MatrixOne 架构设计
MatrixOne 概述
MatrixOne 是一款面向未来的超融合异构云原生数据库,通过简化的分布式数据库引擎,跨多个数据中心、云、边缘和其他异构基础设施,同时支持事务性(OLTP)、分析性(OLAP)和流式工作(Sreaming)负载,这种多种引擎的融合,称为 HSTAP。
MatrixOne HSTAP 数据库对 HTAP 数据库进行了重新定义,HSTAP 旨在满足单一数据库内事务处理(TP)和分析处理(AP)的所有需求。与传统的 HTAP 相比,HSTAP 强调其内置的用于连接 TP 和 AP 表数据流处理能力,为用户提供了数据库可以像大数据平台一样灵活的使用体验。也恰恰得益于大数据的繁荣,很多用户已经熟悉了这种体验。用户使用 MatrixOne 只需要少量的集成工作,即可以获得覆盖整个 TP 和 AP 场景的一站式体验,同时可以摆脱传统大数据平台的臃肿架构及各种限制。
MatrixOne 架构
MatrixOne 架构如下如所示:
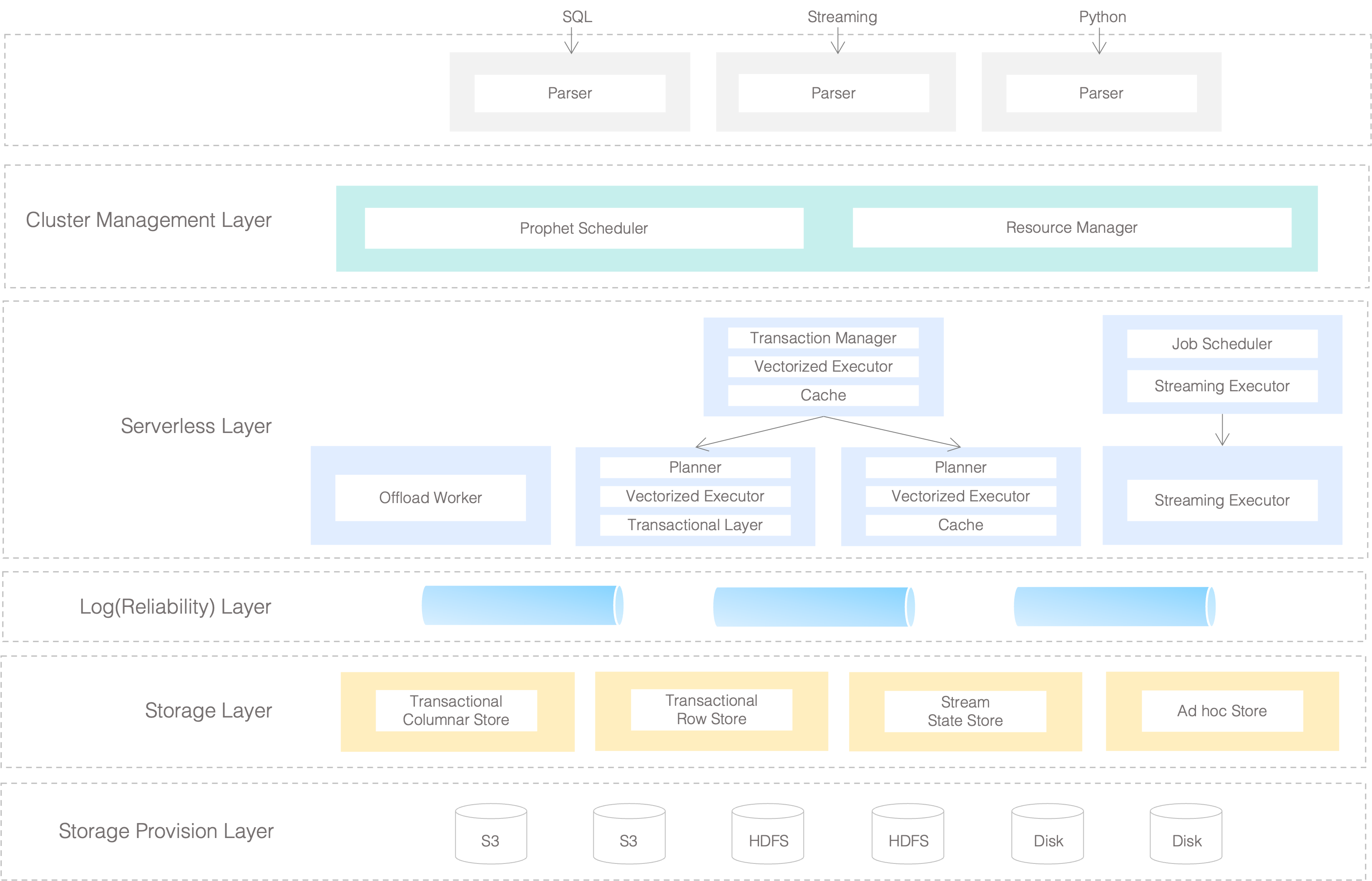
参照上面的图示,MatrixOne 的体系结构分为五层,以下内容是从上至下对每层的介绍:
集群管理层
这一层负责集群管理,在云原生环境中与 Kubernetes 交互动态获取资源;在本地部署时,根据配置获取资源。集群状态持续监控,根据资源信息分配每个节点的任务。提供系统维护服务以确保所有系统组件在偶尔出现节点和网络故障的情况下正常运行,并在必要时重新平衡节点上的负载。集群管理层的主要组件是:
- Prophet 调度:提供负载均衡和节点 Keep-alive。
- 资源管理:提供物理资源。
Serverless 层
Serverless 层是一系列无状态节点的总称,整体上包含三类:
- 后台任务:最主要的功能是 Offload Worker,负责卸载成本高的压缩任务,以及将数据刷新到 S3 存储。
