MatrixOne Architecture Design
MatrixOne Overview
MatrixOne is a future-oriented hyperconverged cloud & edge native DBMS that supports transactional, analytical, and streaming workload with a simplified and distributed database engine working across multiple datacenters, clouds, edges, and other heterogenous infrastructures. This combination of engines is called HSTAP.
As a redefinition of the HTAP database, HSTAP aims to meet all the needs of Transactional Processing (TP) and Analytical Processing (AP) within a single database. Compared with the traditional HTAP, HSTAP emphasizes its built-in streaming capability used for connecting TP and AP tables. This provides users with an experience that a database can be used just like a Big Data platform, with which many users are already familiar thanks to the Big Data boom. With minimal integration efforts, MatrixOne frees users from the limitations of Big Data and provides one-stop coverage for all TP and AP scenarios for enterprises.
MatrixOne Architecture
The MatrixOne architecture is as follows:
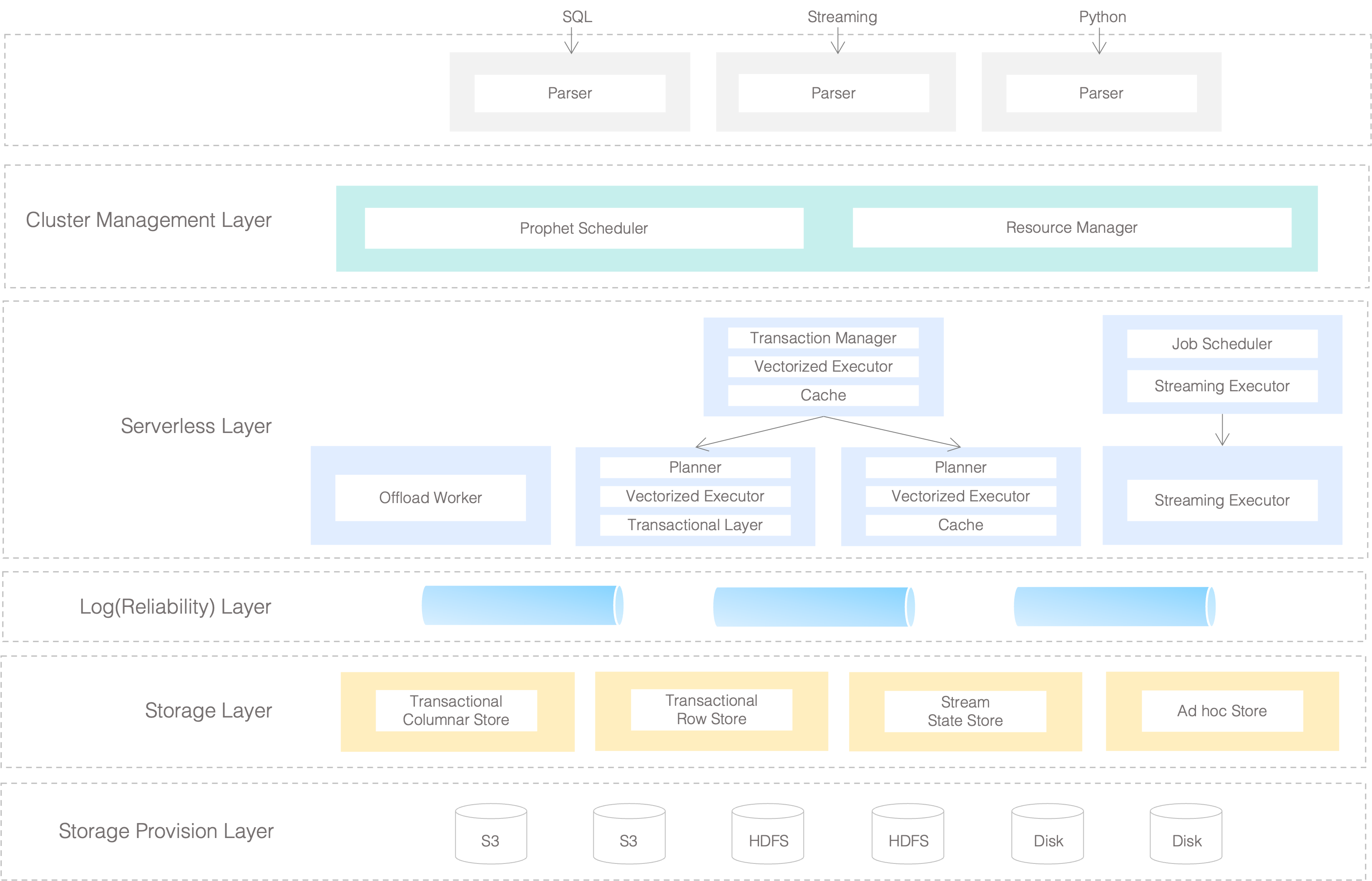
The architecture of MatrixOne is divided into several layers:
Cluster Management Layer
Being responsible for cluster management, it interacts with Kubernetes to obtain resources dynamically when in the cloud-native environment, while in the on-premises deployment, it gets hold of resources based on the configuration. Cluster status is continuously monitored with the role of each node allocated based on resource information. Maintenance works are carried out to ensure that all system components are up and running despite occasional node and network failures. It rebalances the loads on nodes when necessary as well. Major components in this layer are:
- Prophet Scheduler: take charge of load balancing and node keep-alive.
- Resource Manager: being responsible for physical resources provision.
Serverless Layer
Serverless Layer is a general term for a series of stateless nodes, which, as a whole, contains three categories:
- Background tasks: the most important one is called Offload Worker, which is responsible for offloading expensive compaction tasks and flushing data to S3 storage.
- SQL compute nodes: responsible for executing SQL requests, here divided into write nodes and read nodes. The former also provides the ability to read the freshest data.
- Stream task processing node: responsible for executing stream processing requests.
Log(Reliability) Layer
As MatrixOne's Single Source of Truth, data is considered as persistently stored in MatrixOne once it is written into the Log Layer. It is built upon our world-class expertise in the Replicated State Machine model to guarantee state-of-the-art high throughput, high availability, and strong consistency for our data. Following a fully modular and disaggregated design by itself, it is also the central component that helps to decouple the storage and compute layers. This in turn earns our architecture much higher elasticity when compared with traditional NewSQL architecture.
Storage Layer
The storage layer transforms the incoming data from the Log Layer into an efficient form for future processing and storage. This includes cache maintenance for fast accessing data that has already been written to S3. In MatrixOne, TAE (Transactional Analytic Engine) is the primary interface exposed by the Storage Layer, which can support both row and columnar storage together with transaction capabilities. Besides, the Storage Layer includes other internally used storage capabilities as well, e.g. the intermediate storage for streaming.
Storage Provision Layer
As an infrastructure agnostic DBMS, MatrixOne stores data in shared storage of S3 / HDFS, or local disks, on-premise servers, hybrid, and any cloud, or even smart devices. The Storage Provision Layer hides such complexity from upper layers by just presenting them with a unified interface for accessing such diversified storage resources.
MatrixOne System Components
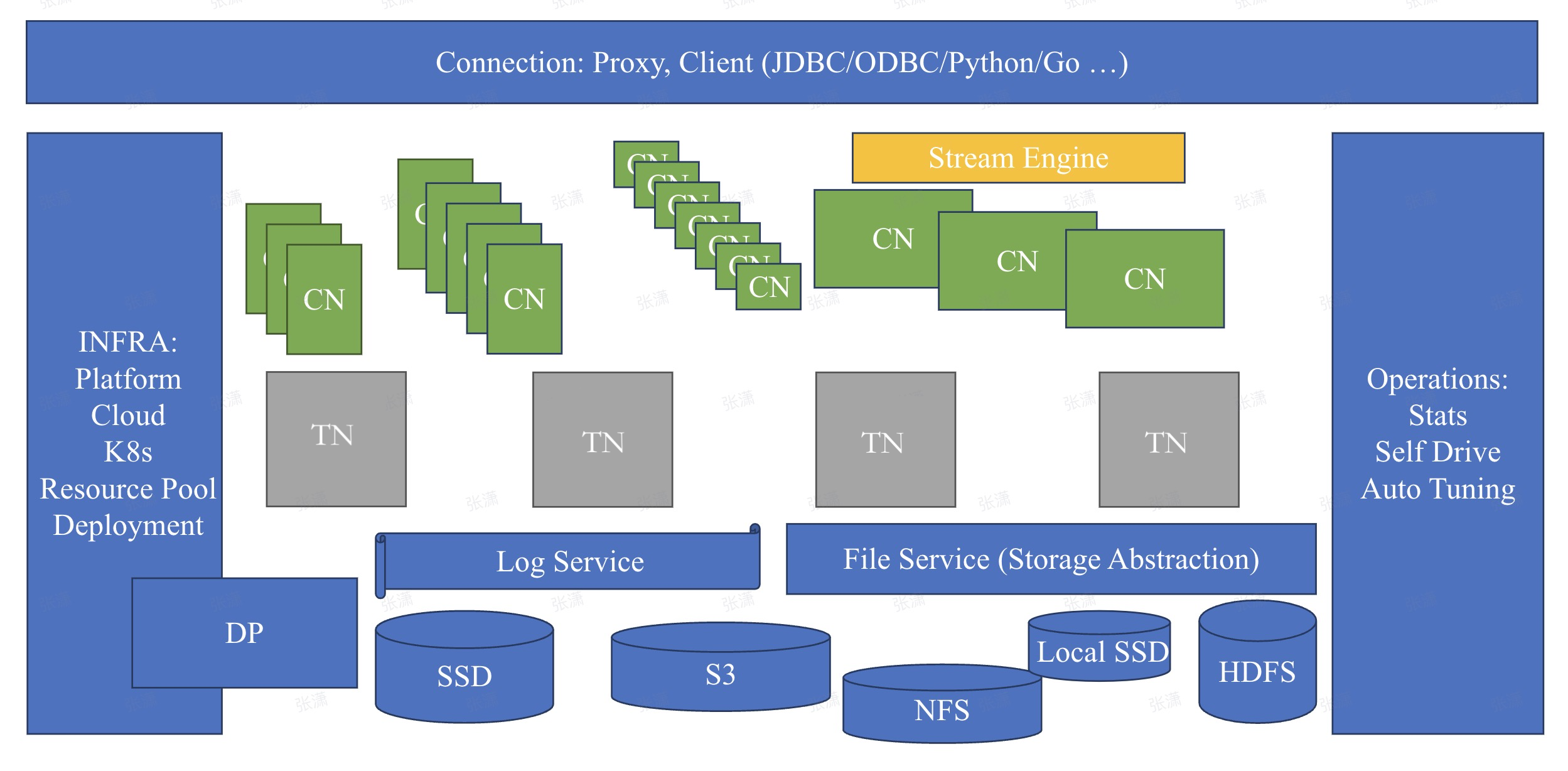
In MatrixOne, to achieve the integration of distributed and multi-engine, a variety of different system components are built to complete the functions of the architecture-related layers:
File Service
File Service is the component of MatrixOne responsible for reading and writing all storage media. Storage media include memory, disk, object storage, and so on., which provide the following features:
- File Service provides a unified interface so that reading and writing of different media can use the same interface.
- The design of the interface follows the concept of immutable data. After the file is written, no further updates are allowed. The update of the data is realized by generating a new file.
- This design simplifies operations such as data caching, migration, and verification and is conducive to improving the concurrency of data operations.
- Based on a unified read-write interface, File Service provides a hierarchical cache and a flexible cache strategy to balance read-write speed and capacity.
Log Service
Log Service is a component specially used to process transaction logs in MatrixOne, and it has the following features:
- The Raft protocol ensures consistency, and multiple copies are used to ensure availability.
- Save and process all transaction logs in MatrixOne, ensure that Log Service logs are read and written typically before the transaction is committed, and check and replay the log content when the instance is restarted.
- After the transaction is submitted and placed, truncate the content of the Log Service to control the size of the Log Service. The content that remains in the Log Service after truncation is called Logtail.
- If multiple Log Service copies are down at the same time, the entire MatrixOne will be down.
Database Node
The database node (DN) is the carrier used to run MatrixOne's distributed storage engine TAE, which provides the following features:
- Manage metadata information in MatrixOne and transaction log content saved in Log Service.
- Receive distributed transaction requests sent by Computing Node (CN), adjudicate the read and write requests of distributed transactions, push transaction adjudication results to CN, and push transaction content to Log Service to ensure the ACID characteristics of transactions.
- Generate a snapshot according to the checkpoint in the transaction to ensure the snapshot isolation of the transaction, and release the snapshot information after the transaction ends.
Computing Node
The computing node (CN) is a component of Matrixone that accesses user requests and processes SQL. The toolkit includes the following modules:
- Frontend, it handles the client SQL protocol, accepts the client's message, parses it to get the executable SQL of MatrixOne, calls other modules to execute the SQL, organizes the query results into a message, and returns it to the client.
- Plan, parse the SQL processed by Frontend, generate a logical execution plan based on MatrixOne's calculation engine and send it to Pipeline.
- Pipeline, which parses the logical plan, converts the logical plan into an actual execution plan and then runs the execution plan through Pipeline.
- Disttae, responsible for specific read and write tasks, including synchronizing Logtail from DN and reading data from S3, and sending the written data to DN.
Stream Engine
The streaming engine is a new component to ease the ETL process from OLTP to OLAP. It is planned in the MatrixOne roadmap but not implemented yet.
MatrixOne Features
In MatrixOne, it has the following features to make you more efficient in the process of using MatrixOne:
Distributed Architecture
In MatrixOne, the distributed storage and computing separation architecture is adopted. The separation of the storage, data, and computing layers enables MatrixOne to flexibly realize node expansion when encountering system resource bottlenecks. At the same time, resources can be allocated more efficiently under the multi-node architecture, avoiding hotspots and resource requisition to a certain extent.
Transactions and Isolation
In MatrixOne, transactions are isolated using optimistic transactions and snapshots.
Optimistic transactions can achieve better performance in a distributed architecture with fewer conflicts. At the same time, snapshot isolation with a higher isolation level can be achieved in terms of implementation. In order to ensure the ACID four elements of the transaction, MatrixOne currently supports and only supports one snapshot isolation level. Compared with the ordinary read-committed isolation level, this is stricter, which can effectively prevent dirty reads and better adapt to distributed optimistic transactions.
Cloud Native
MatrixOne is a cloud-native database. From the storage layer, it adapts to various storage methods such as local disks, AWS S3, and NFS and realizes non-aware management of multiple types of storage through File service. MatrixOne clusters can run stably in a variety of infrastructure environments, can adapt to private enterprise clouds, and provide services in different public cloud vendor environments.
Learn More
This page outlines the overall architecture design of MatrixOne. For information on other options that are available when trying out MatrixOne, see the following: