Logtail 协议详解
Logtail 是 CN(Computation Node,计算节点)与 TN(Transaction Node,事务节点)之间的一种日志同步协议,它作为 CN 和 TN 协同工作的基础。本文将深入介绍 Logtail 协议的基本定位、协议内容以及产生过程。
TAE 是 MatrixOne 云原生事务与分析引擎,与 TN 节点相关的职责目前包括:
- 处理提交的事务。
- 为 CN 提供 Logtail 服务。
- 转存最新的事务数据至对象存储中,并推动日志窗口。
在 1 和 3 完成时,都会产生状态变化,例如数据成功写入内存或对象存储。Logtail 是一种日志同步协议,旨在以低成本的方式同步 TN 的部分状态,使 CN 能够在本地重建所需的可读数据。作为 MatrixOne 存算分离架构的关键协议,Logtail 具有以下特点:
- 串联协同 CN 和 TN,本质上是一个日志复制状态机,使 CN 同步 TN 的部分状态。
-
Logtail 支持两种获取模式:pull 和 push。
- push 具有更高的实时性,不断将增量日志从 TN 同步到 CN。
- pull 支持指定时间区间的快照同步,也可以按需同步后续产生的增量日志信息。
-
Logtail 支持表级别的订阅和收集,使其在多 CN 支持方面更加灵活,有助于实现 CN 负载的均衡。
Logtail 协议内容
Logtail 协议分为两个部分:内存数据和元数据,其主要区别在于数据是否已转存到对象存储中。
一次事务 commit 产生的更新在转存到对象存储之前,其日志以内存数据的形式存在于 Logtail 中。任何数据上的修改都可以归结为插入和删除:
- 对于插入,Logtail 信息包含数据行的 row-id、commit-timestamp 以及表定义中的列。
- 对于删除,Logtail 信息包含 row-id、commit-timestamp 以及主键列。CN 收到这些内存数据后,将其在内存中组织成 Btree 结构,以便提供查询服务。
显然,内存数据不能永远保留在内存中,因为这会增加内存压力。出于时间或容量的考虑,内存数据会被刷新到对象存储中,形成一个对象。每个对象包含一个或多个数据块(block)。数据块是表数据的最小存储单位,每个块中的行数不超过固定上限,目前默认为 8192 行。刷新完成后,Logtail 将块的元数据传递给 CN,CN 根据事务时间戳过滤出可见的块列表,读取块中的内容,结合内存数据,得到某个时刻的完整数据视图。
上述过程是基础步骤,随着性能优化的引入,将呈现更多细节,例如:
1. 检查点(checkpoint)
当 TN 运行一段时间后,在某个时刻执行检查点,即将此时之前的所有数据转存到对象存储。因此,所有这些元数据将被整理成一个“压缩包”。当新启动的 CN 连接到 TN 并请求首次 Logtail 时,如果订阅时间戳大于检查点时间戳,TN 可以通过 Logtail 直接传递检查点元数据(一个字符串),从而让 CN 直接读取检查点之前生成的块信息,减轻了从头传递块元数据的网络负担,降低了 TN 的 I/O 压力。
2. 内存清理
当 TN 将块元数据传递给 CN 时,将根据块标识符清理先前传递的内存数据。然而,在 TN 刷新事务期间,可能会发生数据更新,例如刷新的块上可能会新产生删除操作。如果策略是回滚和重试,那么已经写入的数据将变得无效。在更新频繁的负载情况下,可能会产生大量的回滚操作,浪费 TN 资源。为避免这种情况,TN 将继续提交,导致刷新事务开始后生成的内存数据无法从 CN 中删除。在 Logtail 的块元信息中传递一个时间戳,在这个时间戳之前,该块的内存数据才能从内存中清理。这些未清理的更新将在下一次刷新中异步刷入磁盘,并通过 CN 进行删除。
3. 更快的读取
已经转存到对象存储中的块可能会继续产生删除操作,因此在读取这些块时,需要结合内存中的删除数据。为了更快地确定哪些块需要与内存数据结合,CN 额外维护一个块的 Btree 索引。应用 Logtail 时需要谨慎修改这个索引,以加快读取速度:处理内存数据时增加索引条目,处理块元数据时减少索引条目。只有在这个索引中的块才需要检查内存数据,在块数量较多时,这将带来巨大的性能提升。
