Writing Real-Time Data to MatrixOne Using Flink
Overview
Apache Flink is a powerful framework and distributed processing engine focusing on stateful computation. It is suitable for processing both unbounded and bounded data streams efficiently. Flink can operate efficiently in various common cluster environments and performs calculations at memory speed. It supports processing data of any scale.
Scenarios
-
Event-Driven Applications
Event-driven applications typically have states and extract data from one or more event streams. They trigger computations, update states, or perform other external actions based on incoming events. Typical event-driven applications include anti-fraud systems, anomaly detection, rule-based alert systems, and business process monitoring.
-
Data Analytics Applications
The primary goal of data analytics tasks is to extract valuable information and metrics from raw data. Flink supports streaming and batch analytics applications, making it suitable for various scenarios such as telecom network quality monitoring, product updates, and experiment evaluation analysis in mobile applications, real-time ad-hoc analysis in the consumer technology space, and large-scale graph analysis.
-
Data Pipeline Applications
Extract, transform, load (ETL) is a standard method for transferring data between different storage systems. Data pipelines and ETL jobs are similar in that they can perform data transformation and enrichment and move data from one storage system to another. The difference is that data pipelines run in a continuous streaming mode rather than being triggered periodically. Typical data pipeline applications include real-time query index building in e-commerce and continuous ETL.
This document will introduce two examples. One involves using the Flink computing engine to write real-time data to MatrixOne, and the other uses the Flink computing engine to write streaming data to the MatrixOne database.
Before you start
Hardware Environment
The hardware requirements for this practice are as follows:
| Server Name | Server IP | Installed Software | Operating System | | node1 | 192.168.146.10 | MatrixOne | Debian11.1 x86 | | node2 | 192.168.146.12 | kafka | Centos7.9 | | node3 | 192.168.146.11 | IDEA,MYSQL | win10 |
Software Environment
This practice requires the installation and deployment of the following software environments:
- Install and start MatrixOne by following the steps in Install standalone MatrixOne.
- Download and install IntelliJ IDEA version 2022.2.1 or higher.
- Download and install Kafka 2.13 - 3.5.0.
- Download and install Flink 1.17.0.
- Download and install the MySQL Client 8.0.33.
Example 1: Migrating Data from MySQL to MatrixOne
Step 1: Initialize the Project
-
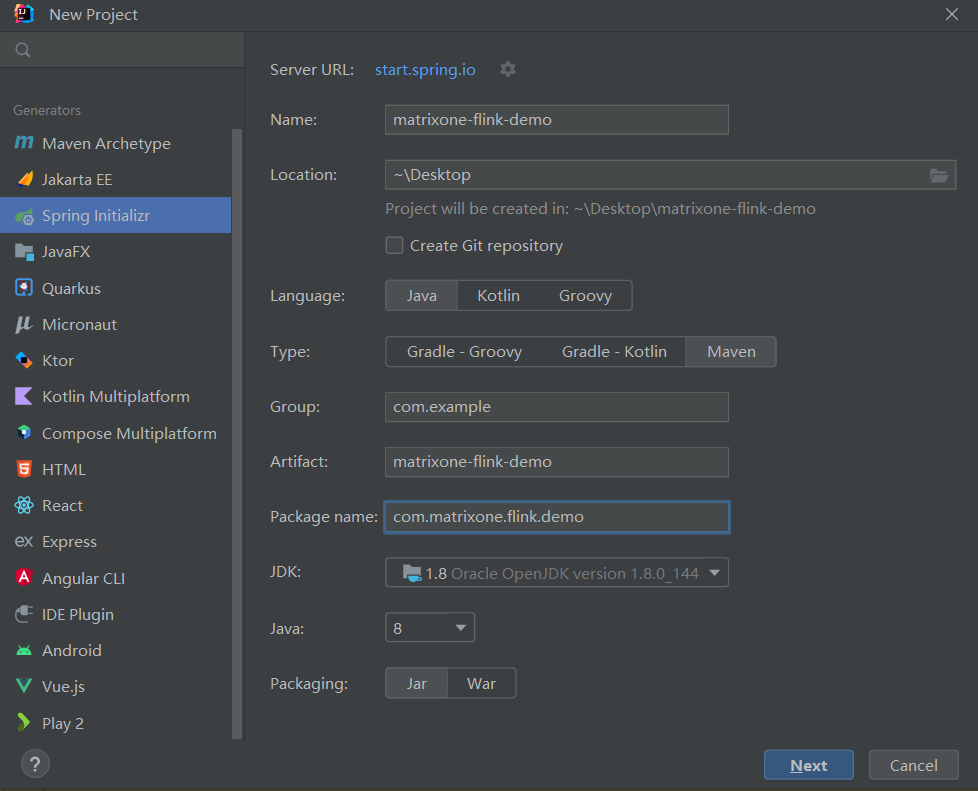
Start IDEA, click File > New > Project, select Spring Initializer, and fill in the following configuration parameters:
- Name:matrixone-flink-demo
- Location:~\Desktop
- Language:Java
- Type:Maven
- Group:com.example
- Artifact:matrixone-flink-demo
- Package name:com.matrixone.flink.demo
- JDK 1.8
-
Add project dependencies and edit the content of
pom.xmlin the project root directory as follows:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.matrixone.flink</groupId>
<artifactId>matrixone-flink-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<scala.binary.version>2.12</scala.binary.version>
<java.version>1.8</java.version>
<flink.version>1.17.0</flink.version>
<scope.mode>compile</scope.mode>
</properties>
<dependencies>
<!-- Flink Dependency -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hive_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<!--JDBC related dependency packages-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc</artifactId>
<version>1.15.4</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.33</version>
</dependency>
<!-- Kafka related dependency packages -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.13</artifactId>
<version>3.5.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>3.0.0-1.17</version>
</dependency>
<!-- JSON -->
<dependency>
<groupId>com.alibaba.fastjson2</groupId>
<artifactId>fastjson2</artifactId>
<version>2.0.34</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
<configuration>
<source>${java.version}</source>
<target>${java.version}</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.6</version>
<configuration>
<descriptorRefs>
<descriptor>jar-with-dependencies</descriptor>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
Step 2: Read MatrixOne Data
After connecting to MatrixOne using the MySQL client, create the necessary database and data tables for the demonstration.
-
Create a database, tables and import data in MatrixOne:
CREATE DATABASE test; USE test; CREATE TABLE `person` (`id` INT DEFAULT NULL, `name` VARCHAR(255) DEFAULT NULL, `birthday` DATE DEFAULT NULL); INSERT INTO test.person (id, name, birthday) VALUES(1, 'zhangsan', '2023-07-09'),(2, 'lisi', '2023-07-08'),(3, 'wangwu', '2023-07-12'); -
In IDEA, create the
MoRead.javaclass to read MatrixOne data using Flink:package com.matrixone.flink.demo; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.common.typeinfo.BasicTypeInfo; import org.apache.flink.api.java.ExecutionEnvironment; import org.apache.flink.api.java.operators.DataSource; import org.apache.flink.api.java.operators.MapOperator; import org.apache.flink.api.java.typeutils.RowTypeInfo; import org.apache.flink.connector.jdbc.JdbcInputFormat; import org.apache.flink.types.Row; import java.text.SimpleDateFormat; /** * @author MatrixOne * @description */ public class MoRead { private static String srcHost = "192.168.146.10"; private static Integer srcPort = 6001; private static String srcUserName = "root"; private static String srcPassword = "111"; private static String srcDataBase = "test"; public static void main(String[] args) throws Exception { ExecutionEnvironment environment = ExecutionEnvironment.getExecutionEnvironment(); // Set parallelism environment.setParallelism(1); SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd"); // Set query field type RowTypeInfo rowTypeInfo = new RowTypeInfo( new BasicTypeInfo[]{ BasicTypeInfo.INT_TYPE_INFO, BasicTypeInfo.STRING_TYPE_INFO, BasicTypeInfo.DATE_TYPE_INFO }, new String[]{ "id", "name", "birthday" } ); DataSource<Row> dataSource = environment.createInput(JdbcInputFormat.buildJdbcInputFormat() .setDrivername("com.mysql.cj.jdbc.Driver") .setDBUrl("jdbc:mysql://" + srcHost + ":" + srcPort + "/" + srcDataBase) .setUsername(srcUserName) .setPassword(srcPassword) .setQuery("select * from person") .setRowTypeInfo(rowTypeInfo) .finish()); // Convert Wed Jul 12 00:00:00 CST 2023 date format to 2023-07-12 MapOperator<Row, Row> mapOperator = dataSource.map((MapFunction<Row, Row>) row -> { row.setField("birthday", sdf.format(row.getField("birthday"))); return row; }); mapOperator.print(); } } -
Run
MoRead.Main()in IDEA, the result is as below: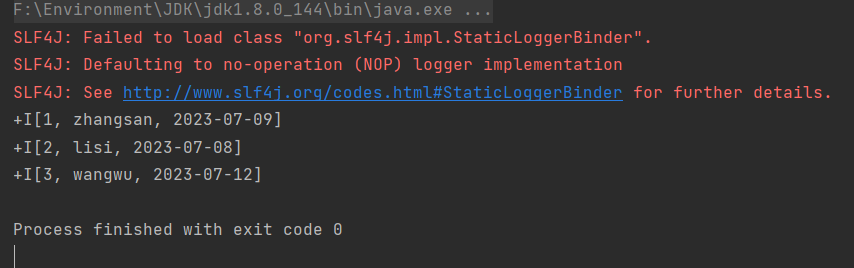
Step 3: Write MySQL Data to MatrixOne
Now, you can begin migrating MySQL data to MatrixOne using Flink.
-
Prepare MySQL data: On node3, use the MySQL client to connect to the local MySQL instance. Create the necessary database, tables, and insert data:
mysql -h127.0.0.1 -P3306 -uroot -proot mysql> CREATE DATABASE motest; mysql> USE motest; mysql> CREATE TABLE `person` (`id` int DEFAULT NULL, `name` varchar(255) DEFAULT NULL, `birthday` date DEFAULT NULL); mysql> INSERT INTO motest.person (id, name, birthday) VALUES(2, 'lisi', '2023-07-09'),(3, 'wangwu', '2023-07-13'),(4, 'zhaoliu', '2023-08-08'); -
Clear MatrixOne table data:
On node3, use the MySQL client to connect to the local MatrixOne instance. Since this example continues to use the
testdatabase from the previous MatrixOne data reading example, you need to clear the data from thepersontable first.-- On node3, use the MySQL client to connect to the local MatrixOne mysql -h192.168.146.10 -P6001 -uroot -p111 mysql> TRUNCATE TABLE test.person; -
Write code in IDEA:
Create the
Person.javaandMysql2Mo.javaclasses to use Flink to read MySQL data. Refer to the following example for theMysql2Mo.javaclass code:
package com.matrixone.flink.demo.entity;
import java.util.Date;
public class Person {
private int id;
private String name;
private Date birthday;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Date getBirthday() {
return birthday;
}
public void setBirthday(Date birthday) {
this.birthday = birthday;
}
}
package com.matrixone.flink.demo;
import com.matrixone.flink.demo.entity.Person;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
import org.apache.flink.api.java.typeutils.RowTypeInfo;
import org.apache.flink.connector.jdbc.*;
import org.apache.flink.streaming.api.datastream.DataStreamSink;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.types.Row;
import java.sql.Date;
/**
* @author MatrixOne
* @description
*/
public class Mysql2Mo {
private static String srcHost = "127.0.0.1";
private static Integer srcPort = 3306;
private static String srcUserName = "root";
private static String srcPassword = "root";
private static String srcDataBase = "motest";
private static String destHost = "192.168.146.10";
private static Integer destPort = 6001;
private static String destUserName = "root";
private static String destPassword = "111";
private static String destDataBase = "test";
private static String destTable = "person";
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
//Set parallelism
environment.setParallelism(1);
//Set query field type
RowTypeInfo rowTypeInfo = new RowTypeInfo(
new BasicTypeInfo[]{
BasicTypeInfo.INT_TYPE_INFO,
BasicTypeInfo.STRING_TYPE_INFO,
BasicTypeInfo.DATE_TYPE_INFO
},
new String[]{
"id",
"name",
"birthday"
}
);
// add srouce
DataStreamSource<Row> dataSource = environment.createInput(JdbcInputFormat.buildJdbcInputFormat()
.setDrivername("com.mysql.cj.jdbc.Driver")
.setDBUrl("jdbc:mysql://" + srcHost + ":" + srcPort + "/" + srcDataBase)
.setUsername(srcUserName)
.setPassword(srcPassword)
.setQuery("select * from person")
.setRowTypeInfo(rowTypeInfo)
.finish());
//run ETL
SingleOutputStreamOperator<Person> mapOperator = dataSource.map((MapFunction<Row, Person>) row -> {
Person person = new Person();
person.setId((Integer) row.getField("id"));
person.setName((String) row.getField("name"));
person.setBirthday((java.util.Date)row.getField("birthday"));
return person;
});
//set matrixone sink information
mapOperator.addSink(
JdbcSink.sink(
"insert into " + destTable + " values(?,?,?)",
(ps, t) -> {
ps.setInt(1, t.getId());
ps.setString(2, t.getName());
ps.setDate(3, new Date(t.getBirthday().getTime()));
},
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withDriverName("com.mysql.cj.jdbc.Driver")
.withUrl("jdbc:mysql://" + destHost + ":" + destPort + "/" + destDataBase)
.withUsername(destUserName)
.withPassword(destPassword)
.build()
)
);
environment.execute();
}
}
Step 4: View the Execution Results
Execute the following SQL in MatrixOne to view the execution results:
mysql> select * from test.person;
+------+---------+------------+
| id | name | birthday |
+------+---------+------------+
| 2 | lisi | 2023-07-09 |
| 3 | wangwu | 2023-07-13 |
| 4 | zhaoliu | 2023-08-08 |
+------+---------+------------+
3 rows in set (0.01 sec)
Example 2: Importing Kafka data to MatrixOne
Step 1: Start the Kafka Service
Kafka cluster coordination and metadata management can be achieved using KRaft or ZooKeeper. Here, we will use Kafka version 3.5.0, eliminating the need for a standalone ZooKeeper software and utilizing Kafka's built-in KRaft for metadata management. Follow the steps below to configure the settings. The configuration file can be found in the Kafka software's root directory under config/kraft/server.properties.
The configuration file is as follows:
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# This configuration file is intended for use in KRaft mode, where
# Apache ZooKeeper is not present. See config/kraft/README.md for details.
#
############################# Server Basics #############################
# The role of this server. Setting this puts us in KRaft mode
process.roles=broker,controller
# The node id associated with this instance's roles
node.id=1
# The connect string for the controller quorum
controller.quorum.voters=1@192.168.146.12:9093
############################# Socket Server Settings #############################
# The address the socket server listens on.
# Combined nodes (i.e. those with `process.roles=broker,controller`) must list the controller listener here at a minimum.
# If the broker listener is not defined, the default listener will use a host name that is equal to the value of java.net.InetAddress.getCanonicalHostName(),
# with PLAINTEXT listener name, and port 9092.
# FORMAT:
# listeners = listener_name://host_name:port
# EXAMPLE:
# listeners = PLAINTEXT://your.host.name:9092
#listeners=PLAINTEXT://:9092,CONTROLLER://:9093
listeners=PLAINTEXT://192.168.146.12:9092,CONTROLLER://192.168.146.12:9093
# Name of listener used for communication between brokers.
inter.broker.listener.name=PLAINTEXT
# Listener name, hostname and port the broker will advertise to clients.
# If not set, it uses the value for "listeners".
#advertised.listeners=PLAINTEXT://localhost:9092
# A comma-separated list of the names of the listeners used by the controller.
# If no explicit mapping set in `listener.security.protocol.map`, default will be using PLAINTEXT protocol
# This is required if running in KRaft mode.
controller.listener.names=CONTROLLER
# Maps listener names to security protocols, the default is for them to be the same. See the config documentation for more details
listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
# The number of threads that the server uses for receiving requests from the network and sending responses to the network
num.network.threads=3
# The number of threads that the server uses for processing requests, which may include disk I/O
num.io.threads=8
# The send buffer (SO_SNDBUF) used by the socket server
socket.send.buffer.bytes=102400
# The receive buffer (SO_RCVBUF) used by the socket server
socket.receive.buffer.bytes=102400
# The maximum size of a request that the socket server will accept (protection against OOM)
socket.request.max.bytes=104857600
############################# Log Basics #############################
# A comma separated list of directories under which to store log files
log.dirs=/home/software/kafka_2.13-3.5.0/kraft-combined-logs
# The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across
# the brokers.
num.partitions=1
# The number of threads per data directory to be used for log recovery at startup and flushing at shutdown.
# This value is recommended to be increased for installations with data dirs located in RAID array.
num.recovery.threads.per.data.dir=1
############################# Internal Topic Settings #############################
# The replication factor for the group metadata internal topics "__consumer_offsets" and "__transaction_state"
# For anything other than development testing, a value greater than 1 is recommended to ensure availability such as 3.
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
############################# Log Flush Policy #############################
# Messages are immediately written to the filesystem but by default we only fsync() to sync
# the OS cache lazily. The following configurations control the flush of data to disk.
# There are a few important trade-offs here:
# 1. Durability: Unflushed data may be lost if you are not using replication.
# 2. Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush.
# 3. Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to excessive seeks.
# The settings below allow one to configure the flush policy to flush data after a period of time or
# every N messages (or both). This can be done globally and overridden on a per-topic basis.
# The number of messages to accept before forcing a flush of data to disk
#log.flush.interval.messages=10000
# The maximum amount of time a message can sit in a log before we force a flush
#log.flush.interval.ms=1000
############################# Log Retention Policy #############################
# The following configurations control the disposal of log segments. The policy can
# be set to delete segments after a period of time, or after a given size has accumulated.
# A segment will be deleted whenever *either* of these criteria are met. Deletion always happens
# from the end of the log.
# The minimum age of a log file to be eligible for deletion due to age
log.retention.hours=72
# A size-based retention policy for logs. Segments are pruned from the log unless the remaining
# segments drop below log.retention.bytes. Functions independently of log.retention.hours.
#log.retention.bytes=1073741824
# The maximum size of a log segment file. When this size is reached a new log segment will be created.
log.segment.bytes=1073741824
# The interval at which log segments are checked to see if they can be deleted according
# to the retention policies
log.retention.check.interval.ms=300000
After the file configuration is completed, execute the following command to start the Kafka service:
#Generate cluster ID
$ KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"
#Set log directory format
$ bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c config/kraft/server.properties
#Start Kafka service
$ bin/kafka-server-start.sh config/kraft/server.properties
Step 2: Create a Kafka Topic
To enable Flink to read data from and write data to MatrixOne, we first need to create a Kafka topic named "matrixone." In the command below, use the --bootstrap-server parameter to specify the Kafka service's listening address as 192.168.146.12:9092:
$ bin/kafka-topics.sh --create --topic matrixone --bootstrap-server 192.168.146.12:9092
Step 3: Read MatrixOne Data
After connecting to the MatrixOne database, perform the following steps to create the necessary database and tables:
-
Create a database, and tables and import data in MatrixOne:
CREATE TABLE `users` ( `id` INT DEFAULT NULL, `name` VARCHAR(255) DEFAULT NULL, `age` INT DEFAULT NULL ) -
Write code in the IDEA integrated development environment:
In IDEA, create two classes:
User.javaandKafka2Mo.java. These classes read from Kafka and write data to the MatrixOne database using Flink.
package com.matrixone.flink.demo.entity;
public class User {
private int id;
private String name;
private int age;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
package com.matrixone.flink.demo;
import com.alibaba.fastjson2.JSON;
import com.matrixone.flink.demo.entity.User;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.AbstractDeserializationSchema;
import org.apache.flink.connector.jdbc.JdbcExecutionOptions;
import org.apache.flink.connector.jdbc.JdbcSink;
import org.apache.flink.connector.jdbc.JdbcStatementBuilder;
import org.apache.flink.connector.jdbc.internal.options.JdbcConnectorOptions;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.kafka.clients.consumer.OffsetResetStrategy;
import java.nio.charset.StandardCharsets;
/**
* @author MatrixOne
* @desc
*/
public class Kafka2Mo {
private static String srcServer = "192.168.146.12:9092";
private static String srcTopic = "matrixone";
private static String consumerGroup = "matrixone_group";
private static String destHost = "192.168.146.10";
private static Integer destPort = 6001;
private static String destUserName = "root";
private static String destPassword = "111";
private static String destDataBase = "test";
private static String destTable = "person";
public static void main(String[] args) throws Exception {
//Initialize environment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//Set parallelism
env.setParallelism(1);
//Set kafka source information
KafkaSource<User> source = KafkaSource.<User>builder()
//Kafka service
.setBootstrapServers(srcServer)
//Message topic
.setTopics(srcTopic)
//Consumer group
.setGroupId(consumerGroup)
//Offset When no offset is submitted, consumption starts from the beginning.
.setStartingOffsets(OffsetsInitializer.committedOffsets(OffsetResetStrategy.LATEST))
//Customized parsing message content
.setValueOnlyDeserializer(new AbstractDeserializationSchema<User>() {
@Override
public User deserialize(byte[] message) {
return JSON.parseObject(new String(message, StandardCharsets.UTF_8), User.class);
}
})
.build();
DataStreamSource<User> kafkaSource = env.fromSource(source, WatermarkStrategy.noWatermarks(), "kafka_maxtixone");
//kafkaSource.print();
//set matrixone sink information
kafkaSource.addSink(JdbcSink.sink(
"insert into users (id,name,age) values(?,?,?)",
(JdbcStatementBuilder<User>) (preparedStatement, user) -> {
preparedStatement.setInt(1, user.getId());
preparedStatement.setString(2, user.getName());
preparedStatement.setInt(3, user.getAge());
},
JdbcExecutionOptions.builder()
//default value is 5000
.withBatchSize(1000)
//default value is 0
.withBatchIntervalMs(200)
//Maximum attempts
.withMaxRetries(5)
.build(),
JdbcConnectorOptions.builder()
.setDBUrl("jdbc:mysql://"+destHost+":"+destPort+"/"+destDataBase)
.setUsername(destUserName)
.setPassword(destPassword)
.setDriverName("com.mysql.cj.jdbc.Driver")
.setTableName(destTable)
.build()
));
env.execute();
}
}
After writing the code, you can run the Flink task by selecting the Kafka2Mo.java file in IDEA and executing Kafka2Mo.Main().
Step 4: Generate data
You can add data to Kafka's "matrixone" topic using the command-line producer tools provided by Kafka. In the following command, use the --topic parameter to specify the topic to add to and the --bootstrap-server parameter to determine the listening address of the Kafka service.
bin/kafka-console-producer.sh --topic matrixone --bootstrap-server 192.168.146.12:9092
After executing the above command, you will wait for the message content to be entered on the console. Enter the message values (values) directly, with each line representing one message (separated by newline characters), as follows:
{"id": 10, "name": "xiaowang", "age": 22}
{"id": 20, "name": "xiaozhang", "age": 24}
{"id": 30, "name": "xiaogao", "age": 18}
{"id": 40, "name": "xiaowu", "age": 20}
{"id": 50, "name": "xiaoli", "age": 42}

Step 5: View execution results
Execute the following SQL query results in MatrixOne:
mysql> select * from test.users;
+------+-----------+------+
| id | name | age |
+------+-----------+------+
| 10 | xiaowang | 22 |
| 20 | xiaozhang | 24 |
| 30 | xiaogao | 18 |
| 40 | xiaowu | 20 |
| 50 | xiaoli | 42 |
+------+-----------+------+
5 rows in set (0.01 sec)