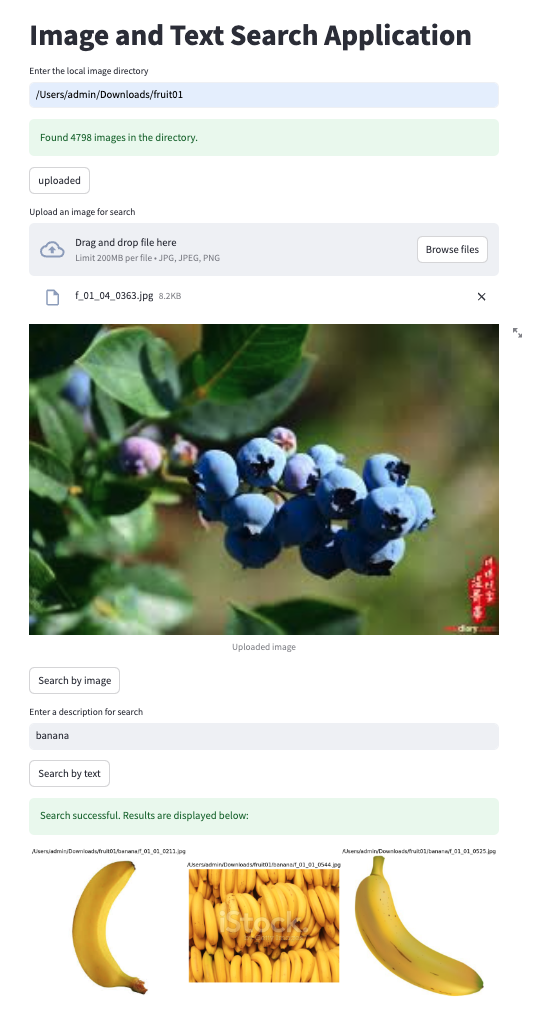
以图(文)搜图应用基础示例
当下,以图搜图和以文搜图的相关应用涵盖了广泛的领域,在电子商务中,用户可以通过上传图片或文本描述来搜索商品;在社交媒体平台,通过图像或文本快速找到相关内容,增强用户的体验;而在版权检测方面,则可以帮助识别和保护图像版权;此外,以文搜图还广泛应用于搜索引擎,帮助用户通过关键词找到特定图像,而以图搜图则在机器学习和人工智能领域中用于图像识别和分类任务。
以下为以图(文)搜图的流程图:
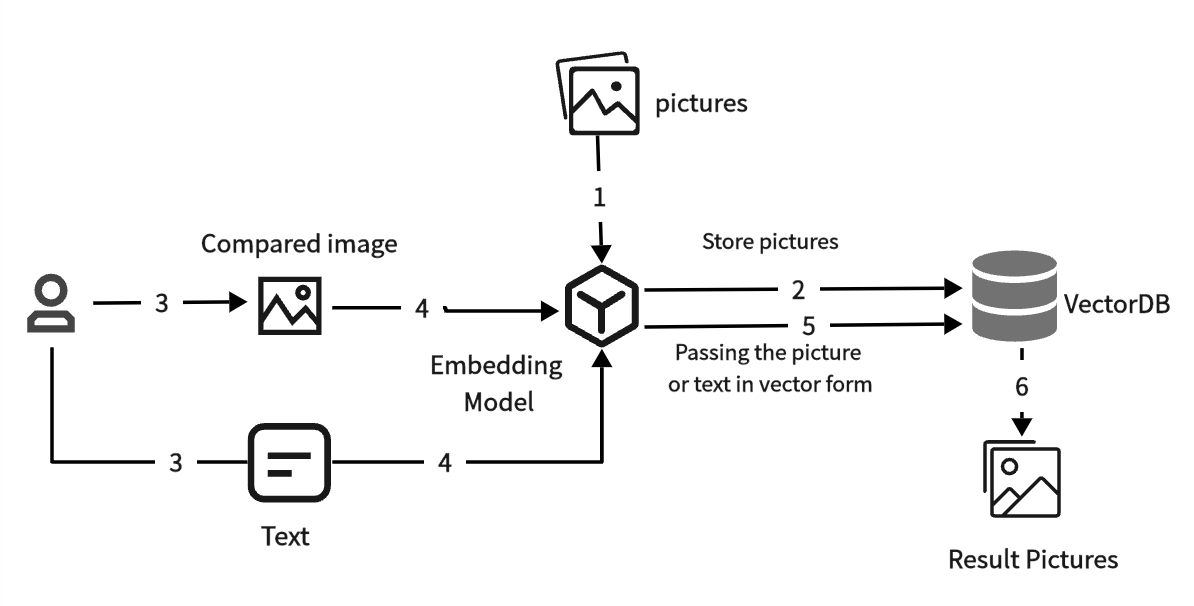
可以看到,在构建以图(文)搜图应用中,涉及到对图片的向量化存储和检索,而 MatrixOne 具备向量能力,且提供多种检索方式,这为构建以图(文)搜图应用提供了关键的技术支持。
在本章节,我们将基于 MatrixOne 的向量能力结合 Streamlit 来构建一个简单的以图(文)搜图的 Web 应用。
开始前准备
相关知识
Transformers:Transformers 是一个开源的自然语言处理库,提供了广泛的预训练模型,通过 Transformers 库,研究人员和开发者可以轻松地使用和集成 CLIP 模型到他们的项目中。
CLIP: CLIP 模型是由 OpenAI 发布的一种深度学习模型,核心是通过对比学习的方法来统一处理文本和图像,从而能够通过文本 - 图像相似度来完成图像分类等任务,而无需直接优化任务。它可以结合向量数据库,来构建以图(文)搜图的工具。通过 CLIP 模型提取图像的高维向量表示,以捕获其语义和感知特征,然后将这些图像编码到嵌入空间中。在查询时,样本图像通过相同的 CLIP 编码器来获取其嵌入,执行向量相似性搜索以有效地找到前 k 个最接近的数据库图像向量。
Streamlit: 是一个开源的 Python 库,专门用于快速构建交互式和数据驱动的 Web 应用。它的设计目标是简单易用,开发者可以用极少的代码创建互动式的仪表盘和界面,尤其适用于机器学习模型的展示和数据可视化。
软件安装
在你开始之前,确认你已经下载并安装了如下软件:
-
确认你已完成单机部署 MatrixOne。
-
确认你已完成安装 Python 3.8(or plus) version。使用下面的代码检查 Python 版本确认安装成功:
python3 -V
-
确认你已完成安装 MySQL 客户端。
-
下载安装
pymysql工具。使用下面的代码下载安装pymysql工具:
pip install pymysql
- 下载安装
transformers库。使用下面的代码下载安装transformers库:
pip install transformers
- 下载安装
Pillow库。使用下面的代码下载安装Pillow库:
pip install pillow
- 下载安装
streamlit库。使用下面的代码下载安装Pillow库:
pip install streamlit
构建应用
建表并开启向量索引
连接 MatrixOne,建立一个名为 pic_tab 的表来存储图片路径信息和对应的向量信息。
create table pic_tab(pic_path varchar(200), embedding vecf64(512));
SET GLOBAL experimental_ivf_index = 1;
create index idx_pic using ivfflat on pic_tab(embedding) lists=3 op_type "vector_l2_ops"
构建应用
创建 python 文件 pic_search_example.py,写入以下内容。该脚本主要是利用 CLIP 模型提取图像的高维向量表示,然后存到 MatrixOne 中。在查询时,样本图像通过相同的 CLIP 编码器来获取其嵌入,执行向量相似性搜索以有效地找到前 k 个最接近的数据库图像向量。
import streamlit as st
import pymysql
from PIL import Image
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
from transformers import CLIPProcessor, CLIPModel
import os
from tqdm import tqdm
# Database connection
conn = pymysql.connect(
host='127.0.0.1',
port=6001,
user='root',
password="111",
db='db1',
autocommit=True
)
cursor = conn.cursor()
# Load model from HuggingFace
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
# Traverse image path
def find_img_files(directory):