Logtail 的生成
如前所述,Logtail 可以通过 pull 和 push 两种方式获取。这两种模式具有不同的特点,下面将分别介绍。
1. Pull
如前所述,pull 实际上是同步表的快照,以及后续产生的增量日志信息。
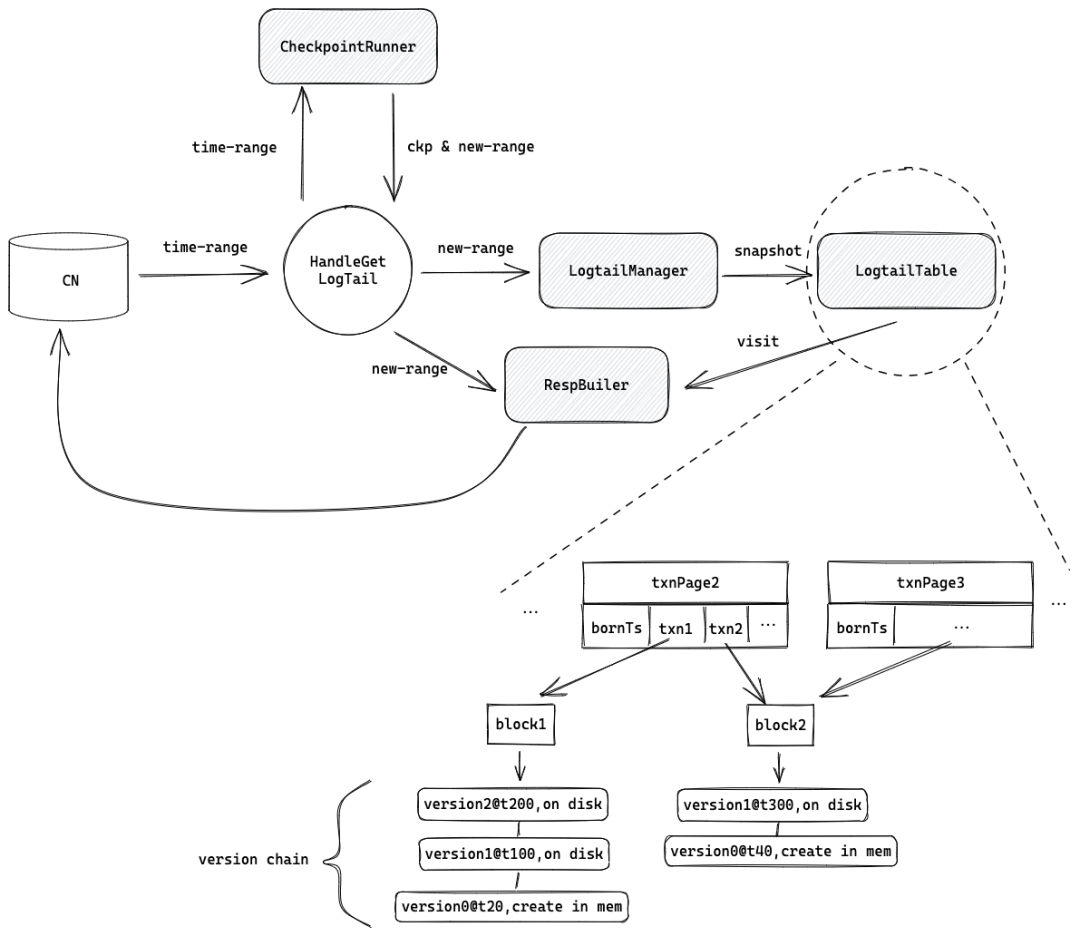
为了达成这个目的,TN 维护了一个按照事务 prepare 时间排序的 txn handle 列表,logtail table,给定任意时刻,通过二分查找得到范围内的 txn handle,再由 txn handle 得到该事务在哪些 block 上做过更新,通过遍历这些 block,就能得到完整的日志。为了加快查找速度,对 txn handle 做了分页,一个页的 bornTs 就是当前页中的 txn handle 的最小 prepare 时间,第一层二分的对象就是这些页。
基于 logtail table,从接收到 pull 请求,主要工作路径如下:
-
根据已有的 checkpoints,调整请求的时间范围,更早的可以通过 checkpoint 给出。
-
取 logtail table 的一份快照,基于访问者模式用 RespBuilder 去迭代这份快照中相关的 txn handle,收集已提交的日志信息。
-
将收集到的日志信息,按照 logtail 协议格式转换,作为响应返回给 CN。
type RespBuilder interface {
OnDatabase(database *DBEntry) error
OnPostDatabase(database *DBEntry) error
OnTable(table *TableEntry) error
OnPostTable(table *TableEntry) error
OnPostSegment(segment *SegmentEntry) error
OnSegment(segment *SegmentEntry) error
OnBlock(block *BlockEntry) error
BuildResp() (api.SyncLogtailResp, error)
Close()
}
2. Push
Push 的主要目的是更实时地 TN 同步增量日志到 CN。整体流程分为订阅、收集、推送三个阶段。
-
订阅:一个新 CN 启动后的必要流程,就是作为客户端,和服务端 TN 建立一个 RPC stream,并且订阅 catalog 相关表,当 database、table、column 这些基本信息同步完成后,CN 才能对外提供服务。当 TN 收到订阅一个表的请求时,其实先走一遍 pull 流程,会把截止到上次 push 时间戳前的所有 Logtail 都包含在订阅响应中。目前对一个 CN,Logtail 的订阅、取消订阅、数据发送,都发生在一条 RPC stream 链接上,如果它有任何异常,CN 会进入重连流程,直到恢复。一旦订阅成功,后续的 Logtail 就是推送增量日志。
-
收集:在 TN,一个事务完成 WAL 写入后,触发回调执行,在当前事务中收集 Logtail。主要流程是遍历 workspace 中的 TxnEntry(一种事务更新的基本容器,直接参与到 commit pipeline 中),依据其类型,取对应的日志信息转换为 Logtail 协议的数据格式。这个收集过程通过 pipeline,和 WAL 的 fysnc 并发执行,减少阻塞。
-
推送:推送阶段主要做一次过滤,如果发现某个 CN 没有订阅该表,就跳过该 CN,避免推送。
如果一个表长时间没有更新时,如何使 CN 获知?这里就加入了心跳机制,默认是 2 ms,TN 的 commit 队列中会放入一个 heartbeat 的空事务,不做任何实质性工作,只消耗时间戳,从而触发一次心跳 Logtail 发送,告知 CN 此前的所有表数据已经发送过更新,推动 CN 侧的时间戳水位更新。
