MatrixOne 的定位
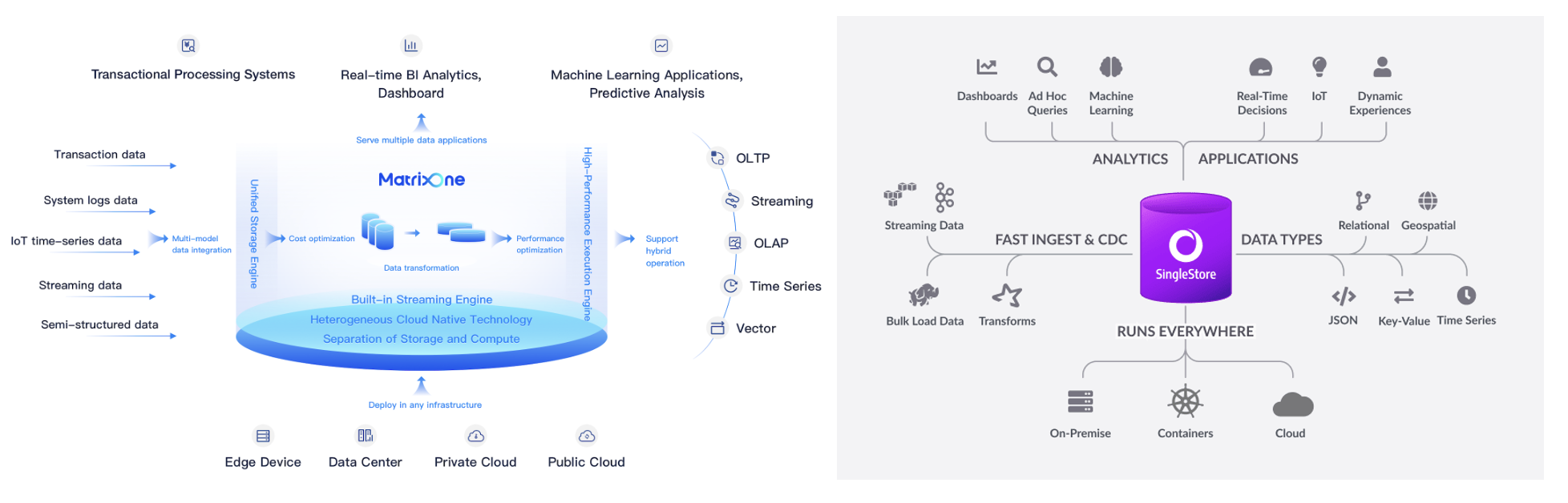
在庞大而复杂的数据技术栈和各类数据库产品中,MatrixOne 的定位是一款主打一站式融合能力和灵活扩展性的 SQL 关系型数据库。MatrixOne 的设计目标是提供一个使用体验如 MySQL 一样简单的数据库产品,可以处理包括 OLTP 和 OLAP 等各类业务负载和数据类型,同时能感知用户的负载和数据量变化自动化的进行快速弹性伸缩,以简化用户当前复杂的多数据库产品+ETL 的传统数据架构。
在行业现有的数据库产品中来说与 MatrixOne 最接近的数据库产品是 SingleStore,两者都采用统一存储模型,支持 OLTP,OLAP 以及其他一系列数据负载和数据类型的融合,同时也都以云原生和可灵活扩展作为自己的核心架构能力。
-
从架构上来说,MatrixOne 是一款完全云原生和容器化的数据库,MatrixOne 借鉴了 Snowflake 对云原生数据仓库的存算分离设计,完全将存储交于云上的共享存储,同时将计算层完全构建成了无状态化的容器。同时,为了能适应 OLTP 类型负载对快速写入请求的处理,MatrixOne 增加了 TN 及 LogService 的概念,以块存储来支撑高频写入,通过 Raft 三副本一致性保证来确保写入日志 WAL 的高可用,同时再异步的将 WAL 落盘到共享存储中。与 SingleStore 不同之处在于 SingleStore 是从 Share-nothing 架构上扩展到了云原生的存算分离上,其仅将冷数据放入共享存储(可参考 SingleStore 架构论文),依然需要做数据分片和再平衡。而 MatrixOne 与 Snowflake 一致,则是完全基于共享存储,没有任何数据分片。
-
从负载类型上来说,MatrixOne 以 HTAP 为基本核心,逐步扩展至流计算,时序处理,机器学习,搜索等多种负载类型。在 HTAP 的技术路线上,MatrixOne 与以 TiDB 为主的双存储和计算引擎路线不同的是,MatrixOne 是直接在单存储引擎和计算引擎上实现 HTAP,存储引擎也是以落盘列存为主,内存行存为辅的架构,这点与 SingleStore 也较为一致。TiDB 一类的技术路线需要内部进行双引擎数据同步,同时 TP 与 AP 数据需要单独存储,而 MatrixOne 不需要做此同步及多份存储。相比 SingleStore 已经对流计算,搜索,GIS,机器学习等 HTAP 以外的其他多种业务类型都有良好支持,MatrixOne 本身发展时间较晚,目前除了 HTAP 以外对其他负载类型的支持程度不够完善。
- 从使用体验上来说,MatrixOne 以 MySQL 为核心兼容目标,包括从传输协议,SQL 语法,基本功能上都全面兼容 MySQL。MatrixOne 仅在 MySQL 不支持的能力上,如流式写入,向量类型等能力上有自己独特的语法。同时 MySQL 有部分高级能力,如触发器,存储过程等,由于用户使用率较低,MatrixOne 暂时未支持。总体来说,基于 MySQL 开发的应用,可以非常轻松的迁移到 MatrixOne 上,同时 MySQL 生态相关工具,如 Navicat,DBeaver 等可视化管理和建模工具,DataX,Kettle 等 ETL 工具,以及 Spark,Flink 等计算引擎,都可以直接使用 MySQL 相关 connector 与 MatrixOne 对接使用。