High Availability
The high availability of a database is a critical enterprise demand, ensuring the continuous availability of the system, data security, and business continuity. MatrixOne is a highly available distributed database that can meet enterprise demands. This document aims to introduce the high availability features of MatrixOne, including critical functions such as fault recovery, data redundancy, load balancing, and so on.
Business Requirements
The business demands high database availability mainly reflect the following aspects:
-
Continuous Availability: Enterprises need to ensure the continuous operation of their critical business databases to prevent long-term system interruptions or unavailability of services, thus ensuring business continuity and user satisfaction.
-
Fault Recovery: When a database failure occurs, it should quickly and automatically perform fault detection and switch to reduce the system downtime, ensuring the continuity and reliability of the service.
-
Data Protection and Recovery: Data is a vital enterprise asset, so regular database backups are needed, and quick data recovery is required to cope with accidental data loss or damage.
-
Cross-Regional Disaster Recovery: For critical businesses, it may be necessary to set up data centers in different geographical regions, implementing cross-regional disaster recovery to cope with natural disasters, network interruptions, or regional faults.
Advantages
MatrixOne uses erasure coding for data redundancy checks and synchronizes transaction logs using the Raft protocol. Only when a majority of nodes write successfully can the transaction be committed, ensuring the strong consistency of data and availability even when a minority of replicas fail. MatrixOne's high availability meets the level 4 standard in the finance industry (RPO=0, RTO<30min).
Architecture
The overall technical architecture of MatrixOne is shown in the figure below. We will introduce their high availability according to different component modules.
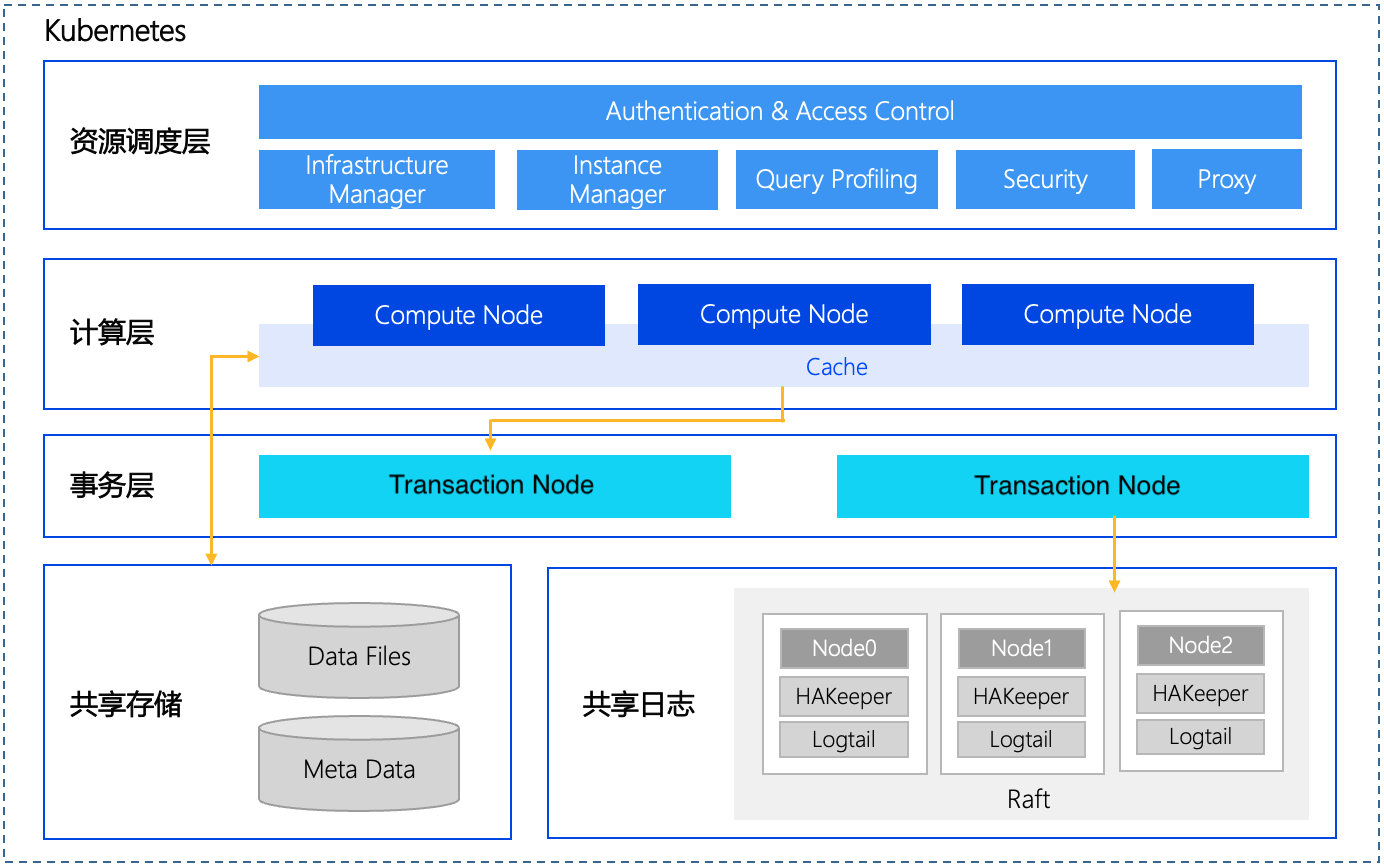
Resource Scheduling Layer
The technical architecture of MatrixOne is completely cloud-native. All technical components run on Kubernetes in a containerized form. The Kubernetes cluster can ensure continuous availability by adopting a multi-master and multi-slave deployment scheme. Specific deployment topology and system can refer to the Kubernetes official scheme.
Storage Layer
MatrixOne uses object storage in the storage layer and recommends deploying with Minio. MinIO, as a mature distributed object storage solution, needs to ensure the high availability of data services and the completeness and consistency of data files. The architecture of the MinIO cluster is distributed, storing data on multiple nodes, and providing high availability and fault tolerance. At the same time, the MinIO cluster uses Erasure Coding technology to ensure the reliability and availability of data. When a node fails, other nodes can use these coded replicas to recover lost data.
Shared Logs
The shared log component LogService is the only component in MatrixOne that holds distributed transaction status. This is a three-node architecture following the Raft protocol. Even if one node fails, it can still work typically. It is responsible for ensuring the final consistency of services for the entire MatrixOne cluster.
Transaction Layer
The transaction layer component Transaction node is responsible for conflict detection and arbitration of transaction operations. It is a stateless node. If a failure occurs, Kubernetes can pull it up at any time, and it can generally recover in seconds, ensuring continuous availability. The current version of Transaction node only supports single-node operation, and subsequent versions will add multiple Transaction node schemes to improve availability further.
Computation Layer
The computation layer component Compute Node is responsible for parsing front-end Queries, generating, and executing execution plans. It is also a stateless node. If a failure occurs, Kubernetes can pull it up at any time and generally recover in seconds, ensuring continuous availability.
Proxy
The Proxy component in the resource scheduling layer is responsible for grouping computation nodes CN to achieve load isolation and implement user connection level load balancing within the CN group. Proxy also runs in the form of multiple replicas backing each other up to ensure high availability.