- SQL 计算节点:负责执行 SQL 请求,这里分为写节点和读节点,写节点还提供读取最新数据的能力。
- 流任务处理节点:负责执行流处理请求。
日志层
作为 MatrixOne 的单一数据源 (即 Single source of truth),数据一旦写入日志层,则将永久地存储在 MatrixOne 中。它建立在我们世界级的复制状态机模型的专业知识之上,以保证我们的数据具有最先进的高吞吐量、高可用性和强一致性。它本身遵循完全模块化和分解的设计,也帮助解耦存储和计算层的核心组件,与传统的 NewSQL 架构相比,我们的架构具有更高的弹性。
存储层
存储层将来自日志层的传入数据转换为有效的形式,以供将来对数据进行处理和存储。包括为快速访问已写入 S3 的数据进行的缓存维护等。在 MatrixOne 中,TAE(即 Transactional Analytic Engine)是存储层的主要公开接口,它可以同时支持行和列存储以及事务处理能力。此外,存储层还包括其他内部使用的存储功能,例如流媒体的中间存储。
存储供应层
作为与基础架构解耦的 DBMS,MatrixOne 可以将数据存储在 S3/HDFS、本地磁盘、本地服务器、混合云或其他各类型云,以及智能设备的共享存储中。存储供应层通过为上层提供一个统一的接口来访问这些多样化的存储资源,并且不向上层暴露存储的复杂性。
MatrixOne 系统组件
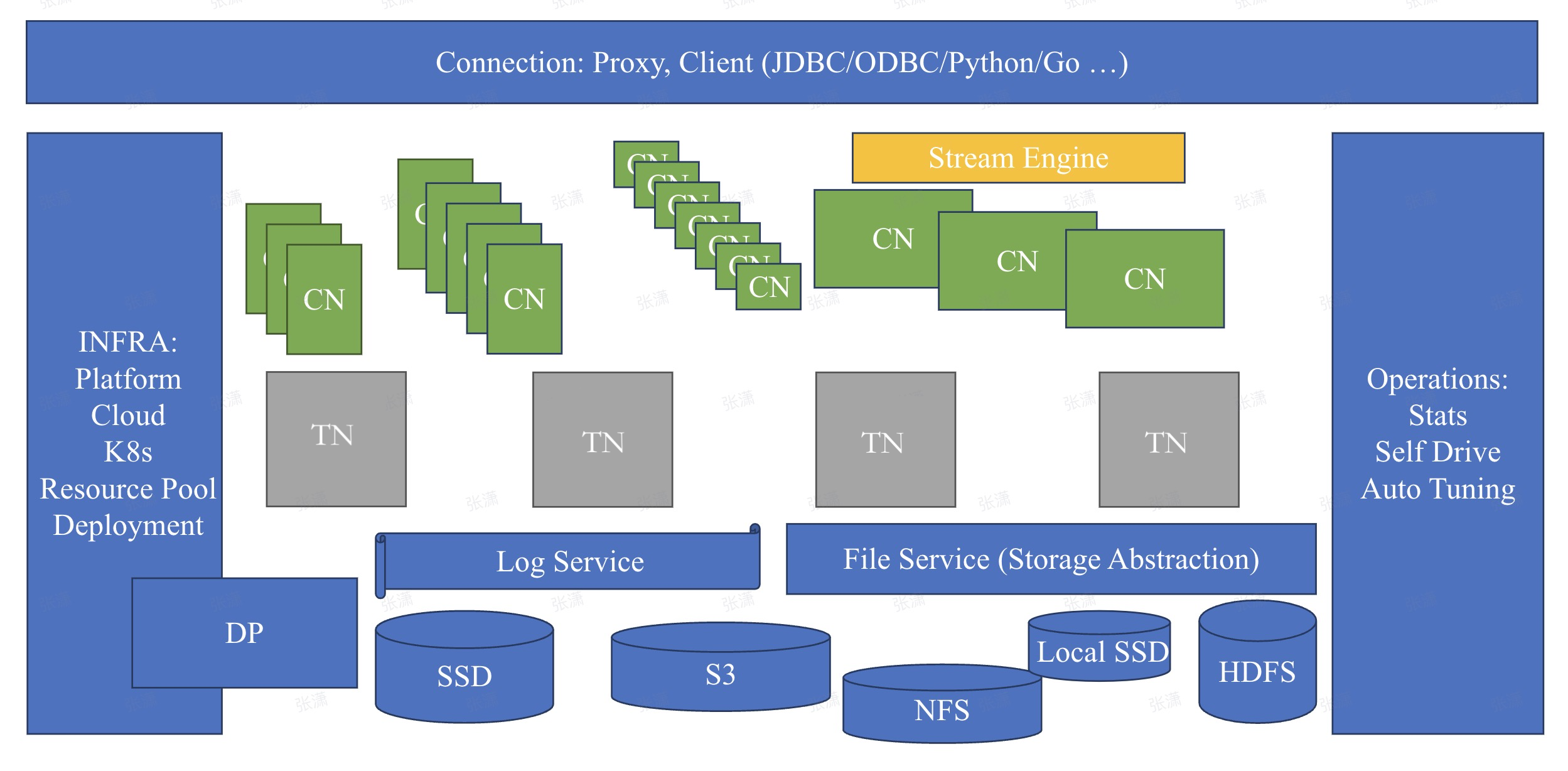
在 MatrixOne 中,为实现分布式与多引擎的融合,构建了多种不同的系统组件用于完成架构相关的层级的功能:
File Service
File Service 是 MatrixOne 负责所有存储介质读写的组件。存储介质包括内存、磁盘、对象存储等,它提供了如下特性:
- File Service 提供了一个统一的接口,使不同介质的读写,可以使用相同的接口。
- 接口的设计,遵循了数据不可变的理念。文件写入之后,就不允许再更新。数据的更新,通过产生新的文件来实现。
- 这样的设计,简化了数据的缓存、迁移、校验等操作,有利于提高数据操作的并发能力。
- 基于统一的读写接口,File Service 提供了分级的缓存,提供了灵活的缓存策略,以平衡读写速度和容量。
Log Service
Log Service 是 MatrixOne 中专门用于处理事务日志的组件,它具有如下功能特性:
- 采用 Raft 协议来保证一致性,采用多副本方式确保可用性。
- 保存并处理 MatrixOne 中所有的事务日志,在事务提交前确保 Log Service 的日志读写正常,在实例重启时,检查并回放日志内容。
- 在完成事务的提交与落盘后,对 Log Service 内容做截断,从而控制 Log Service 的大小,截断后仍然保留在 Log Service 中的内容,称为 Logtail。
- 如果多个 Log Service 副本同时出现宕机,那么整个 MatrixOne 将会发生宕机。
Database Node
Database Node(DN),是用来运行 MatrixOne 的分布式存储引擎 TAE 的载体,它提供了如下特性:
- 管理 MatrixOne 中的元数据信息以及 Log Service 中保存的事务日志内容。
- 接收 Computing Node(CN) 发来的分布式事务请求,对分布式事务的读写请求进行裁决,将事务裁决结果推给 CN,将事务内容推给 Log Service,确保事务的 ACID 特性。
- 在事务中根据检查点生成快照,确保事务的快照隔离性,在事务结束后将快照信息释放。
Computing Node
Computing Node(CN),是 Matrixone 接收用户请求并处理 SQL 的组件,具体包括以下模块:
- Frontend,处理客户端 SQL 协议,接受客户端发送的 SQL 报文,然后解析得到 MatrixOne 可执行的 SQL,调用其他模块执行 SQL 后将查询结果组织成报文返回给客户端。
- Plan,解析 Frontend 处理后的 SQL,并根据 MatrixOne 的计算引擎生成逻辑执行计划发送给 Pipeline。
- Pipeline,解析逻辑计划,将逻辑计划转成实际的执行计划,然后 Pipeline 运行执行计划。
- Disttae,负责具体的读写任务,既包含了从 DN 同步 Logtail 和从 S3 读取数据,也会把写入的数据发送给 DN。
Stream Engine
Stream Engine 是一个新组件,用于简化从 OLTP 到 OLAP 的 ETL 处理过程。Stream Engine 还处在 MatrixOne 开发过程中,暂尚未实现。
MatrixOne 特性
在 MatrixOne 版本 0.7 中,具有如下特性,让你在使用 MatrixOne 的过程中更加高效:
分布式架构
在 MatrixOne 中,采用了的分布式存算分离的分布式架构,存储层、数据层、计算层的分离,使得 MatrixOne 在遇到系统资源瓶颈时,能够灵活实现节点的扩容。同时,多节点的架构下,资源可以进行更加有效率地分配,一定程度上避免了热点与资源征用。
事务与隔离
在 MatrixOne 中,事务采用了乐观事务与快照隔离。
在分布式架构下,乐观事务可以通过较少的冲突获得更优的性能。同时在实现方式上,能够实现隔离级别更高的快照隔离。为了保证事务的 ACID 四个要素,MatrixOne 目前支持且仅支持快照隔离一种隔离级别。该隔离级别较常见的读已提交相比,隔离级别更加严格,既可以有效防止脏读,又能够更好地适配分布式乐观事务。
云原生
MatrixOne 是一款云原生的数据库,从存储层,适配本地磁盘、AWS S3、NFS 等多种存储方式,通过 File service 实现了对多种不同类型存储的无感知管理。MatrixOne 集群可以在多种基础设施环境下稳定运行,既可以适配企业私有云,又可以在不同的公有云厂商环境下提供服务。
相关信息
本节介绍了 MatrixOne 的整体架构概览。其他信息可参见: