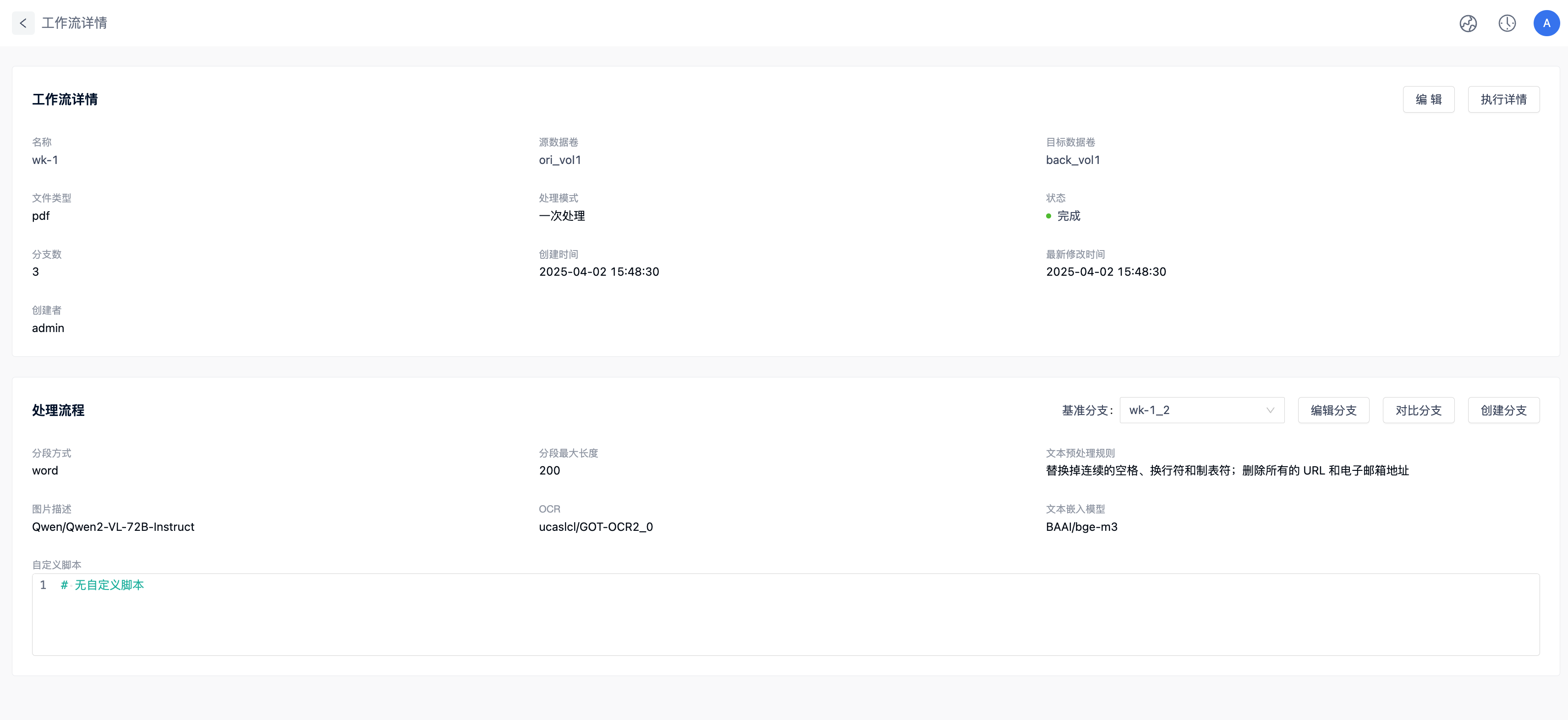
工作流
工作流功能是 MatrixOne Intelligence 的核心特性之一,支持用户通过可视化方式定义和执行复杂的数据处理任务。
工作流创建
进入工作区,依次点击数据处理 > 工作流> 创建工作流,根据实际需求填写信息完成工作流创建。系统支持智能创建和手动创建两种模式,其中智能创建可通过自然语言快速生成工作流。
基础配置
| 配置项 | 说明 |
|---|---|
| 源数据 | 输入数据存储位置 |
| 目标位置 | 处理结果输出路径,不能选择已被占用的目标位置。 |
| 文件类型 | 支持格式: • 文档:doc/docx/ppt/pptx/txt/md/pdf/htm/html/xlsx/xls/csv • 图像:jpg/jpeg/bmp/png • 视频:mp4/mov/mkv • 音频:mav/mp3/aac/flac |
| 优先级 | 选项包括“低”、“中”和“高”,默认值为“中”。设置后,新的工作流作业将根据该优先级即时生效。当多个工作流并发执行时,平台将按照优先级从高到低的顺序依次调度执行。 |
| 处理模式 | 支持: • 单次处理:任务触发后仅运行一次 • 周期处理:调度周期:1/5/10/30 分钟、1/2/4/8 小时、1 天(默认 5 分钟),短周期(<1 天):整点触发(如 30 分钟周期在 00/30 分执行),长周期(≥1 天):需手动设置下次执行时间。 •载入触发:当相同原始卷中数据载入任务完成一批文件载入后,会立即执行工作流处理这些文件。 |
| 处理范围 | “一次处理”模式支持按文件类型或文件粒度处理。仅当选择单个源数据时,可启用文件粒度选项。 |
| 分支名 | 当前工作流分支的名称,默认是“主要“ |
处理流程配置
支持多种处理算子,包括:文档解析节点、图片解析节点、音频解析节点、视频解析节点、分段节点、文本嵌入节点、信息提取节点、数据清洗节点和数据增强节点。
文档解析节点
对文档进行内容识别,目前支持解析文本、图片、表格、标题这几类结构信息。
| 模块 | 功能说明 |
|---|---|
| 节点名称 | 100 字符以内,工作流内唯一。 |
| 图片描述 | 基于 Qwen/Qwen2-VL-72B-Instruct 模型生成图片内容描述,支持选择描述的语言:中文/英文 |
| PPT 多模态解析 | 开启后会将 PPT 中的每一页转为图片处理 |
| CSV 设置 | 支持配置分隔符、定界符、反斜杠转义和是否启用第一行作为表名。 |
| OCR 识别 | 采用 ucaslcl/GOT-OCR2_0 模型提取图像文字 |
| 说明 | 节点备注 |

图片解析节点
识别图片中的文字与视觉内容,实现图像内容的结构化理解。
| 模块 | 功能说明 |
|---|---|
| 节点名称 | 100 字符以内,工作流内唯一。 |
| 图片描述 | 基于 Qwen/Qwen2-VL-72B-Instruct 模型生成图片内容描述,支持选择描述的语言:中文/英文 |
| OCR 识别 | 采用 ucaslcl/GOT-OCR2_0 模型提取图像文字 |
| 说明 | 节点备注 |
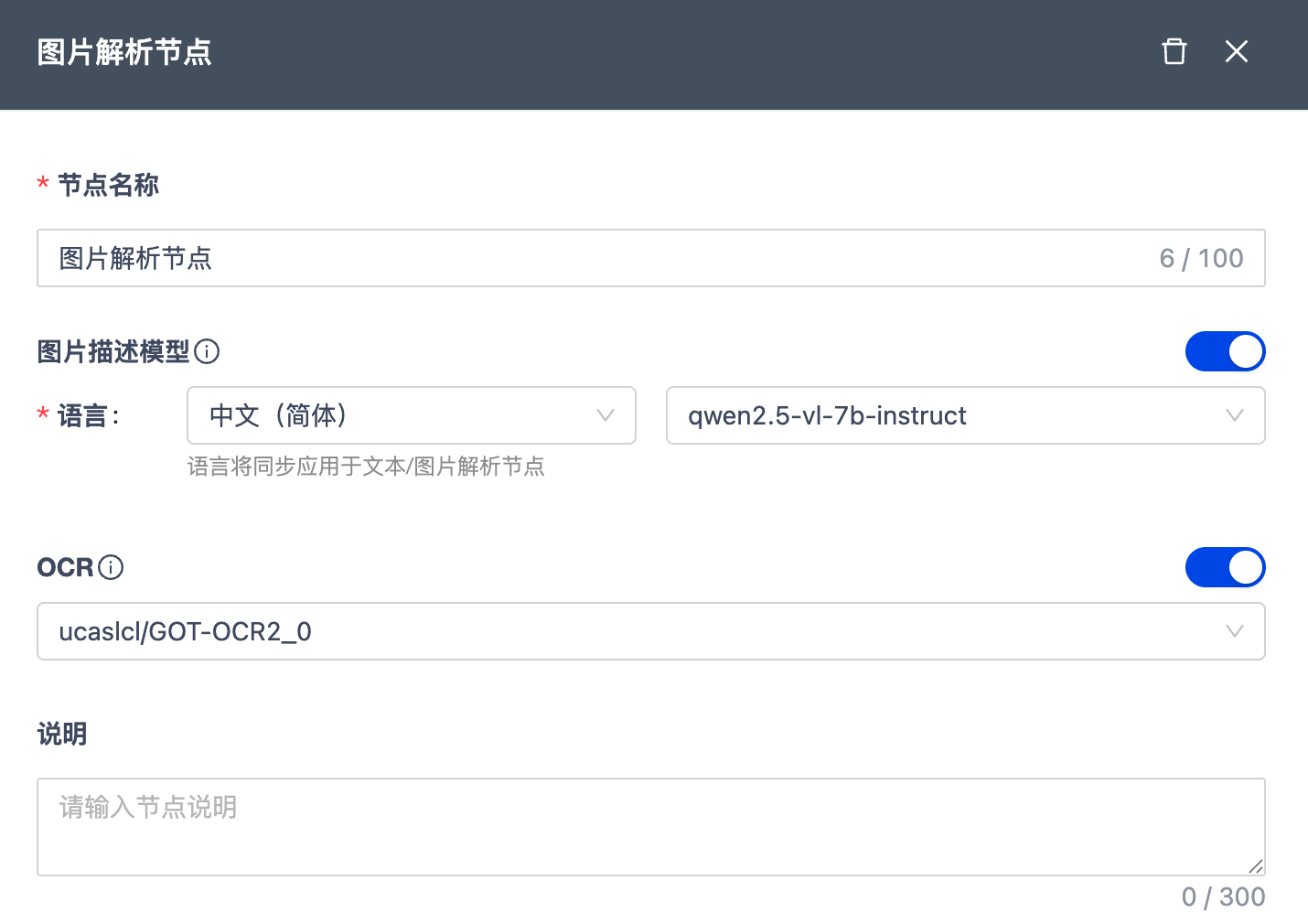
音频解析节点
将语音内容高精度转写为文本,为后续处理提供文本输入。
| 模块 | 功能说明 |
|---|---|
| 节点名称 | 100 字符以内,工作流内唯一。 |
| 降噪 | 开启降噪可显著提升信噪比和识别准确率,但会增加计算开销并可能丢失部分语音细节。 |
| 语音切片 | •使用 VAD(语音活动检测)自动识别音频中的人声片段与静音/噪声片段,实现智能切分。 •最小静音间隔:指 VAD 将语音切片时,判断一段语音结束并与下一段语音分隔开的最短静音时长。默认为 0.5s,范围值为 0.1s-2s •最大语音时长:指 VAD 将语音切片时,判断一段语音结束并与下一段语音分隔开的最短静音时长。默认为 30s,范围值为 5-60s |
| 语音模型 | 采用 SenseVoice 模型进行自动语音识别(ASR)转写。 |
| 说明 | 节点备注 |
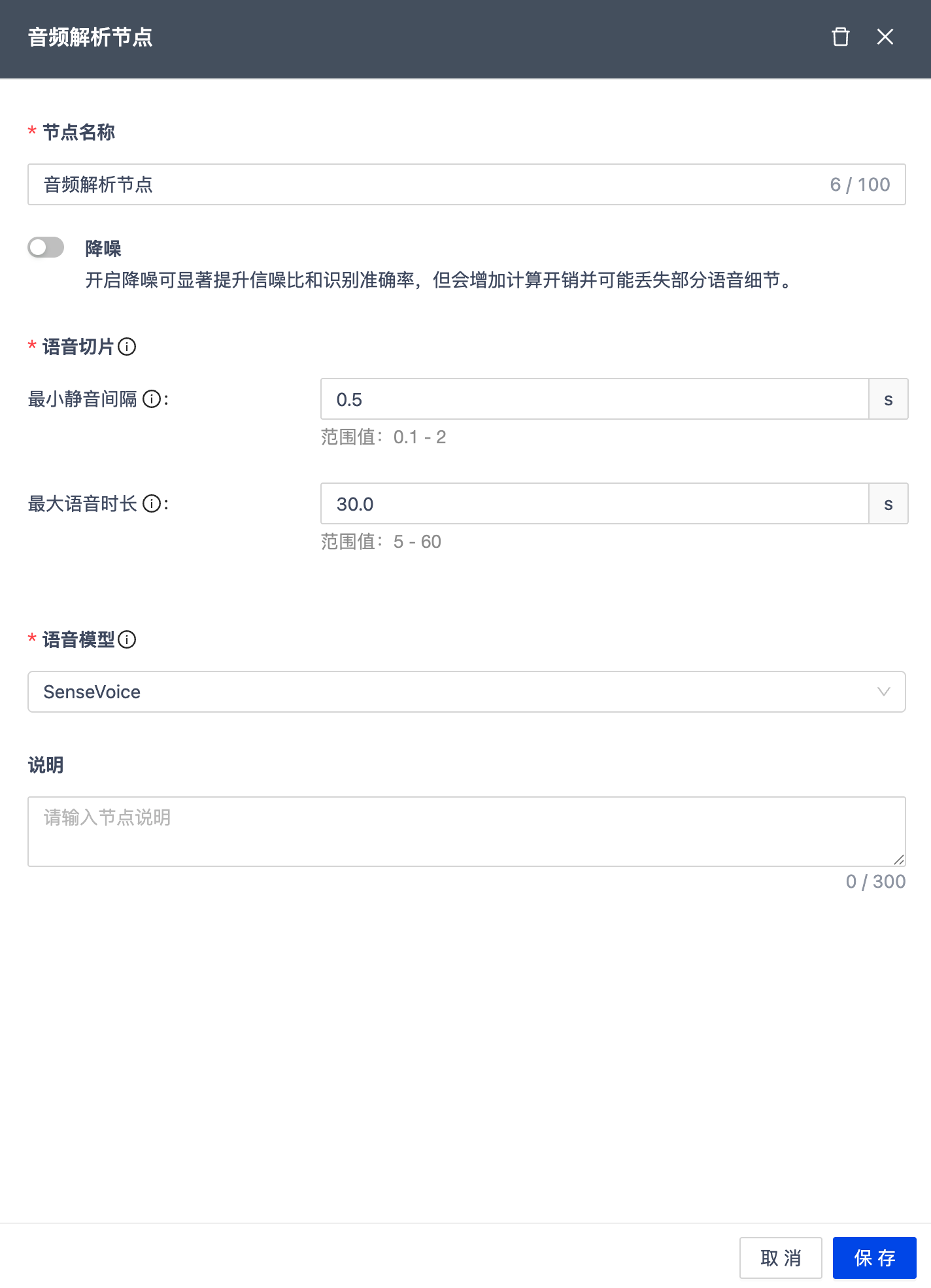
视频解析节点
将视频中的音频分离出来,将语音内容转写为文本,为后续处理提供文本输入。
| 模块 | 功能说明 |
|---|---|
| 节点名称 | 100 字符以内,工作流内唯一。 |
| 降噪 | 开启降噪可显著提升信噪比和识别准确率,但会增加计算开销并可能丢失部分语音细节。 |
| 语音切片 | •使用 VAD(语音活动检测)自动识别音频中的人声片段与静音/噪声片段,实现智能切分。 •最小静音间隔:指 VAD 将语音切片时,判断一段语音结束并与下一段语音分隔开的最短静音时长。默认为 0.5s,范围值为 0.3s-3s •最大语音时长:指 VAD 将语音切片时,判断一段语音结束并与下一段语音分隔开的最短静音时长。默认为 30s,范围值为 10-180s |
| 语音模型 | 采用 SenseVoice 模型进行自动语音识别(ASR)转写。 |
| 说明 | 节点备注 |
分段节点
按规则对文本进行自动分段。
| 模块 | 功能说明 |
|---|---|
| 节点名称 | 100 字符以内,工作流内唯一。 |
| 文档 | 通用文档: 文本: •分段方式:按单个标志符分段、按多个标志符分段 • 分段最大长度:100-2000(默认 1024) • 分段重叠:不超过设置的字段分段长度 100 字符以内,工作流内唯一。 图片: •上下文重叠:默认 50。 表格: •上下文重叠:默认 50。 表格:Excel,CSV 按行分段 |
| 图片 | 图片元素合并:ocr 识别内容和图片描述内容合并作为一个单独的分段。 |
| Excel,CSV 按行分段 | |
| 音频/视频 | 按转写后的语音块分段,支持设置分段最大长度,默认 1024。 |
| 节点名称 | 100 字符以内,工作流内唯一。 |
文本嵌入节点
将文本转化为语义向量,捕捉深层语义关系,支持智能理解与检索。
| 模块 | 功能说明 |
|---|---|
| 节点名称 | 100 字符以内,工作流内唯一。 |
| 文本嵌入 | 通过 BAAl/bge-m3 模型生成文本向量 |
| 说明 | 节点备注 |
信息提取节点
信息提取节点通过结合 AI 模型能力与预设字段规则,自动从文本中提取关键信息。
| 模块 | 功能说明 |
|---|---|
| 节点名称 | 100 字符以内,工作流内唯一,默认为节点类型名称。 |
| 提取结果 | •每个文件单独生成结果:对工作流输入的每个文件独立提取信息,并分别生成对应的 JSON 结果文件。 •所有文件共同生成一个结果:将工作流输入的所有文件作为整体处理,从全部文件中查找并整合所需信息,最终仅生成一个合并后的 JSON 结果文件。 |
| 提取模型 | 支持接入大语言模型(Qwen-Turbo)和多模态模型(Qwen/Qwen2.5-VL-32B-Instruct)进行字段提取。当选择多模态模型时,可在工作流中直接连接至开始节点,直接处理包含文档与图片的文件 (暂不支持直接处理 htm/html/xlsx/xls/csv 格式文件),无需经过额外的解析节点,token 不能超过 128k。 |
| 提取信息 | 默认内置三种字段提取模版:财务报表(含表格)、发票 和 简历。同时支持通过表单方式自定义配置字段,系统将根据字段的名称、类型、含义及是否必填,自动生成对应的 JSON Schema。支持最多 4 层嵌套结构,字段数量上限为 40 个。配置过程中可随时切换至 JSON 预览模式,直观查看系统生成的实际 Schema 内容。 |
| 说明 | 节点备注 |
Note
在进行信息提取时,建议根据文件类型和内容结构选择合适的模型:若文件为结构清晰的文本(如解析后的 PDF、Word、TXT 等),推荐使用大语言模型,其具备出色的语义理解与字段推理能力,适用于逻辑复杂、字段间关联强的场景;若文件为原始 PDF、图像或扫描件,推荐使用多模态模型,可直接识别图文混排内容,无需额外解析步骤,更适用于格式复杂或含图表、票据类文档的提取需求。选择合适模型有助于提升提取准确率与处理效率。
数据类型选取
信息提取节点支持以下数据类型:object、string、boolean、number、array/string、array/boolean、array/number、array/object。 选择合适的数据类型有助于提升提取准确率与后续流程处理效率。
基础类型
-
string(字符串):适用于文本型字段,内容通常不需要数值运算。例如单个名称、标题、编号、描述类字段,地址、备注、说明信息,单个日期等。示例:
- 客户公司:“xxx 有限公司”
- 发票代码:“1234567890”
- 出生日期:“1990-05-13”
-
number(数字):适用于可用于计算或比较的数值类型字段。例如金额、数量、百分比、税率,年限、次数、工龄等整数信息。示例:
- 金额:12345.67
- 税率:0.13
- 库存数量:150
-
boolean(布尔):用于二值判断,只有“是/否”“true/false”这类答案。例如是否通过审核、是否含税、是否在职等。示例:
- is_active: true
- is_tax_included: false
-
object(对象结构):用于结构化数据,一个字段内部包含多个子字段。适用于复杂实体或字段组。例如地址对象(省、市、区、详细地址),发票信息对象(发票号 + 开票日期 + 金额),简历中“教育经历”“工作经历”中的单个经历条目等。示例:
{
"company": "矩阵起源",
"position": "工程师",
"start_date": "2020-01",
"end_date": "2023-01"
}
数组类型
- array/string(字符串数组):用于一个字段中可能有多个文本值的情况。例如技能列表(如简历),多个标签,多个收件人、多个科目名等。示例:
[“Java”, “Python”, “SQL”]
- array/number(数字数组):用于多个数值型项的情况。例如多期间的金额列表,多个评分,数字型属性集合等。示例:
[95, 88, 76]
- array/boolean(布尔数组):适用于多个布尔字段组合。例如多维权限标识、每日是否出勤(true/false 列表)等。示例:
[true, false, true]
- array/object(对象数组):最常用的复合结构之一,用于包含多个类似对象的列表。当文本中存在重复结构时选它。例如简历中的多段工作经历、教育经历,发票中的多条明细项(品名、数量、单价、金额),财务报表中的多行科目,报表中多条交易记录等。示例:
[
{
"item": "商品 A",
"quantity": 2,
"price": 100
},
{
"item": "商品 B",
"quantity": 1,
"price": 200
}
]
总结:
| 类型 | 使用场景 |
|---|---|
| string | 单个文本字段(名称、编号、日期、描述等) |
| number | 金额、数量、比率、数值计算字段 |
| boolean | 是否类字段(是/否、true/false) |
| object | 一个字段包含多个子字段,结构化实体 |
| array/string | 多个文本项(技能、标签、科目名列表) |
| array/number | 数字集合(多期金额、评分列表) |
| array/boolean | 多布尔项(如每日出勤表) |
| array/object | 多条结构化记录(工作经历、发票明细、报表行) |
数据清洗节点
自动识别并处理冗余、错误或不规范数据,提升数据准确性与一致性。
| 模块 | 功能说明 |
|---|---|
| 节点名称 | 100 字符以内,工作流内唯一,默认为节点类型名称。 |
| 敏感信息打码 | 默认关闭,去除文本块中电话、邮箱等敏感信息相关的内容 |
| 文本标准化 | 文本 Unicode 标准化和繁体转中文 |
| 特殊字符删除 | 支持去除 URL、去除不可见字符、去除 html 格式字符 |
| 特殊字符过滤 | 当文本中特殊字符的数量或比例超过设定阈值时,系统将自动对该文本块进行删除,从而保障数据质量 |
| 敏感词过滤 | 删除掉文本块中的敏感词语 |
| 数据去重 | 通过设置 N-Gram 重复比率过滤阈值基于文字重复比率对文本块中的重复数据进行去重 |
| 说明 | 节点备注 |
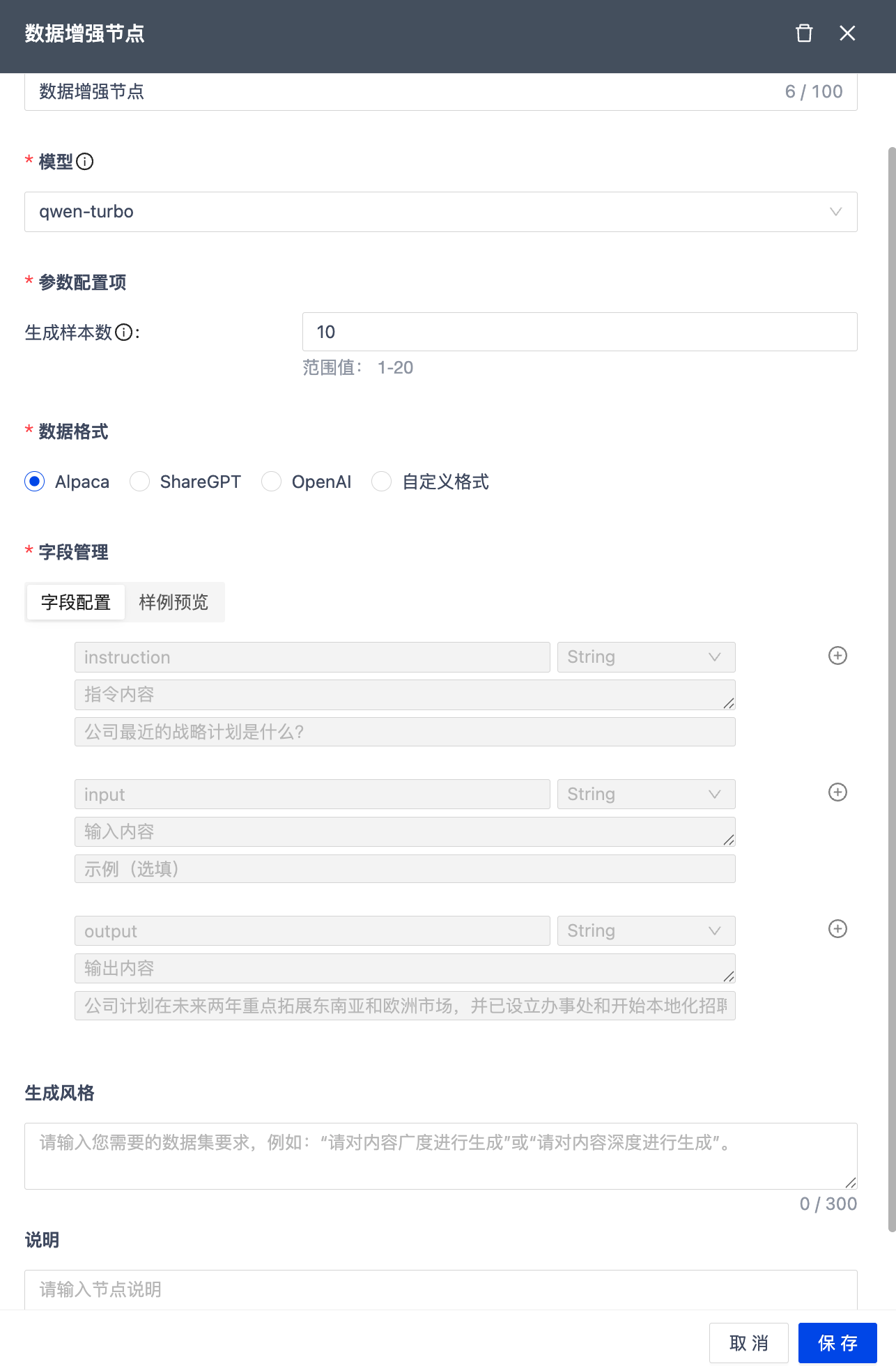
数据增强节点
| 模块 | 功能说明 |
|---|---|
| 节点名称 | 100 字符以内,工作流内唯一,默认为节点类型名称。 |
| 生成样本数 | 指定每个分段最大生成的样本数量,范围为 1-20,默认为 10 |
| 数据格式 | 支持 Alpaca、ShareGPT、OpenAI 及其扩展格式,同时兼容自定义数据格式。字段配置上限为 40 个,支持最多 4 层嵌套。 |
| 模型 | 采用 qwen-turbo 模型生成数据集 |
| 说明 | 节点备注 |
节点上下游关系
| 节点类型 | 支持上游节点 | 支持下游节点 |
|---|---|---|
| 开始节点 | 无 | •文档解析节点 • 图片解析节点 • 音频解析节点 • 视频解析节点 •信息提取节点 |
| 文档解析节点 | 开始节点 | • 信息提取节点 • 分段节点 • 结束节点 |
| 图片解析节点 | 开始节点 | • 信息提取节点 • 分段节点 • 结束节点 |
| 音频解析节点 | 开始节点 | • 信息提取节点 • 分段节点 • 结束节点 |
| 视频解析节点 | 开始节点 | • 信息提取节点 • 分段节点 • 结束节点 |
| 分段节点 | • 开始节点 • 文档解析节点 • 图片解析节点 • 音频解析节点 • 视频解析节点 |
• 文本嵌入节点 • 数据清洗节点 • 数据增强节点 • 结束节点 |
| 文本嵌入节点 | • 分段节点 | • 结束节点 |
| 信息提取节点 | • 开始节点 • 文档解析节点 • 图片解析节点 • 音频解析节点 • 视频解析节点 |
• 数据增强节点 • 结束节点 |
| 数据清洗节点 | • 文档解析节点 • 图片解析节点 • 音频解析节点 • 视频解析节点 • 分段节点 |
• 文本嵌入节点 • 数据增强节点 • 结束节点 |
| 数据增强节点 | • 数据清洗节点 • 分段节点 • 信息提取节点 |
• 结束节点 |
| 结束节点 | • 文档解析节点 • 图片解析节点 • 音频解析节点 • 视频解析节点 •分段节点 • 数据清洗节点 • 数据增强节点 • 信息提取节点 • 嵌入节点 |
无 |
分支管理
工作流分支管理功能旨在帮助数据工程师更高效地管理相似数据处理流程的不同版本,允许用户基于同一工作流创建多个分支版本,从而解决以下问题:
- 降低管理成本:避免重复创建相似工作流
- 优化资源使用:相同处理步骤仅执行一次,结果仅存储一份
- 简化对比:直观比较不同分支的流程和结果差异
工作流分支机制类似于 Git 仓库的分支概念,一个工作流可包含多个分支版本,默认拥有一个“主要”分支作为基础版本。各分支共享基础配置信息(如源数据卷、文件类型等),但可独立修改其处理流程,执行结果则按分支名称分别存储在目标数据卷的子目录中。
创建分支
进入到工作流列表,点击右侧的创建工作流分支按钮,来进行分支创建。需选择基准分支(默认 "主要" 分支),新分支初始处理流程与基准分支一致,分支名称需唯一且符合命名规范,删除所有分支等同于删除工作流。
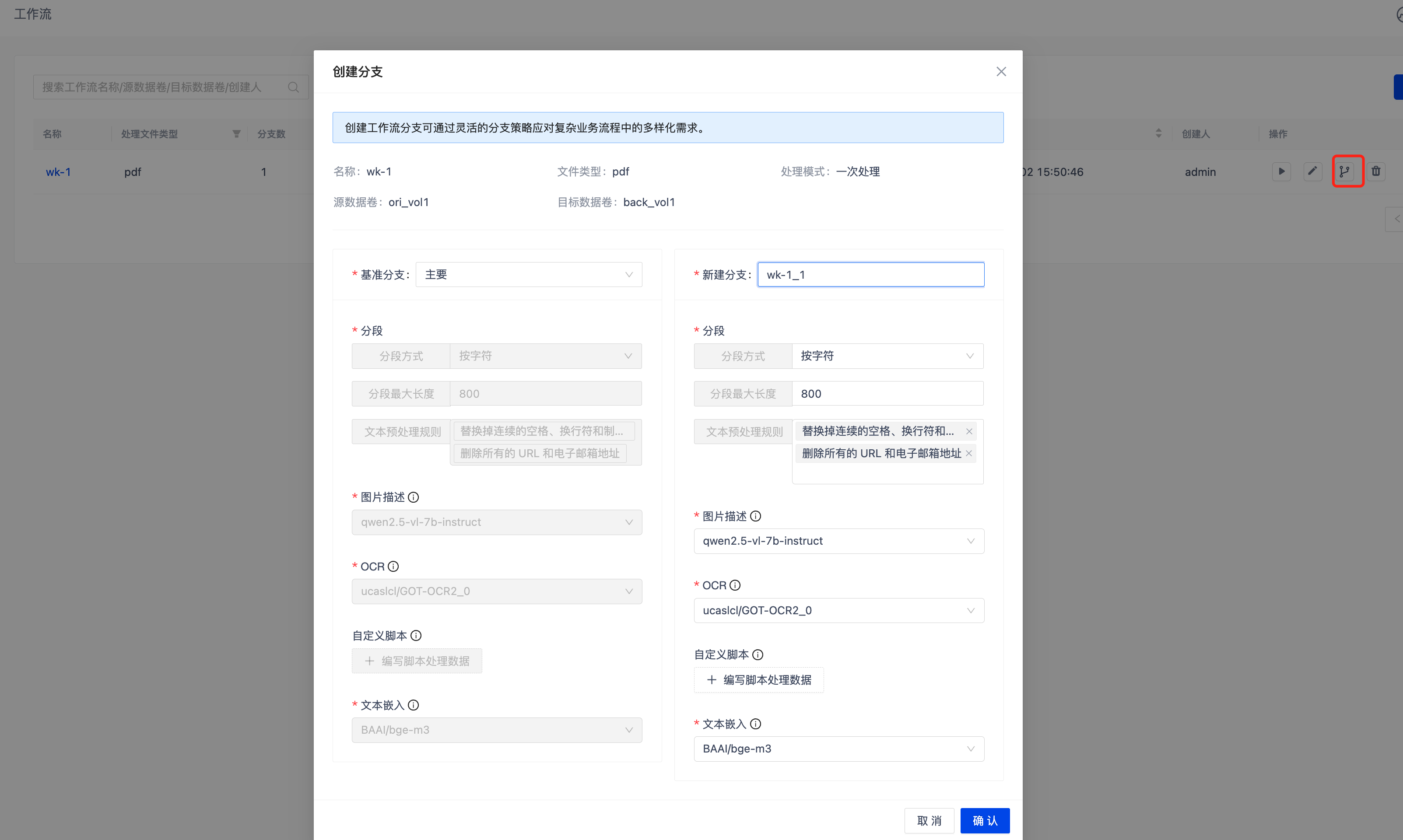
新分支创建时根据工作流状态决定是否立即执行,所有分支共享执行基础信息,相同处理步骤只执行一次(优化资源使用),工作流状态由所有分支共同决定,起停操作影响所有分支。
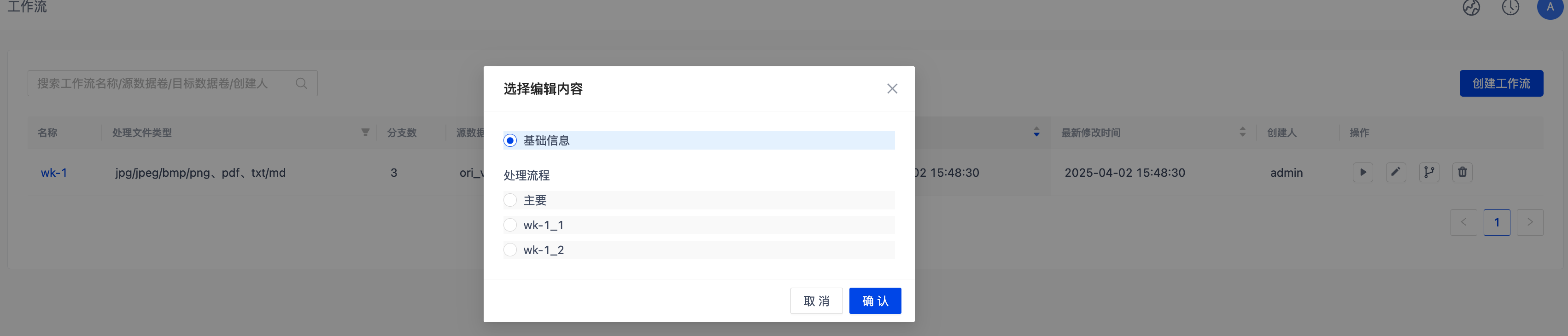
修改分支
- 仅停止状态的工作流可编辑
- 仅 "主要" 分支可修改基础配置,各分支可独立调整处理流程
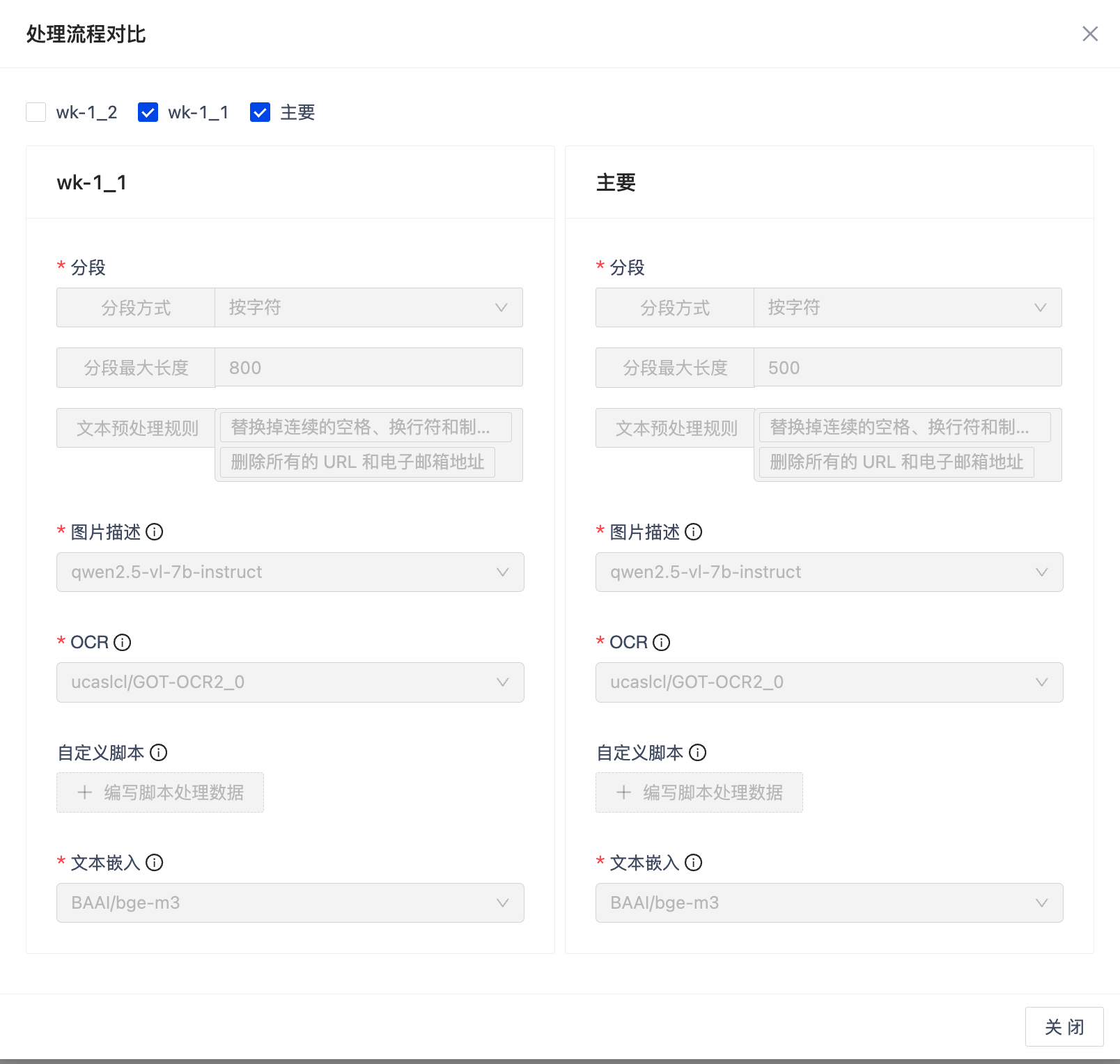
对比分支
默认包含 "主要" 分支,支持多选对比
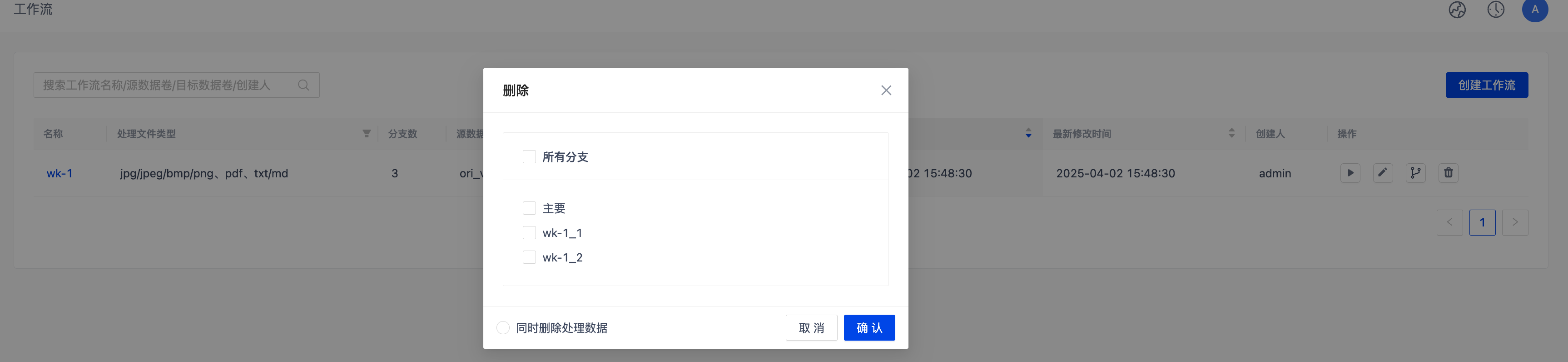
删除分支
- "主要" 分支不可单独删除
- 删除所有分支等同于删除工作流
- 可选择是否同时删除数据卷中的分支数据
工作流管理
在工作流列表可以对工作流进行管理,您可以选择重新运行工作流或者修改、删除工作流,删除所有分支等同于删除工作流。

点击工作流名称可以查看工作流详细信息,点击右上角编辑按钮可以修改并重新运行工作流,点击执行详情按钮查看作业情况。