向量类型
什么是向量?
在数据库中,向量通常是一组数字,它们以特定的方式排列,以表示某种数据或特征。这些向量可以是一维数组、多维数组或具有更高维度的数据结构。在机器学习和数据分析领域中,向量用于表示数据点、特征或模型参数。它们通常是用来处理非结构化数据,如图片,语音,文本等,以通过机器学习模型,将非结构化数据转化为 embedding 向量,随后处理分析这些数据。
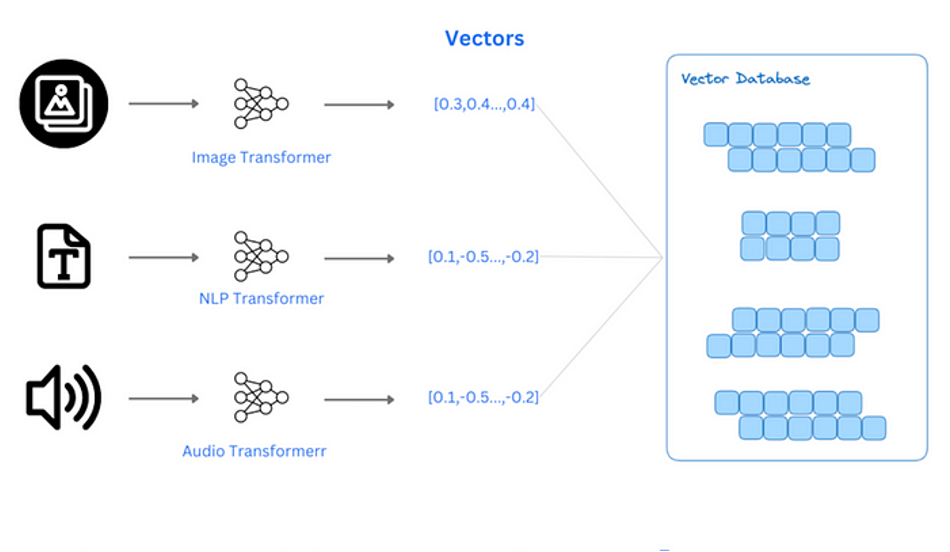
什么是向量检索?
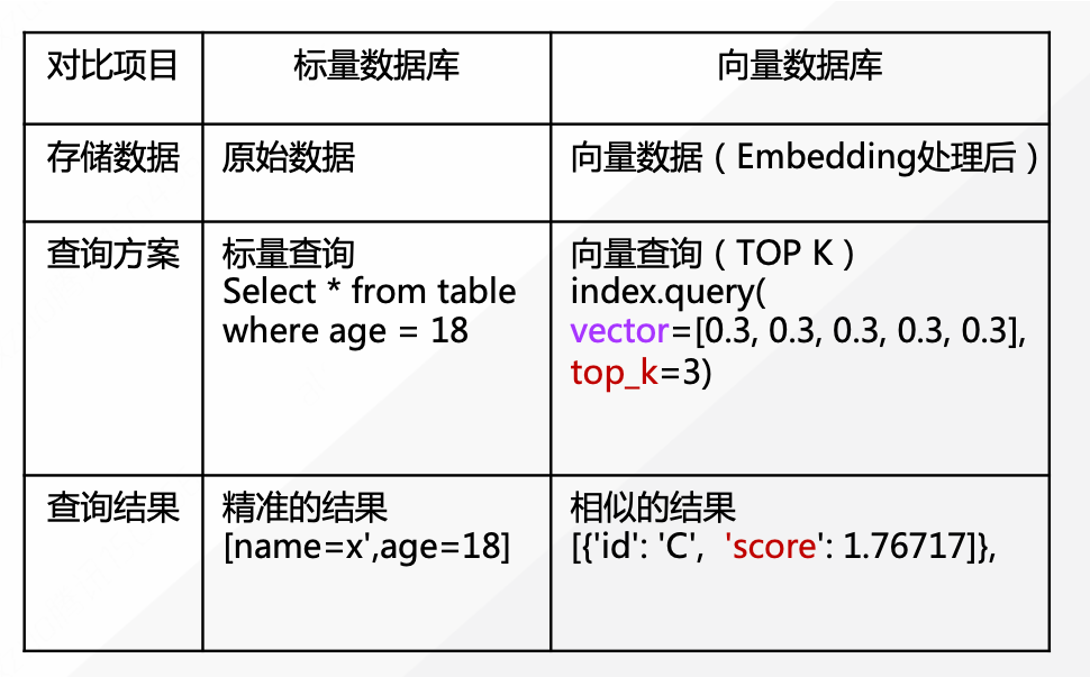
向量检索又称为近似最近邻搜索 (Approximate Nearest Neighbor Search, ANNS),是一种在大规模高维向量数据中寻找与给定查询向量相似的向量的技术。向量检索在许多 AI 领域具有广泛的应用,如图像检索、文本检索、语音识别、推荐系统等。向量检索与传统数据库检索有很大差别,传统数据库上的标量搜索主要针对结构化数据进行精确的数据查询,而向量搜索主要针对非结构化数据向量化之后的向量数据进行相似检索,只能近似获得最匹配的结果。
向量检索的应用场景
数据库拥有向量能力意味着数据库系统具备存储、查询和分析向量数据的能力。这些向量通常与复杂的数据分析、机器学习和数据挖掘任务相关。以下是数据库拥有向量处理能力后的应用场景:
-
生成式 AI 应用程序:这些数据库可以作为生成式 AI 应用程序的后端,使它们能够根据用户提供的查询获取最近邻结果,提高输出质量和相关性。
-
高级对象识别:它们对于开发识别不同数据集之间相似性的高级对象识别平台是无价的。这在抄袭检测、面部识别和 DNA 匹配等领域都有实际应用。
-
个性化推荐系统:矢量数据库可以通过整合用户偏好和选择来增强推荐系统。这将带来更准确、更有针对性的推荐,从而改善用户体验和参与度。
-
异常检测:向量数据库可以用来存储代表正常行为的特征向量。然后可以通过比较输入向量和存储向量来检测异常。这在网络安全和工业质量控制中很有用。
MatrixOne 的向量数据类型
在 MatrixOne 中,向量被设计成一种数据类型,它类似于编程语言中的 Array 数组 (MatrixOne 目前还不支持数组类型),但是是一种较为特殊的数组类型。首先,它是一个一维数组类型,意味着它不能用来构建 Matrix 矩阵。另外目前仅支持 float32 及 float64 类型的向量,分别称之为 vecf32 与 vecf64 而不支持字符串类型和整型类型的数字。
创建一个向量列时,我们可以指定向量列的维度大小,如 vecf32(3),这个维度即向量的数组的长度大小,最大可支持到 65,536 维度。
如何在 SQL 中使用向量类型
使用向量的语法与常规建表、插入数据、查询数据相同:
创建向量列
你可以按照下面的 SQL 语句创建了两个向量列,一个是 Float32 类型,另一个是 Float64 类型,并且可以将两个向量列的维度都设置为 3。
目前向量类型不能作为主键或者唯一键。
create table t1(a int, b vecf32(3), c vecf64(3));
插入向量
MatrixOne 支持以两种格式插入向量。
文本格式
insert into t1 values(1, "[1,2,3]", "[4,5,6]");
二进制格式
如果你想使用 Python NumPy 数组,可以通过对数组进行十六进制编码,而不是将其转换为逗号分隔的文本格式,直接将该 NumPy 数组插入 MatrixOne。在插入维度较高的向量时,这种方式速度更快。
insert into t1 (a, b) values
(2, decode("7e98b23e9e10383b2f41133f", "hex"));
-- "7e98b23e9e10383b2f41133f" 表示 []float32{0.34881967, 0.0028086076, 0.5752134}的小端十六进制编码
-- "hex" 表示十六进制编码
查询向量
向量列同样可以以两种格式读取。
文本格式
mysql> select a, b from t1;
+------+---------------------------------------+
| a | b |
+------+---------------------------------------+
| 1 | [1, 2, 3] |
| 2 | [0.34881967, 0.0028086076, 0.5752134] |
+------+---------------------------------------+
2 rows in set (0.00 sec)
二进制格式
如果你需要将向量结果集直接读取到 NumPy 数组中,以最小的转换成本,二进制格式非常有用。
mysql> select encode(b, "hex") from t1;
+--------------------------+
| encode(b, hex) |
+--------------------------+
| 0000803f0000004000004040 |
| 7e98b23e9e10383b2f41133f |
+--------------------------+
2 rows in set (0.00 sec)
支持的算子与函数
- 基本二元操作符:
+,-,*,/. - 比较操作符:
=,!=,>,>=,<,<=. - 一元函数:
sqrt,abs,cast. - 自动类型转换:
vecf32+vecf64=vecf64.vecf32+varchar=vecf32.
- 向量一元函数:
- 求和函数
summation, L1 范数函数l1_norm, L2 范数函数l2_norm, 维度函数vector_dims.
- 求和函数
- 向量二元函数:
- 内积函数
inner_product, 余弦相似度函数cosine_similarity.
- 内积函数
- 聚合函数:
count.
示例 - Top K 查询
Top K 查询是一种数据库查询操作,用于检索数据库中排名前 K 的数据项或记录。Top K 查询可以应用于各种应用场景,包括推荐系统、搜索引擎、数据分析和排序。
首先,我们创建了一个名为 t1 的表,其中包含了向量数据 b,并插入了一些示例数据。然后,我们使用给定的 SQL 语句执行基于 l1_distance、l2_distance、余弦相似度和余弦距离的 Top K 查询,将结果限制为前 5 个匹配项。
-- 包含向量数据'b'的示例表't1'
CREATE TABLE t1 (
id int,
b vecf64(3)
);
-- 插入一些示例数据
INSERT INTO t1 (id,b) VALUES (1, '[1,2,3]'), (2, '[4,5,6]'), (3, '[2,1,1]'), (4, '[7,8,9]'), (5, '[0,0,0]'), (6, '[3,1,2]');
-- 使用 l1_distance 进行 Top K 查询
SELECT * FROM t1 ORDER BY l1_norm(b - '[3,1,2]') LIMIT 5;
mysql> SELECT * FROM t1 ORDER BY l1_norm(b - '[3,1,2]') LIMIT 5;
+------+-----------+
| id | b |
+------+-----------+
| NULL | [3, 1, 2] |
| NULL | [2, 1, 1] |
| NULL | [1, 2, 3] |
| NULL | [0, 0, 0] |
| NULL | [4, 5, 6] |
+------+-----------+
5 rows in set (0.00 sec)
-- 使用 l2_distance 进行 Top K 查询
mysql> SELECT * FROM t1 ORDER BY l2_norm(b - '[3,1,2]') LIMIT 5;
+------+-----------+
| id | b |
+------+-----------+
| NULL | [3, 1, 2] |
| NULL | [2, 1, 1] |
| NULL | [1, 2, 3] |
| NULL | [0, 0, 0] |
| NULL | [4, 5, 6] |
+------+-----------+
5 rows in set (0.00 sec)
-- 使用余弦相似度进行 Top K 查询
mysql> SELECT * FROM t1 ORDER BY cosine_similarity(b, '[3,1,2]') LIMIT 5;
+------+-----------+
| id | b |
+------+-----------+
| NULL | [1, 2, 3] |
| NULL | [0, 0, 0] |
| NULL | [4, 5, 6] |
| NULL | [7, 8, 9] |
| NULL | [2, 1, 1] |
+------+-----------+
5 rows in set (0.00 sec)
-- 使用余弦距离进行 Top K 查询
mysql> SELECT * FROM t1 ORDER BY 1 - cosine_similarity(b, '[3,1,2]') LIMIT 5;
+------+-----------+
| id | b |
+------+-----------+
| NULL | [3, 1, 2] |
| NULL | [0, 0, 0] |
| NULL | [2, 1, 1] |
| NULL | [7, 8, 9] |
| NULL | [4, 5, 6] |
+------+-----------+
5 rows in set (0.00 sec)
这些查询演示了如何使用不同的距离度量和相似度度量来检索与给定向量 [3,1,2] 最相似的前 5 个向量。通过这些查询,你可以根据不同的度量标准找到与目标向量最匹配的数据。
最佳实践
-
向量类型转换:在将向量从一种类型转换为另一种类型时,建议同时指定维度。例如:
SELECT b + CAST("[1,2,3]" AS vecf32(3)) FROM t1;这种做法确保了向量类型转换的准确性和一致性。
-
使用二进制格式:为了提高整体插入性能,考虑使用二进制格式而不是文本格式。在转换为十六进制编码之前,确保数组采用小端序格式。以下是示例 Python 代码:
import binascii # 'value' 是一个 NumPy 对象 def to_binary(value): if value is None: return value # 小端序浮点数组 value = np.asarray(value, dtype='<f') if value.ndim != 1: raise ValueError('期望 ndim 为 1') return binascii.b2a_hex(value)这种方法可以显著提高数据插入的效率。