使用 DataX 将数据写入 MatrixOne
概述
本文介绍如何使用 DataX 工具将数据离线写入 MatrixOne 数据库。
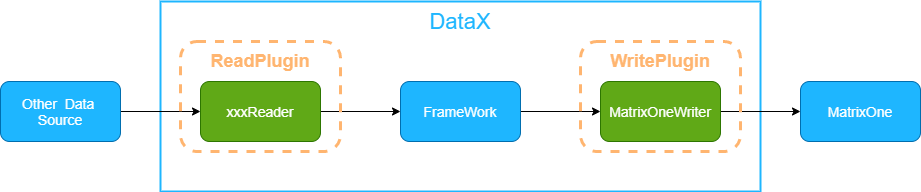
DataX 是一款由阿里开源的异构数据源离线同步工具,提供了稳定和高效的数据同步功能,旨在实现各种异构数据源之间的高效数据同步。
DataX 将不同数据源的同步分为两个主要组件:Reader(读取数据源) 和 Writer(写入目标数据源)。DataX 框架理论上支持任何数据源类型的数据同步工作。
MatrixOne 与 MySQL 8.0 高度兼容,但由于 DataX 自带的 MySQL Writer 插件适配的是 MySQL 5.1 的 JDBC 驱动,为了提升兼容性,社区单独改造了基于 MySQL 8.0 驱动的 MatrixOneWriter 插件。MatrixOneWriter 插件实现了将数据写入 MatrixOne 数据库目标表的功能。在底层实现中,MatrixOneWriter 通过 JDBC 连接到远程 MatrixOne 数据库,并执行相应的 insert into ... SQL 语句将数据写入 MatrixOne,同时支持批量提交。
MatrixOneWriter 利用 DataX 框架从 Reader 获取生成的协议数据,并根据您配置的 writeMode 生成相应的 insert into... 语句。在遇到主键或唯一性索引冲突时,会排除冲突的行并继续写入。出于性能优化的考虑,我们采用了 PreparedStatement + Batch 的方式,并设置了 rewriteBatchedStatements=true 选项,以将数据缓冲到线程上下文的缓冲区中。只有当缓冲区的数据量达到预定的阈值时,才会触发写入请求。
Note
执行整个任务至少需要拥有 insert into ... 的权限,是否需要其他权限取决于你在任务配置中的 preSql 和 postSql。
MatrixOneWriter 主要面向 ETL 开发工程师,他们使用 MatrixOneWriter 将数据从数据仓库导入到 MatrixOne。同时,MatrixOneWriter 也可以作为数据迁移工具为 DBA 等用户提供服务。
开始前准备
在开始使用 DataX 将数据写入 MatrixOne 之前,需要完成安装以下软件:
- 安装 JDK 8+ version。
- 安装 Python 3.8(or plus)。
- 下载 DataX 安装包,并解压。
- 下载 matrixonewriter.zip,解压至 DataX 项目根目录的
plugin/writer/目录下。 - 安装 MySQL Client。
- 安装和启动 MatrixOne。
操作步骤
创建 MatrixOne 测试表
使用 Mysql Client 连接 MatrixOne,在 MatrixOne 中创建一个测试表:
CREATE DATABASE mo_demo;
USE mo_demo;
CREATE TABLE m_user(
M_ID INT NOT NULL,
M_NAME CHAR(25) NOT NULL
);
配置数据源
本例中,我们使用内存中生成的数据作为数据源:
"reader": {
"name": "streamreader",
"parameter": {
"column" : [ #可以写多个列
{
"value": 20210106, #表示该列的值
"type": "long" #表示该列的类型
},
{
"value": "matrixone",
"type": "string"
}
],
"sliceRecordCount": 1000 #表示要打印多少次
}
}
编写作业配置文件
使用以下命令查看配置模板:
python datax.py -r {YOUR_READER} -w matrixonewriter
编写作业的配置文件 stream2matrixone.json:
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column" : [
{
"value": 20210106,
"type": "long"
},
{
"value": "matrixone",
"type": "string"
}
],
"sliceRecordCount": 1000
}
},
"writer": {
"name": "matrixonewriter",
"parameter": {
"writeMode": "insert",
"username": "root",
"password": "111",
"column": [
"M_ID",
"M_NAME"
],
"preSql": [
"delete from m_user"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://127.0.0.1:6001/mo_demo",
"table": [
"m_user"
]
}
]
}
}
}
]
}
}
启动 DataX
执行以下命令启动 DataX:
$ cd {YOUR_DATAX_DIR_BIN}
$ python datax.py stream2matrixone.json
查看运行结果
使用 Mysql Client 连接 MatrixOne,使用 select 查询插入的结果。内存中的 1000 条数据已成功写入 MatrixOne。
mysql> select * from m_user limit 5;
+----------+-----------+
| m_id | m_name |
+----------+-----------+
| 20210106 | matrixone |
| 20210106 | matrixone |
| 20210106 | matrixone |
| 20210106 | matrixone |
| 20210106 | matrixone |
+----------+-----------+
5 rows in set (0.01 sec)
mysql> select count(*) from m_user limit 5;
+----------+
| count(*) |
+----------+
| 1000 |
+----------+
1 row in set (0.00 sec)
参数说明
以下是 MatrixOneWriter 的一些常用参数说明:
| 参数名称 | 参数描述 | 是否必选 | 默认值 |
|---|---|---|---|
| jdbcUrl | 目标数据库的 JDBC 连接信息。DataX 在运行时会在提供的 jdbcUrl 后面追加一些属性,例如:yearIsDateType=false&zeroDateTimeBehavior=CONVERT_TO_NULL&rewriteBatchedStatements=true&tinyInt1isBit=false&serverTimezone=Asia/Shanghai。 |
是 | 无 |
| username | 目标数据库的用户名。 | 是 | 无 |
| password | 目标数据库的密码。 | 是 | 无 |
| table | 目标表的名称。支持写入一个或多个表,如果配置多张表,必须确保它们的结构保持一致。 | 是 | 无 |
| column | 目标表中需要写入数据的字段,字段之间用英文逗号分隔。例如:"column": ["id","name","age"]。如果要写入所有列,可以使用 * 表示,例如:"column": ["*"]。 |
是 | 无 |
| preSql | 写入数据到目标表之前,会执行这里配置的标准 SQL 语句。 | 否 | 无 |
| postSql | 写入数据到目标表之后,会执行这里配置的标准 SQL 语句。 | 否 | 无 |
| writeMode | 控制写入数据到目标表时使用的 SQL 语句,可以选择 insert 或 update。 |
insert 或 update |
insert |
| batchSize | 一次性批量提交的记录数大小,可以显著减少 DataX 与 MatrixOne 的网络交互次数,提高整体吞吐量。但是设置过大可能导致 DataX 运行进程内存溢出 | 否 | 1024 |
类型转换
MatrixOneWriter 支持大多数 MatrixOne 数据类型,但也有少数类型尚未支持,需要特别注意你的数据类型。
以下是 MatrixOneWriter 针对 MatrixOne 数据类型的转换列表:
| DataX 内部类型 | MatrixOne 数据类型 |
|---|---|
| Long | int, tinyint, smallint, bigint |
| Double | float, double, decimal |
| String | varchar, char, text |
| Date | date, datetime, timestamp, time |
| Boolean | bool |
| Bytes | blob |
参考其他说明
-
MatrixOne 兼容 MySQL 协议,MatrixOneWriter 实际上是对 MySQL Writer 进行了一些 JDBC 驱动版本上的调整后的改造版本,你仍然可以使用 MySQL Writer 来写入 MatrixOne。
-
在 DataX 中添加 MatrixOne Writer,那么你需要下载 matrixonewriter.zip,然后将其解压缩到 DataX 项目根目录的
plugin/writer/目录下,即可开始使用。
最佳实践:实现 MatrixOne 与 ElasticSearch 间的数据迁移
MatrixOne 擅长 HTAP 场景的事务处理和低延迟分析计算,ElasticSearch 擅长全文检索,两者做为流行的搜索和分析引擎,结合起来可形成更完善的全场景分析解决方案。为了在不同场景间进行数据的高效流转,我们可通过 DataX 进行 MatrixOne 与 ElasticSearch 间的数据迁移。
环境准备
-
MatrixOne 版本:1.1.1
-
Elasticsearch 版本:7.10.2
-
DataX 版本:DataX_v202309
在 MatrixOne 中创建库和表
创建数据库 mo,并在该库创建数据表 person:
create database mo;
CREATE TABLE mo.`person` (
`id` INT DEFAULT NULL,
`name` VARCHAR(255) DEFAULT NULL,
`birthday` DATE DEFAULT NULL
);
在 ElasticSearch 中创建索引
创建名称为 person 的索引(下文 -u 参数后为 ElasticSearch 中的用户名和密码,本地测试时可按需进行修改或删除):
curl -X PUT "http://127.0.0.1:9200/person" -u elastic:elastic
输出如下信息表示创建成功:
{"acknowledged":true,"shards_acknowledged":true,"index":"person"}
给索引 person 添加字段:
curl -X PUT "127.0.0.1:9200/person/_mapping" -H 'Content-Type: application/json' -u elastic:elastic -d'
{
"properties": {
"id": { "type": "integer" },
"name": { "type": "text" },
"birthday": {"type": "date"}
}
}
'
输出如下信息表示设置成功:
{"acknowledged":true}
为 ElasticSearch 索引添加数据
通过 curl 命令添加三条数据:
curl -X POST '127.0.0.1:9200/person/_bulk' -H 'Content-Type: application/json' -u elastic:elastic -d '
{"index":{"_index":"person","_type":"_doc","_id":1}}
{"id": 1,"name": "MatrixOne","birthday": "1992-08-08"}
{"index":{"_index":"person","_type":"_doc","_id":2}}
{"id": 2,"name": "MO","birthday": "1993-08-08"}
{"index":{"_index":"person","_type":"_doc","_id":3}}
{"id": 3,"name": "墨墨","birthday": "1994-08-08"}
'
输出如下信息表示执行成功:
{"took":5,"errors":false,"items":[{"index":{"_index":"person","_type":"_doc","_id":"1","_version":1,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":0,"_primary_term":1,"status":201}},{"index":{"_index":"person","_type":"_doc","_id":"2","_version":1,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":1,"_primary_term":1,"status":201}},{"index":{"_index":"person","_type":"_doc","_id":"3","_version":1,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":2,"_primary_term":1,"status":201}}]}
查看索引中所有内容:
curl -u elastic:elastic -X GET http://127.0.0.1:9200/person/_search?pretty -H 'Content-Type: application/json' -d'
{
"query" : {
"match_all": {}
}
}'
可正常看到索引中新增的数据即表示执行成功。
使用 DataX 导入数据
1. 下载并解压 DataX
DataX 解压后目录如下:
[root@node01 datax]# ll
total 4
drwxr-xr-x. 2 root root 59 Nov 28 13:48 bin
drwxr-xr-x. 2 root root 68 Oct 11 09:55 conf
drwxr-xr-x. 2 root root 22 Oct 11 09:55 job
drwxr-xr-x. 2 root root 4096 Oct 11 09:55 lib
drwxr-xr-x. 4 root root 42 Oct 12 18:42 log
drwxr-xr-x. 4 root root 42 Oct 12 18:42 log_perf
drwxr-xr-x. 4 root root 34 Oct 11 09:55 plugin
drwxr-xr-x. 2 root root 23 Oct 11 09:55 script
drwxr-xr-x. 2 root root 24 Oct 11 09:55 tmp
为保证迁移的易用性和高效性,MatrixOne 社区开发了 elasticsearchreader 以及 matrixonewriter 两个插件,将 elasticsearchreader.zip 下载后使用 unzip 命令解压至 datax/plugin/reader 目录下(注意不要在该目录中保留插件 zip 包,关于 elasticsearchreader 的详细介绍可参考插件包内的 elasticsearchreader.md 文档),同样,将 matrixonewriter.zip 下载后解压至 datax/plugin/writer 目录下,matrixonewriter 是社区基于 mysqlwriter 的改造版,使用 mysql-connector-j-8.0.33.jar 驱动来保证更好的性能和兼容性,writer 部分的其语法可参考上文“参数说明”章节。
在进行后续的操作前,请先检查插件是否已正确分发在对应的位置中。
2. 编写 ElasticSearch 至 MatrixOne 的迁移作业文件
DataX 使用 json 文件来配置作业信息,编写作业文件例如 es2mo.json,习惯性的可以将其存放在 datax/job 目录中:
{
"job":{
"setting":{
"speed":{
"channel":1
},
"errorLimit":{
"record":0,
"percentage":0.02
}
},
"content":[
{
"reader":{
"name":"elasticsearchreader",
"parameter":{
"endpoint":"http://127.0.0.1:9200",
"accessId":"elastic",
"accessKey":"elastic",
"index":"person",
"type":"_doc",
"headers":{
},
"scroll":"3m",
"search":[
{
"query":{
"match_all":{
}
}
}
],
"table":{
"filter":"",
"nameCase":"UPPERCASE",
"column":[
{
"name":"id",
"type":"integer"
},
{
"name":"name",
"type":"text"
},
{
"name":"birthday",
"type":"date"
}
]
}
}
},
"writer":{
"name":"matrixonewriter",
"parameter":{
"username":"root",
"password":"111",
"column":[
"id",
"name",
"birthday"
],
"connection":[
{
"table":[
"person"
],
"jdbcUrl":"jdbc:mysql://127.0.0.1:6001/mo"
}
]
}
}
}
]
}
}
3. 执行迁移任务
进入 datax 安装目录,执行以下命令启动迁移作业:
cd datax
python bin/datax.py job/es2mo.json
作业执行完成后,输出结果如下:
2023-11-28 15:55:45.642 [job-0] INFO StandAloneJobContainerCommunicator - Total 3 records, 67 bytes | Speed 6B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.456s | Percentage 100.00%
2023-11-28 15:55:45.644 [job-0] INFO JobContainer -
任务启动时刻 : 2023-11-28 15:55:31
任务结束时刻 : 2023-11-28 15:55:45
任务总计耗时 : 14s
任务平均流量 : 6B/s
记录写入速度 : 0rec/s
读出记录总数 : 3
读写失败总数 : 0
4. 在 MatrixOne 中查看迁移后数据
在 MatrixOne 数据库中查看目标表中的结果,确认迁移已完成:
mysql> select * from mo.person;
