateLsn),此时仅更新该值,不执行快照/截断操作。
- 每个 logservice 服务器内部启动一个截断工作器(truncation worker),定期发送截断请求(Truncate Request)。需要注意的是,该请求中的参数 Exported 设置为 true,表示该快照对系统不可见,仅将快照导出到指定目录下。
- 截断工作器还会检查当前已导出的快照列表,查看是否有索引大于 logservice 状态机中的截断 LSN 的快照。如果有,将最接近截断 LSN 的快照导入系统中,使其生效并对系统可见。
- 所有副本执行相同的操作,确保两个状态机的快照 LSN 是一致的,这样在集群重启时可以读取到相应的日志条目。