将数据从 Oracle 迁移至 MatrixOne
本篇文档将指导你如何将数据从 Oracle 迁移至 MatrixOne。
Oracle 是全球目前最广泛使用的商业数据库,其使用场景与流行度都常年高居 DBEngine 第一名,MatrixOne 同样可以支持将数据从 Oracle 迁移的场景。根据 Oracle 的数据量大小,本文依然推荐使用在线与离线两种模式进行迁移。
数据类型差异
MatrixOne 与 Oracle 自带的数据类型存在着较多的差异,这些差异有些可以通过其他类型来替换,有些则暂时无法支持,具体列表如下:
| Oracle | MatrixOne |
|---|---|
| varchar2 | 使用 text 替换 |
| nchar/nvarcahr | 使用 char/varchar 替换 |
| NUMBER(3,0), NUMBER(5,0) | 使用 smallint 替换 |
| NUMBER(10,0) | 使用 int 替换 |
| NUMBER(38,0) | 使用 bitint 替换 |
| NUMBER(n,p) (p>0) | 使用 decimal(n,p) 替换 |
| binary_float/binary_double | 使用 float/double 替换 |
| long | 使用 text 替换 |
| long raw | 使用 blob 替换 |
| raw | 使用 varbinary 替换 |
| clob/nclob | 使用 text 替换 |
| bfile | 暂不支持 |
| rowid/urowid | 暂不支持 |
| user-defined types | 暂不支持 |
| any | 暂不支持 |
| xml | 暂不支持 |
| spatial | 暂不支持 |
在线迁移
本章节将指导你使用第三方工具 DBeaver,将数据从 Oracle 迁移至 MatrixOne。
通过 DBeaver,将源端的数据按批次获取,再将数据以 INSERT 的方式,插入到目标库。如果在迁移过程中报错 heap 空间不足,请尝试调整每个批次获取并插入数据的规模。
- 适用场景:数据量较小(建议小于 1GB),对迁移的速度不敏感的场景。
- 安装 DBeaver 的跳板机推荐配置:内存 16GB 以上。
准备工作
- 带图形界面的跳板机:可连接 Oracle 源端,也可连接 MatrixOne 目标端。
- 数据迁移工具:在跳板机上下载 DBeaver。
第一步:迁移表结构
在这里以 TPCH 数据集为例,将 TPCH 数据集的 8 张表从 Oracle 迁移至 MatrixOne。
-
打开 DBeaver,从 Oracle 中选择待迁移的表,鼠标右键点击后选择生成 SQL > DDL > 复制,先将这段 SQL 复制到一个文本编辑器内,给文本编辑器命名为 oracle_ddl.sql,保存到跳板机本地。

-
使用下面的命令替换 oracle_ddl.sql 文件内 MatrixOne 不支持的关键字:
# Linux 系统执行的命令如下: sed -i '/CHECK (/d' /YOUR_PATH/oracle_ddl.sql sed -i '/CREATE UNIQUE INDEX/g' /YOUR_PATH/oracle_ddl.sql sed -i 's/NUMBER(3,0)/smallint/g' /YOUR_PATH/oracle_ddl.sql sed -i 's/NUMBER(5,0)/smallint/g' /YOUR_PATH/oracle_ddl.sql sed -i 's/NUMBER(10,0)/int/g' /YOUR_PATH/oracle_ddl.sql sed -i 's/NUMBER(38,0)/bigint/g' /YOUR_PATH/oracle_ddl.sql sed -i 's/NUMBER/decimal/g' /YOUR_PATH/oracle_ddl.sql sed -i 's/VARCHAR2/varchar/g' /YOUR_PATH/oracle_ddl.sql #MacOS 系统则使用的命令如下: sed -i '' '/CHECK (/d' /YOUR_PATH/oracle_ddl.sql sed -i '' '/CREATE UNIQUE INDEX/g' /YOUR_PATH/oracle_ddl.sql sed -i '' 's/NUMBER(3,0)/smallint/g' /YOUR_PATH/oracle_ddl.sql sed -i '' 's/NUMBER(5,0)/smallint/g' /YOUR_PATH/oracle_ddl.sql sed -i '' 's/NUMBER(10,0)/int/g' /YOUR_PATH/oracle_ddl.sql sed -i '' 's/NUMBER(38,0)/bigint/g' /YOUR_PATH/oracle_ddl.sql sed -i '' 's/NUMBER/decimal/g' /YOUR_PATH/oracle_ddl.sql sed -i '' 's/VARCHAR2/varchar/g' /YOUR_PATH/oracle_ddl.sql -
连接到 MatrixOne,在 MatrixOne 中创建新的数据库和表:
create database tpch; use tpch; source '/YOUR_PATH/oracle_ddl.sql'
第二步:迁移数据
-
打开 DBeaver,从 Oracle 中选择待迁移的表,鼠标右键点击后选择导出数据:
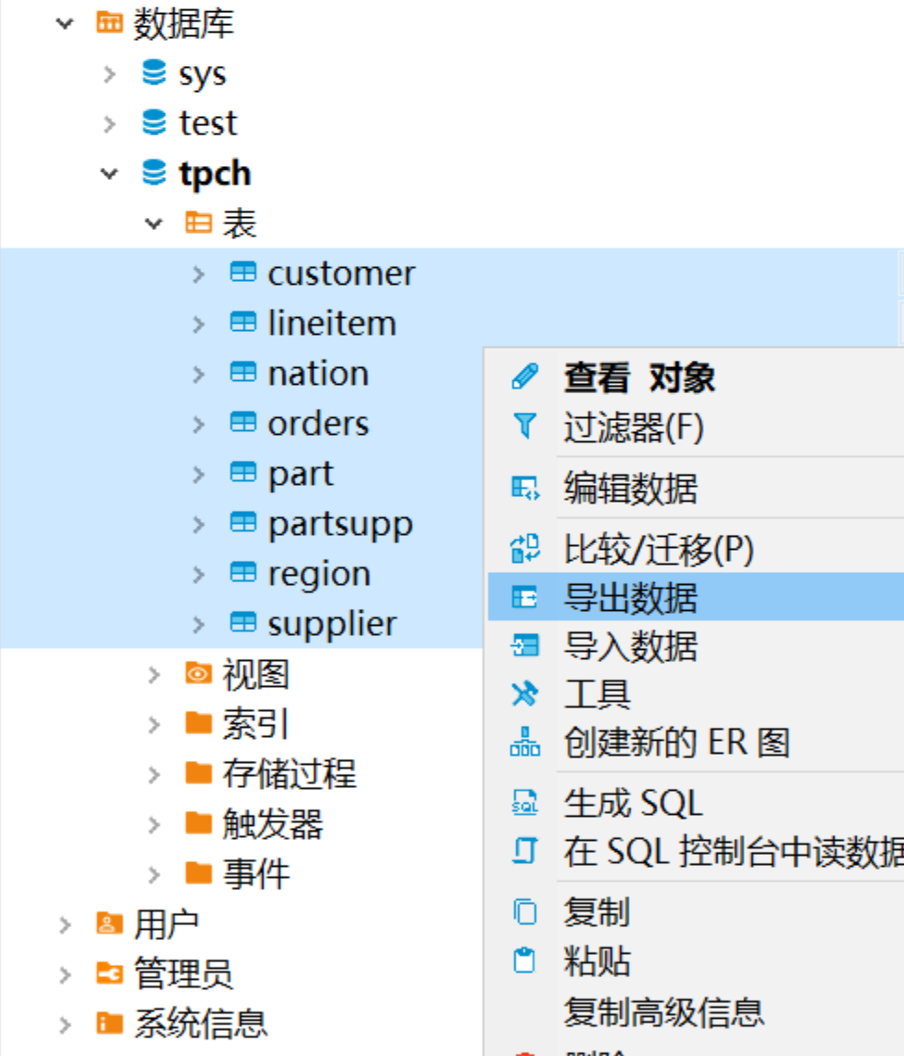
-
在转化目标 > 导出目标窗口选择数据库,点击下一步;在表映射窗口选择目标容器,目标容器选择 MatrixOne 的数据库 tpch:
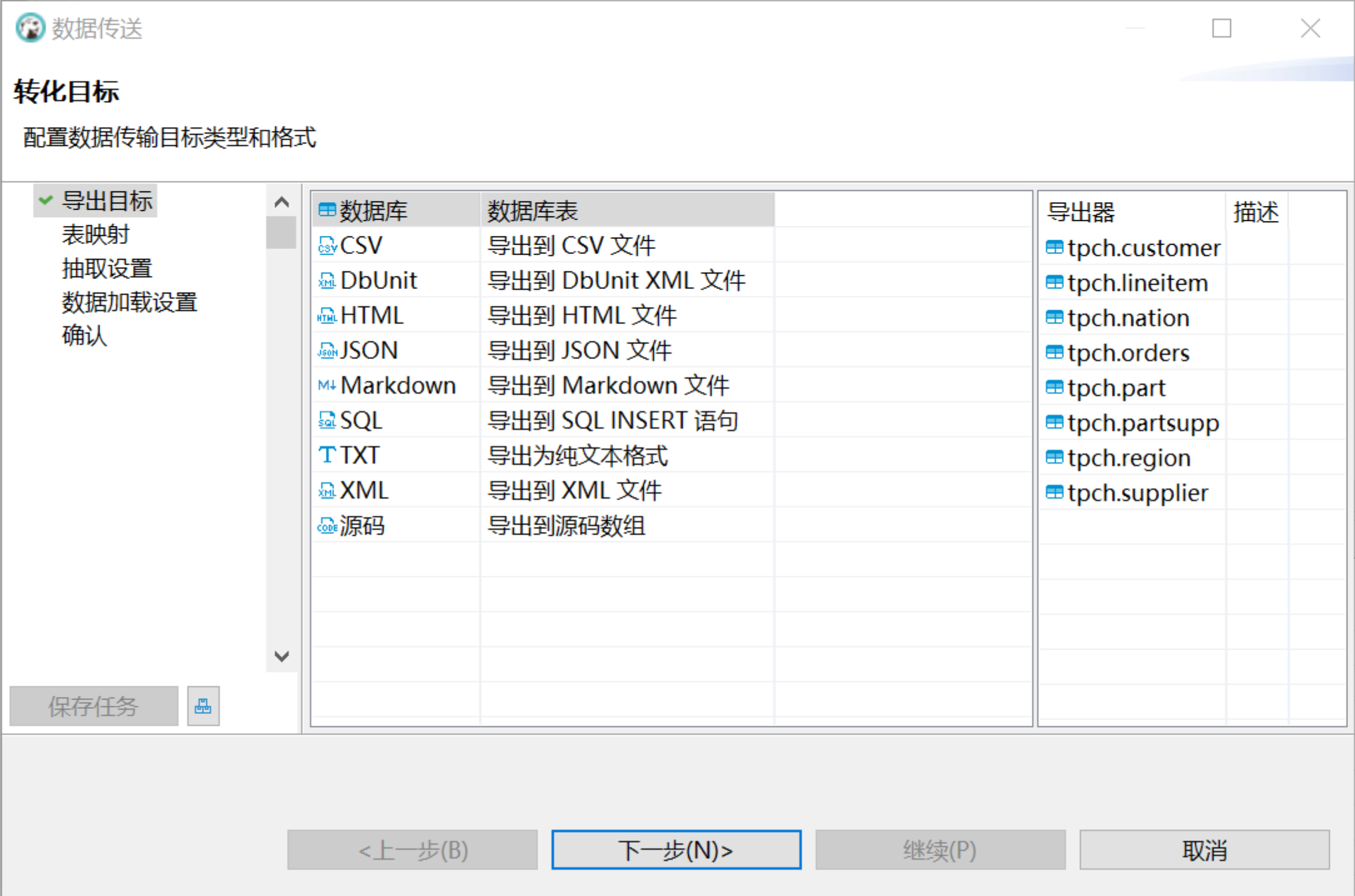
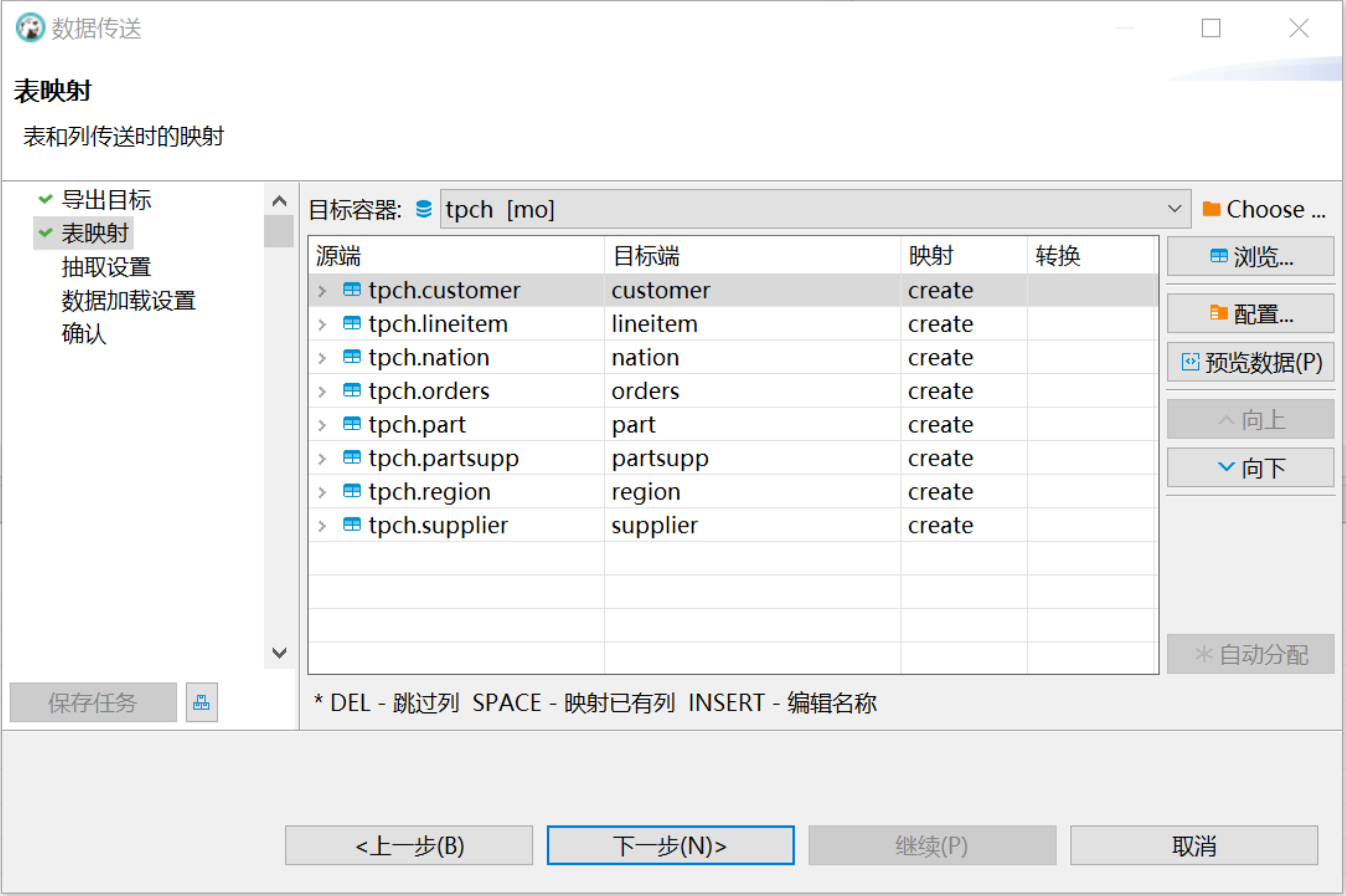
-
在抽取设置和数据加载设置窗口,设置选择抽取和插入的数量,为了触发 MatrixOne 的直接写 S3 策略,建议填写 5000:
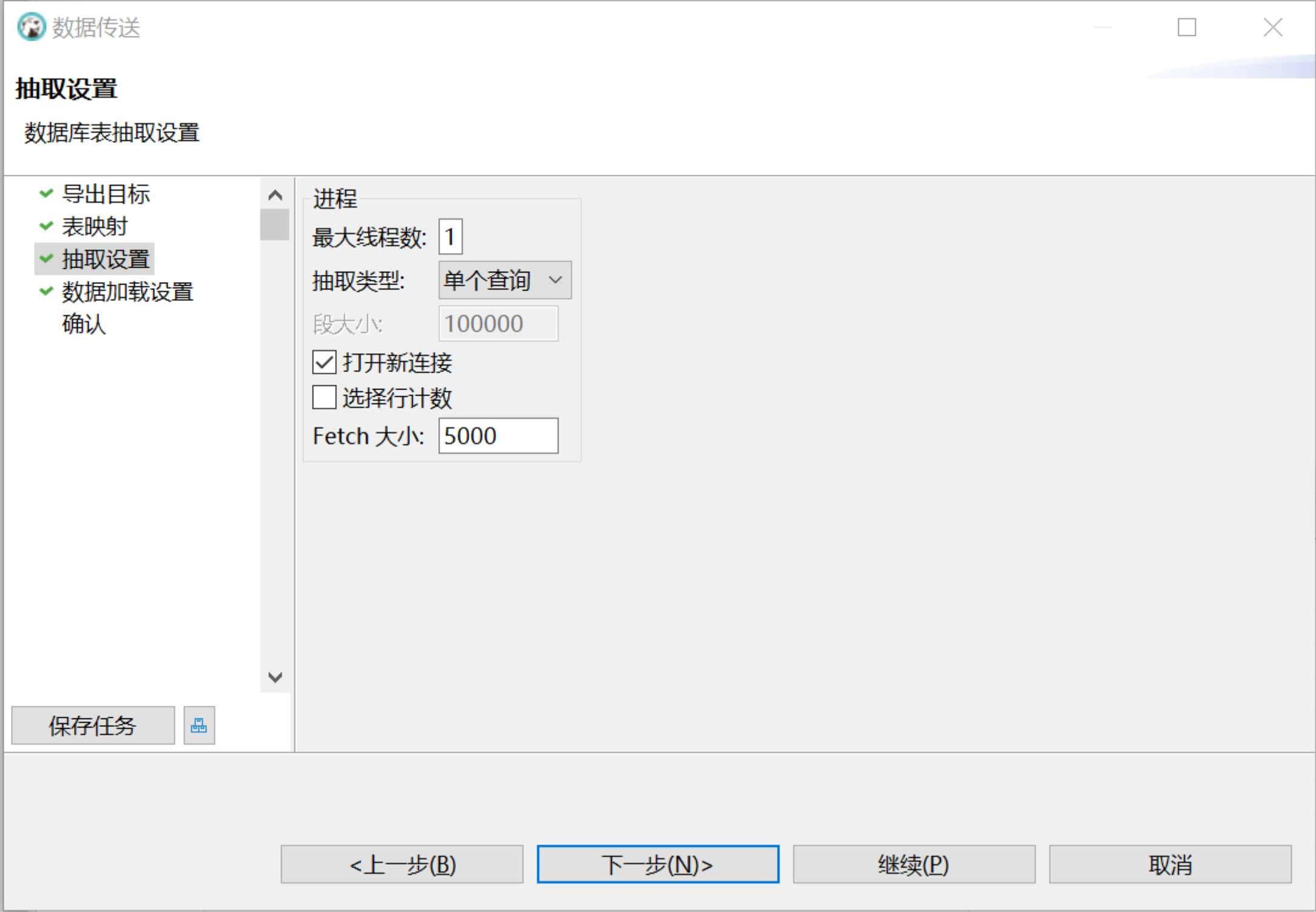

-
完成设置后,DBeaver 开始对数据进行迁移,在完成后 DBeaver 将会提示迁移成功。
第三步:检查数据
完成迁移之后,可以采用如下方式检查数据:
-
通过
select count(*) from <table_name>来确认源库与目标库的数据量是否一致。 -
通过相关的查询对比结果,你也可以参见完成 TPCH 测试查询示例,进行结果对比。
离线迁移
本章节将指导你通过离线文件导入到 MatrixOne。
- 适用场景:数据量较大(大于 1GB),对迁移的速度较为敏感的场景。
准备工作
- 带图形界面的跳板机:可连接 Oracle 源端,也可连接 MatrixOne 目标端的。
- 数据迁移工具:在跳板机上下载 DBeaver。
第一步:迁移表结构
在这里以 TPCH 数据集为例,将 TPCH 数据集的 8 张表从 Oracle 迁移至 MatrixOne。
-
打开 DBeaver,从 Oracle 中选择待迁移的表,鼠标右键点击后选择生成 SQL > DDL > 复制,先将这段 SQL 复制到一个文本编辑器内,给文本编辑器命名为 oracle_ddl.sql,保存到跳板机本地。
-
使用下面的命令替换 oracle_ddl.sql 文件内 MatrixOne 不支持的关键字:
# Linux 系统执行的命令如下: sed -i '/CHECK (/d' /YOUR_PATH/oracle_ddl.sql sed -i '/CREATE UNIQUE INDEX/g' /YOUR_PATH/oracle_ddl.sql sed -i 's/NUMBER(3,0)/smallint/g' /YOUR_PATH/oracle_ddl.sql sed -i 's/NUMBER(5,0)/smallint/g' /YOUR_PATH/oracle_ddl.sql sed -i 's/NUMBER(10,0)/int/g' /YOUR_PATH/oracle_ddl.sql sed -i 's/NUMBER(38,0)/bigint/g' /YOUR_PATH/oracle_ddl.sql sed -i 's/NUMBER/decimal/g' /YOUR_PATH/oracle_ddl.sql sed -i 's/VARCHAR2/varchar/g' /YOUR_PATH/oracle_ddl.sql #MacOS 系统则使用的命令如下: sed -i '' '/CHECK (/d' /YOUR_PATH/oracle_ddl.sql sed -i '' '/CREATE UNIQUE INDEX/g' /YOUR_PATH/oracle_ddl.sql sed -i '' 's/NUMBER(3,0)/smallint/g' /YOUR_PATH/oracle_ddl.sql sed -i '' 's/NUMBER(5,0)/smallint/g' /YOUR_PATH/oracle_ddl.sql sed -i '' 's/NUMBER(10,0)/int/g' /YOUR_PATH/oracle_ddl.sql sed -i '' 's/NUMBER(38,0)/bigint/g' /YOUR_PATH/oracle_ddl.sql sed -i '' 's/NUMBER/decimal/g' /YOUR_PATH/oracle_ddl.sql sed -i '' 's/VARCHAR2/varchar/g' /YOUR_PATH/oracle_ddl.sql -
连接到 MatrixOne,在 MatrixOne 中创建新的数据库和表:
create database tpch; use tpch; source '/YOUR_PATH/oracle_ddl.sql'
第二步:迁移数据
在 MatrixOne 中,有两种数据迁移方式可供选择:INSERT 和 LOAD DATA。当数据量大于 1GB 时,首先推荐使用 LOAD DATA,其次可以选择使用 INSERT。
LOAD DATA
使用 DBeaver 先将 Oracle 的数据表导出为 CSV 格式,并使用 MatrixOne 的并行加载功能将数据迁移至 MatrixOne:
-
打开 DBeaver,中选择待迁移的表,鼠标右键点击后选择导出数据,将 Oracle 数据表导出为 CSV 格式文件:
-
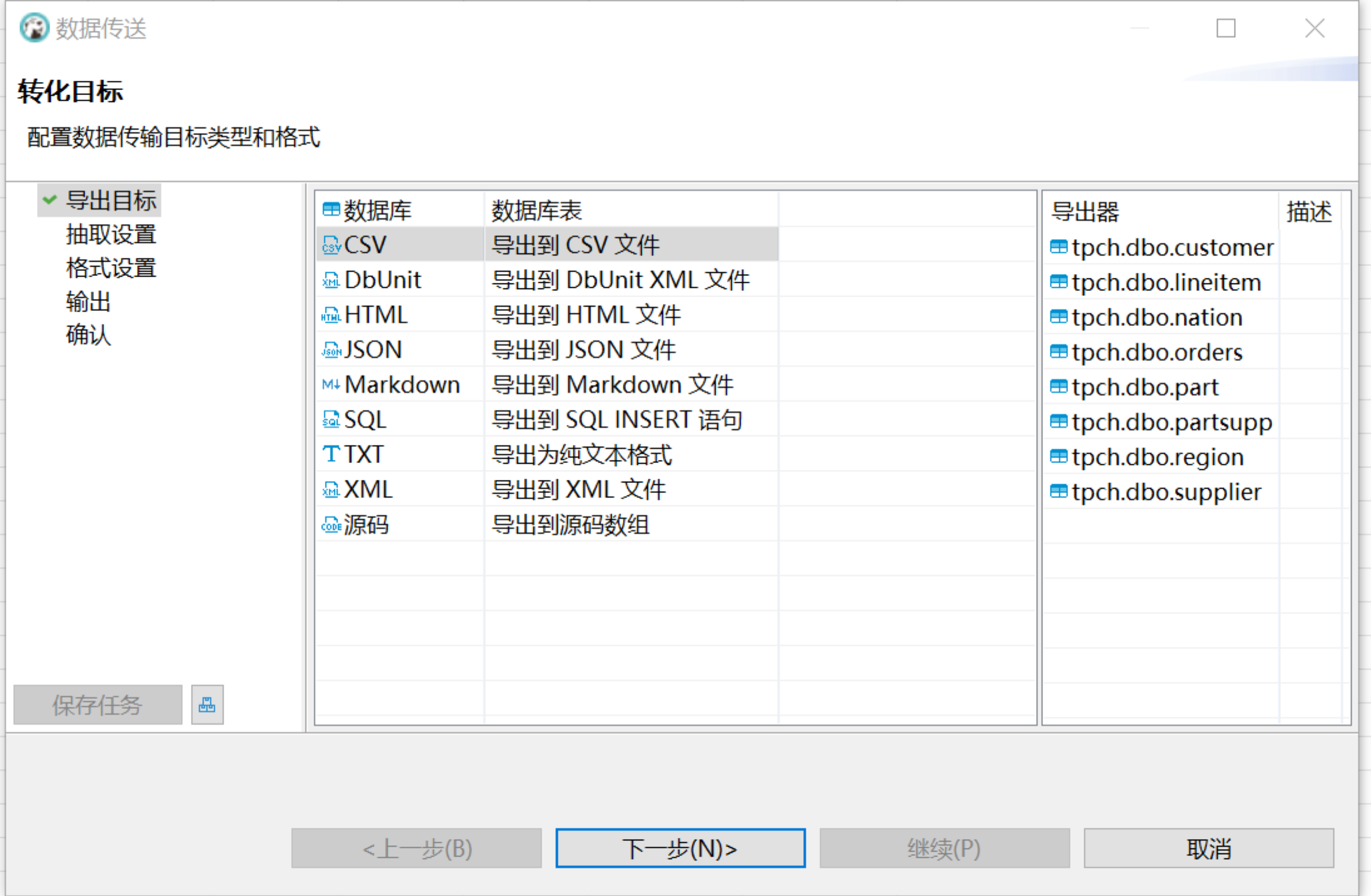
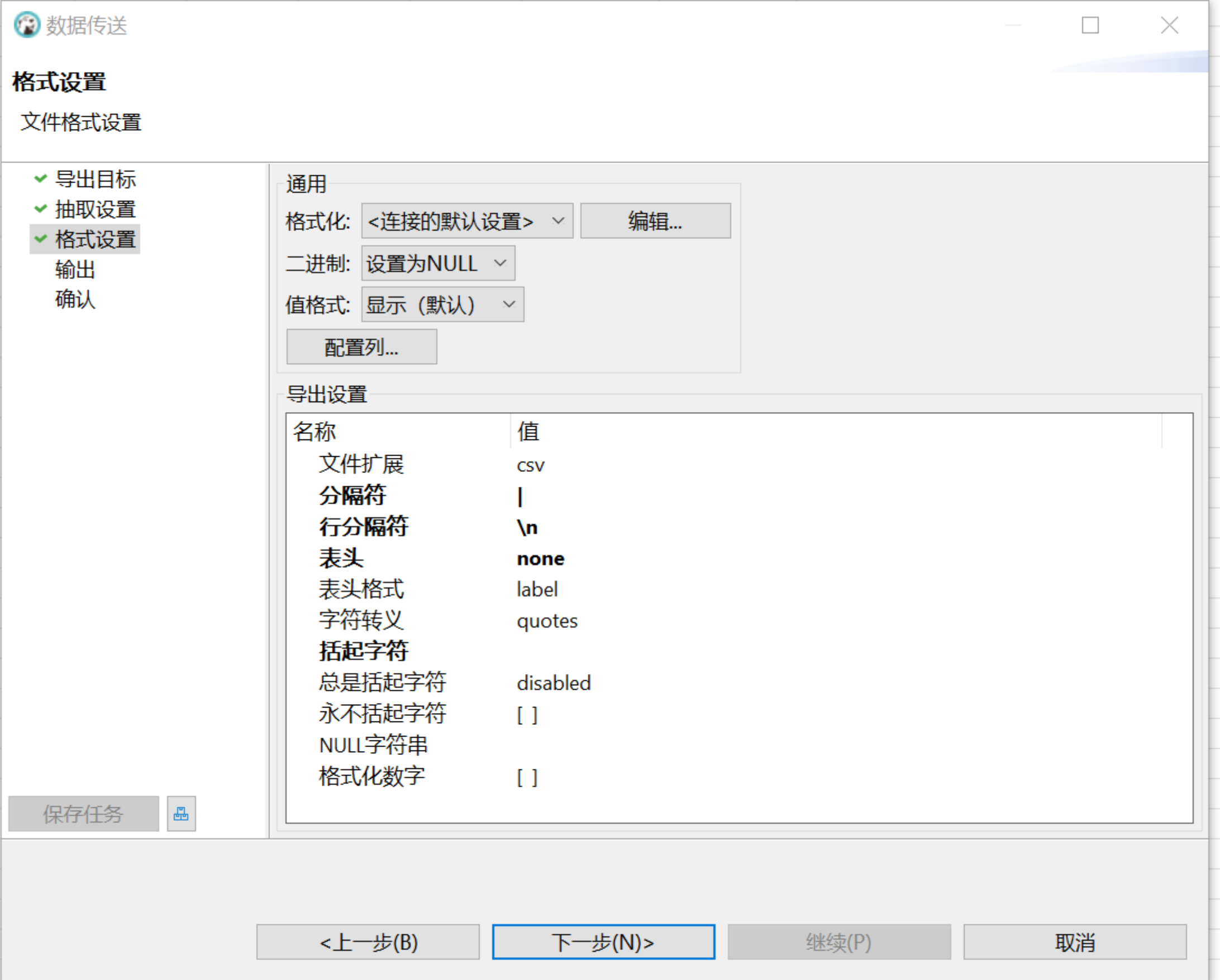
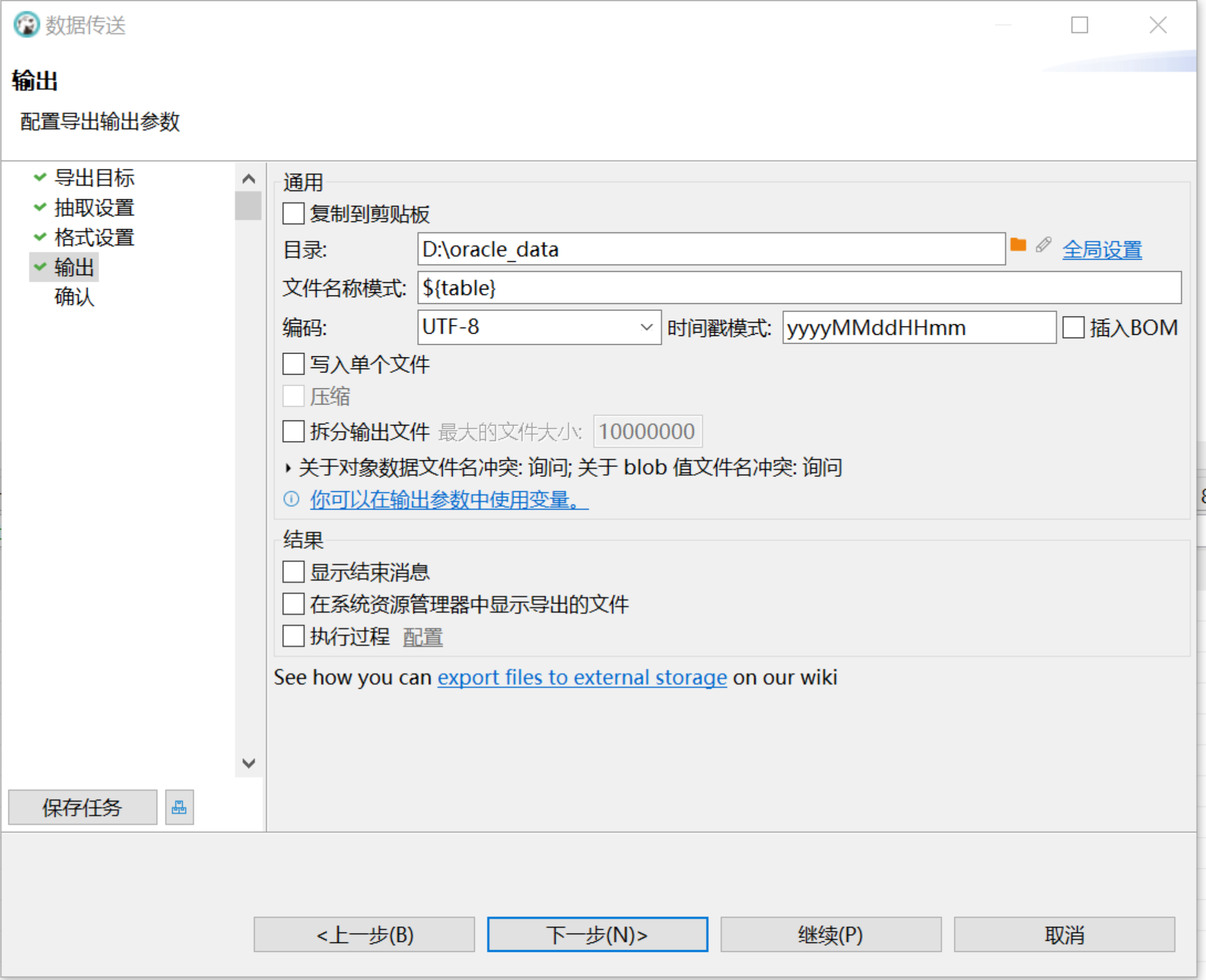
在转化目标 > 导出目标窗口选择 CSV,点击下一步:
-
连接到 MatrixOne,将导出的 CSV 数据导入至 MatrixOne:
mysql> load data infile '/{filepath}/lineitem.txt' INTO TABLE lineitem FIELDS TERMINATED BY '|' lines TERMINATED BY '\n' parallel 'true'; mysql> load data infile '/{filepath}/nation.txt' INTO TABLE nation FIELDS TERMINATED BY '|' lines TERMINATED BY '\n' parallel 'true'; mysql> load data infile '/{filepath}/part.txt' INTO TABLE part FIELDS TERMINATED BY '|' lines TERMINATED BY '\n' parallel 'true'; mysql> load data infile '/{filepath}/customer.txt' INTO TABLE customer FIELDS TERMINATED BY '|' lines TERMINATED BY '\n' parallel 'true'; mysql> load data infile '/{filepath}/orders.txt' INTO TABLE orders FIELDS TERMINATED BY '|' lines TERMINATED BY '\n' parallel 'true'; mysql> load data infile '/{filepath}/supplier.txt' INTO TABLE supplier FIELDS TERMINATED BY '|' lines TERMINATED BY '\n' parallel 'true'; mysql> load data infile '/{filepath}/region.txt' INTO TABLE region FIELDS TERMINATED BY '|' lines TERMINATED BY '\n' parallel 'true'; mysql> load data infile '/{filepath}/partsupp.txt' INTO TABLE partsupp FIELDS TERMINATED BY '|' lines TERMINATED BY '\n' parallel 'true';
更多关于 LOAD DATA 的操作示例,参见批量导入。
INSERT
INSERT 语句需要使用 DBeaver 先将逻辑语句导出,再导入到 MatrixOne:
-
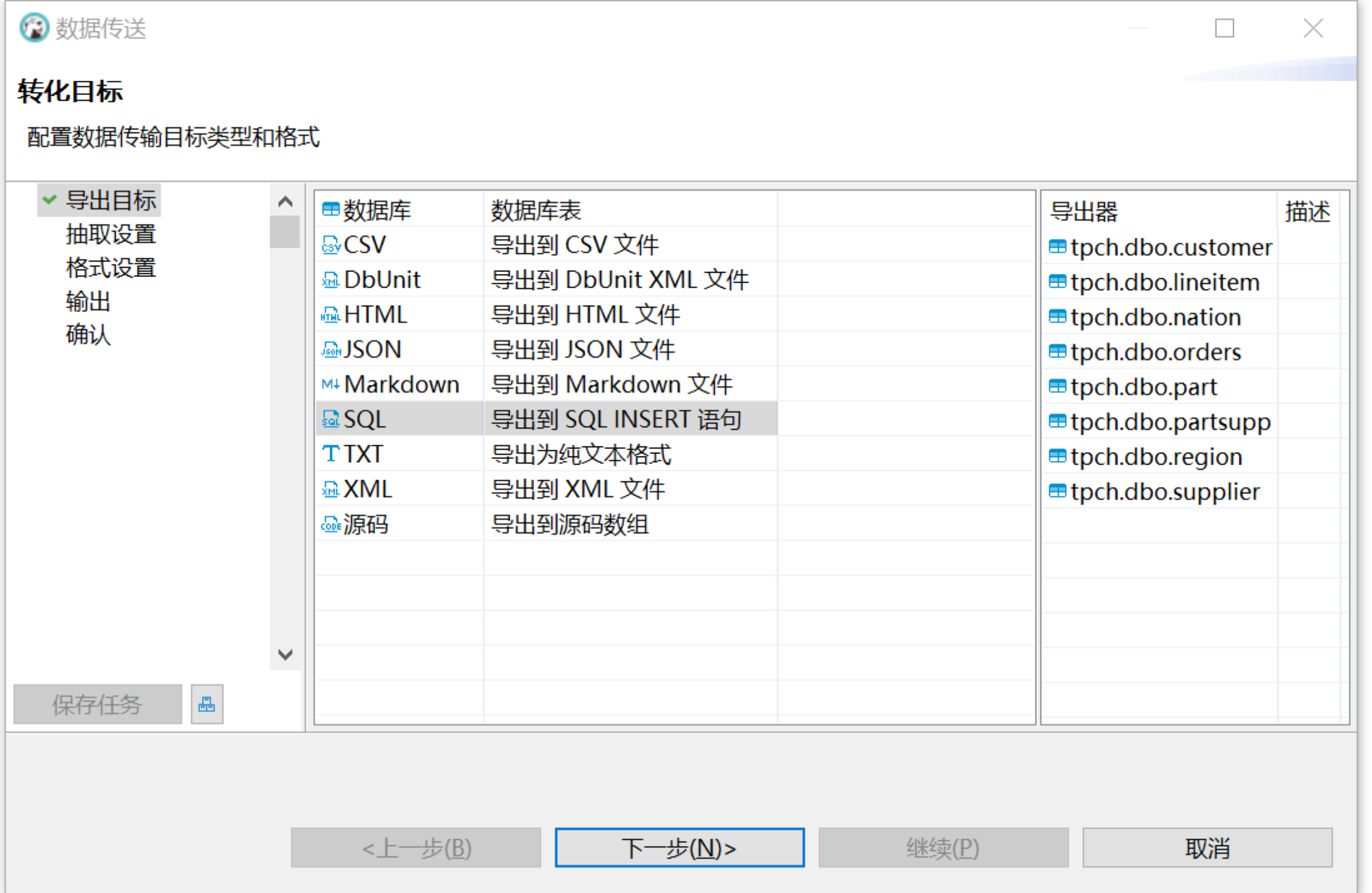
使用 DBeaver 导出数据:打开 DBeaver,从 Oracle 中选择待迁移的表,鼠标右键点击后选择导出数据 > SQL,为了确保插入时触发 MatrixOne 的直接写 S3,建议批量插入参数每条语句的数据行数设置为 5000:
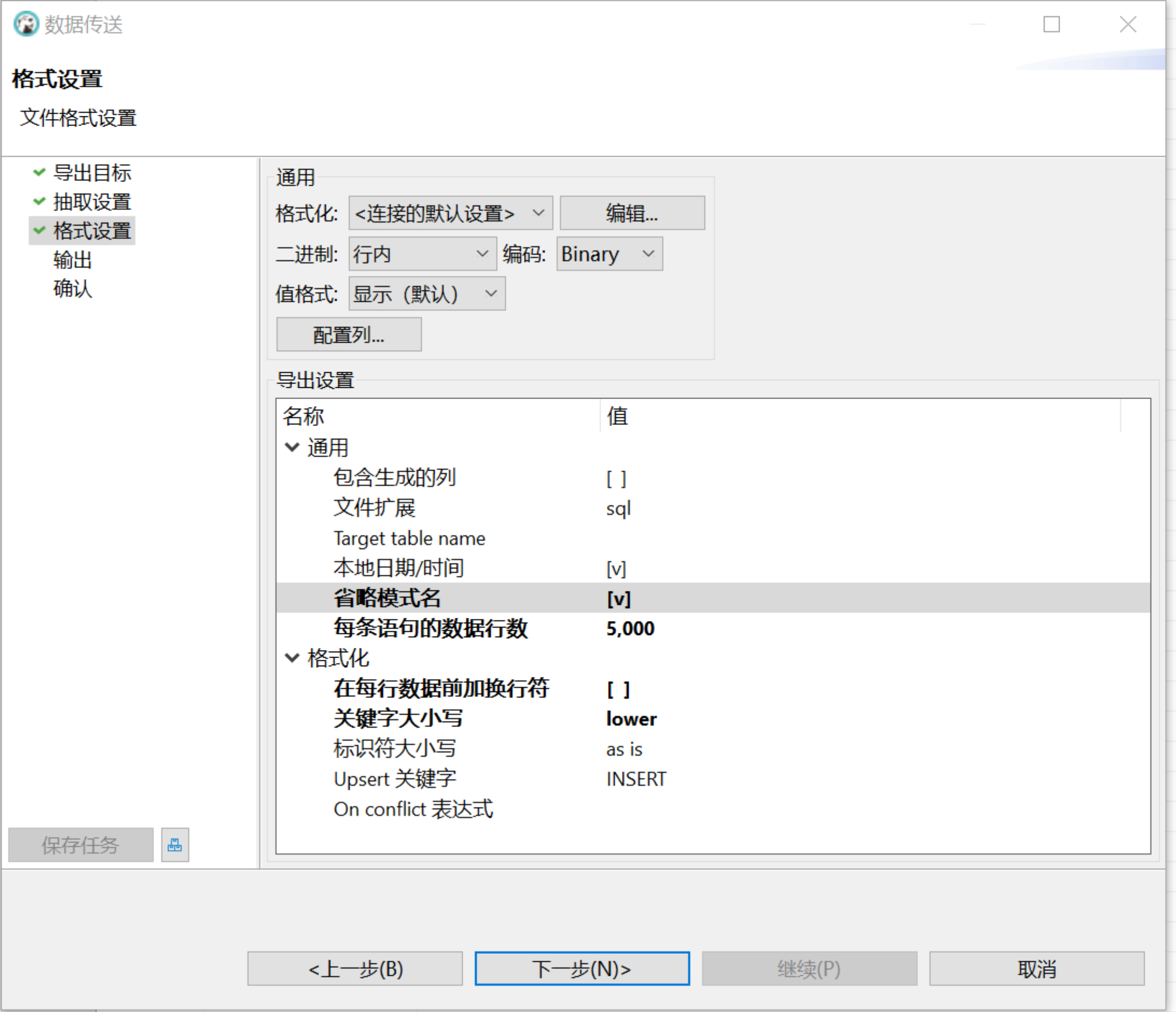
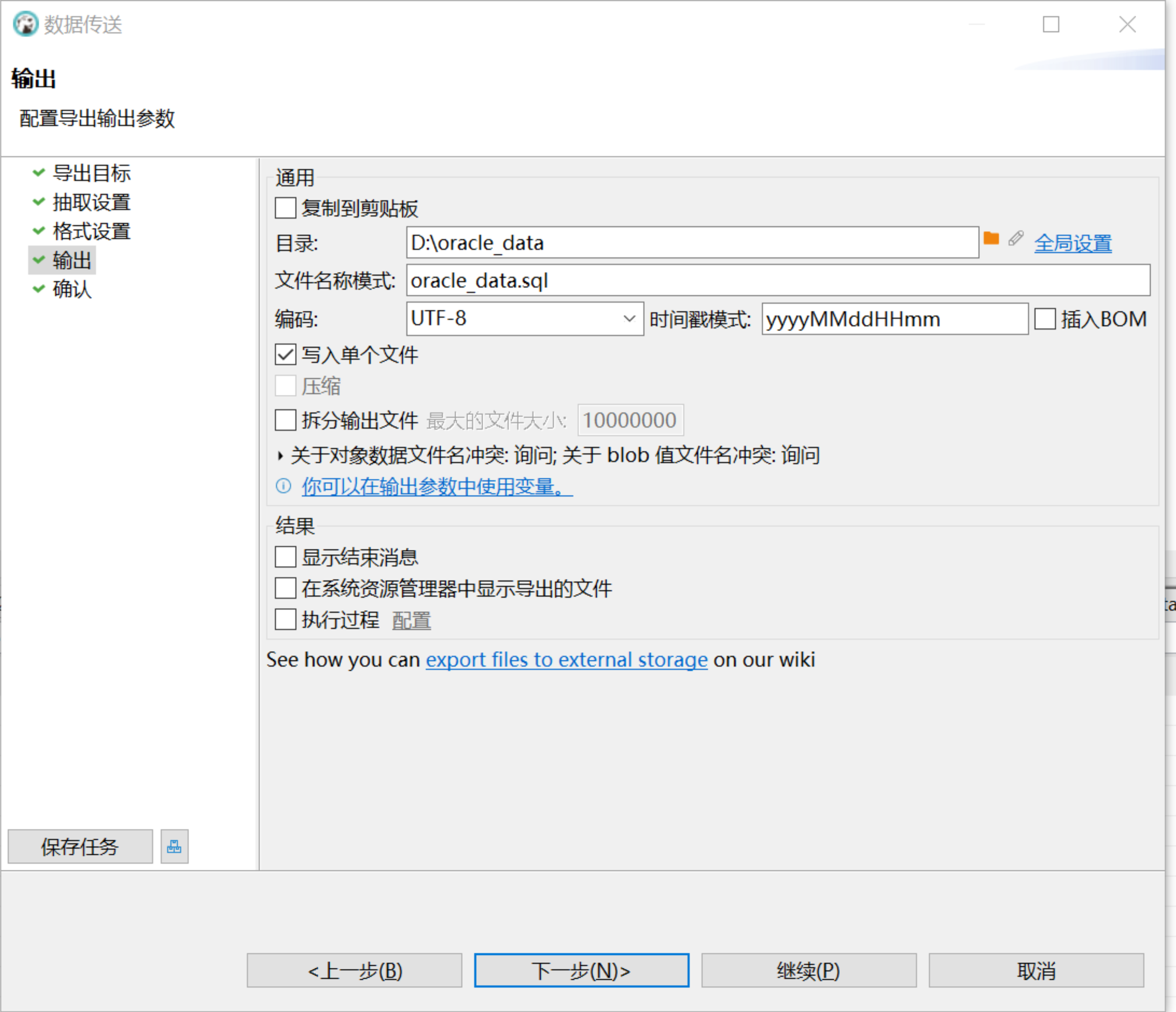
-
在 MatrixOne 端,执行该 SQL 文件:
source '/YOUR_PATH/oracle_data.sql'
更多关于 INSERT 的操作示例,参见插入数据。
第三步:检查数据
完成迁移之后,可以采用如下方式检查数据:
-
通过
select count(*) from <table_name>来确认源库与目标库的数据量是否一致。 -
通过相关的查询对比结果,你也可以参见完成 TPCH 测试查询示例,进行结果对比。