img_files = []
for root, dirs, files in os.walk(directory):
for file in files:
if file.lower().endswith('.jpg'):
full_path = os.path.join(root, file)
img_files.append(full_path)
return img_files
# Map image to vector and store in MatrixOne
def storage_img(jpg_files):
for file_path in tqdm(jpg_files, total=len(jpg_files)):
image = Image.open(file_path)
if image.mode != 'RGBA':
image = image.convert('RGBA')
inputs = processor(images=image, return_tensors="pt", padding=True)
img_features = model.get_image_features(inputs["pixel_values"])
img_features = img_features.detach().tolist()
embeddings = img_features[0]
insert_sql = "INSERT INTO pic_tab(pic_path, embedding) VALUES (%s, normalize_l2(%s))"
data_to_insert = (file_path, str(embeddings))
cursor.execute(insert_sql, data_to_insert)
image.close()
def create_idx(n):
create_sql = 'create index idx_pic using ivfflat on pic_tab(embedding) lists=%s op_type "vector_l2_ops"'
cursor.execute(create_sql, n)
# Image-to-image search
def img_search_img(img_path, k):
image = Image.open(img_path)
inputs = processor(images=image, return_tensors="pt")
img_features = model.get_image_features(**inputs)
img_features = img_features.detach().tolist()
img_features = img_features[0]
query_sql = "SELECT pic_path FROM pic_tab ORDER BY l2_distance(embedding, normalize_l2(%s)) ASC LIMIT %s"
data_to_query = (str(img_features), k)
cursor.execute(query_sql, data_to_query)
return cursor.fetchall()
# Text-to-image search
def text_search_img(text, k):
inputs = processor(text=text, return_tensors="pt", padding=True)
text_features = model.get_text_features(inputs["input_ids"], inputs["attention_mask"])
embeddings = text_features.detach().tolist()
embeddings = embeddings[0]
query_sql = "SELECT pic_path FROM pic_tab ORDER BY l2_distance(embedding, normalize_l2(%s)) ASC LIMIT %s"
data_to_query = (str(embeddings), k)
cursor.execute(query_sql, data_to_query)
return cursor.fetchall()
# Show results
def show_img(result_paths):
fig, axes = plt.subplots(nrows=1, ncols=len(result_paths), figsize=(15, 5))
for ax, result_path in zip(axes, result_paths):
image = mpimg.imread(result_path[0]) # Read image
ax.imshow(image) # Display image
ax.axis('off') # Remove axes
ax.set_title(result_path[0]) # Set subtitle
plt.tight_layout() # Adjust subplot spacing
st.pyplot(fig) # Display figure in Streamlit
# Streamlit interface
st.title("Image and Text Search Application")
# Prompt for local directory path input
directory_path = st.text_input("Enter the local image directory")
# Once user inputs path, search for images in the directory
if directory_path:
if os.path.exists(directory_path):
jpg_files = find_img_files(directory_path)
if jpg_files:
st.success(f"Found {len(jpg_files)} images in the directory.")
if st.button("uploaded"):
storage_img(jpg_files)
st.success("Upload successful!")
else:
st.warning("No .jpg files found in the directory.")
else:
st.error("The specified directory does not exist. Please check the path.")
# Image upload option
uploaded_file = st.file_uploader("Upload an image for search", type=["jpg", "jpeg", "png"])
if uploaded_file is not None:
# Display uploaded image
img = Image.open(uploaded_file)
st.image(img, caption='Uploaded image', use_column_width=True)
# Perform image-to-image search
if st.button("Search by image"):
result = img_search_img(uploaded_file, 3) # Image-to-image search
if result:
st.success("Search successful. Results are displayed below:")
show_img(result) # Display results
else:
st.error("No matching results found.")
# Text input for text-to-image search
text_input = st.text_input("Enter a description for search")
if st.button("Search by text"):
result = text_search_img(text_input, 3) # Text-to-image search
if result:
st.success("Search successful. Results are displayed below:")
show_img(result) # Display results
else:
st.error("No matching results found.")
代码解读:
- 通过 pymysql 连接到本地的 MatrixOne 数据库,用于插入图像特征和查询相似照片。
- 使用 HuggingFace 的 transformers 库,加载 OpenAI 预训练的 CLIP 模型(clip-vit-base-patch32)。该模型支持同时处理文本和图像,将它们转化为向量,以便进行相似性计算。
- 定义方法 find_img_files 遍历本地图片文件夹,这里我预先在本地存了苹果、香蕉、蓝莓、樱桃、杏子五种类别的水果图片,每种类别若干张,格式都为 jpg。
- 存储图片特征到数据库,使用 CLIP 模型提取图像的嵌入向量,将图像路径及嵌入向量存储在数据库的 pic_tab 表中。
- 定义方法 img_search_img 和 text_search_img 实现以图搜图和以文搜图,MatrixOne 具有向量检索能力,支持多种相似度搜索,在这里我们使用欧几里得距离来检索。
- 展示图片结果,使用 matplotlib 展示从数据库查询到的图片路径,并在 Streamlit 的 Web 界面上展示。
运行结果
streamlit run pic_search_example.py