+------+-----------+------------+
| id | name | birthday |
+------+-----------+------------+
| 1 | MatrixOne | 1992-08-08 |
| 2 | MO | 1993-08-08 |
| 3 | 墨墨 | 1994-08-08 |
+------+-----------+------------+
3 rows in set (0.00 sec)
5. 编写 MatrixOne 至 ElasticSearch 的作业文件
编写 datax 作业文件 mo2es.json,同样放在 datax/job 目录,MatrixOne 高度兼容 MySQL 协议,我们可以直接使用 mysqlreader 来通过 jdbc 方式读取 MatrixOne 中的数据:
{
"job": {
"setting": {
"speed": {
"channel": 1
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "111",
"column": [
"id",
"name",
"birthday"
],
"splitPk": "id",
"connection": [{
"table": [
"person"
],
"jdbcUrl": [
"jdbc:mysql://127.0.0.1:6001/mo"
]
}]
}
},
"writer": {
"name": "elasticsearchwriter",
"parameter": {
"endpoint": "http://127.0.0.1:9200",
"accessId": "elastic",
"accessKey": "elastic",
"index": "person",
"type": "_doc",
"cleanup": true,
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 1
}
},
"discovery": false,
"batchSize": 1000,
"splitter": ",",
"column": [{
"name": "id",
"type": "integer"
},
{
"name": "name",
"type": "text"
},
{
"name": "birthday",
"type": "date"
}
]
}
}
}]
}
}
6.MatrixOne 数据准备
truncate table mo.person;
INSERT into mo.person (id, name, birthday)
VALUES(1, 'mo101', '2023-07-09'),(2, 'mo102', '2023-07-08'),(3, 'mo103', '2023-07-12');
7. 执行 MatrixOne 向 ElasticSearch 的迁移任务
进入 datax 安装目录,执行以下命令
cd datax
python bin/datax.py job/mo2es.json
执行完成后,输出结果如下:
2023-11-28 17:38:04.795 [job-0] INFO StandAloneJobContainerCommunicator - Total 3 records, 42 bytes | Speed 4B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.000s | Percentage 100.00%
2023-11-28 17:38:04.799 [job-0] INFO JobContainer -
任务启动时刻 : 2023-11-28 17:37:49
任务结束时刻 : 2023-11-28 17:38:04
任务总计耗时 : 15s
任务平均流量 : 4B/s
记录写入速度 : 0rec/s
读出记录总数 : 3
读写失败总数 : 0
8. 查看执行结果
在 Elasticsearch 中查看结果
curl -u elastic:elastic -X GET http://127.0.0.1:9200/person/_search?pretty -H 'Content-Type: application/json' -d'
{
"query" : {
"match_all": {}
}
}'
结果显示如下,表示迁移作业已正常完成:
{
"took" : 7,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "person",
"_type" : "_doc",
"_id" : "dv9QFYwBPwIzfbNQfgG1",
"_score" : 1.0,
"_source" : {
"birthday" : "2023-07-09T00:00:00.000+08:00",
"name" : "mo101",
"id" : 1
}
},
{
"_index" : "person",
"_type" : "_doc",
"_id" : "d_9QFYwBPwIzfbNQfgG1",
"_score" : 1.0,
"_source" : {
"birthday" : "2023-07-08T00:00:00.000+08:00",
"name" : "mo102",
"id" : 2
}
},
{
"_index" : "person",
"_type" : "_doc",
"_id" : "eP9QFYwBPwIzfbNQfgG1",
"_score" : 1.0,
"_source" : {
"birthday" : "2023-07-12T00:00:00.000+08:00",
"name" : "mo103",
"id" : 3
}
}
]
}
}
常见问题
Q: 在运行时,我遇到了“配置信息错误,您提供的配置文件/{YOUR_MATRIXONE_WRITER_PATH}/plugin.json 不存在”的问题该怎么处理?
A: DataX 在启动时会尝试查找相似的文件夹以寻找 plugin.json 文件。如果 matrixonewriter.zip 文件也存在于相同的目录下,DataX 将尝试从 .../datax/plugin/writer/matrixonewriter.zip/plugin.json 中查找。在 MacOS 环境下,DataX 还会尝试从 .../datax/plugin/writer/.DS_Store/plugin.json 中查找。此时,您需要删除这些多余的文件或文件夹。