数据导出
MatrixOne Intelligence 支持将解析分段后的处理结果导出至 Dify,MatrixOne、标准 S3 及阿里云 OSS,进一步增强平台的数据集成能力,满足用户在多种存储系统中的接入需求,助力企业实现更高效的数据流转与管理。
导出到知识库
Dify
Note
此功能仅支持 Dify 高级付费账户或本地化部署(Self-hosted)用户使用。请确保您的账户或部署方式符合要求。
使用“导出到 Dify”功能前,您需要准备以下信息:
- API 服务器地址
- 云端版本填写:
https://api.dify.ai/v1 -
本地部署版本填写:您部署的 API 地址(建议启用 HTTPS)
-
API 密钥
登录 Dify 平台 → 进入“知识库”模块 → 打开“API 访问”页面 → 复制您的个人 API Token(访问令牌)
使用步骤如下:
- 确认您的 Dify 账户为高级会员,或使用的是本地化部署版本
- 登录 Dify 获取 API 地址与密钥
- 在导出配置页面填写上述信息
- 点击“测试连接”确保配置正确、网络畅通
注意事项:
- 请妥善保管 API 密钥,避免泄露
- 密钥具备访问和修改 Dify 知识库的权限,建议定期更换
- 如遇连接失败,请检查:
- 网络是否可访问 API 地址
- API 密钥是否正确且未过期
- 本地部署服务是否正常,是否启用了 HTTPS
导出到对象存储
OSS
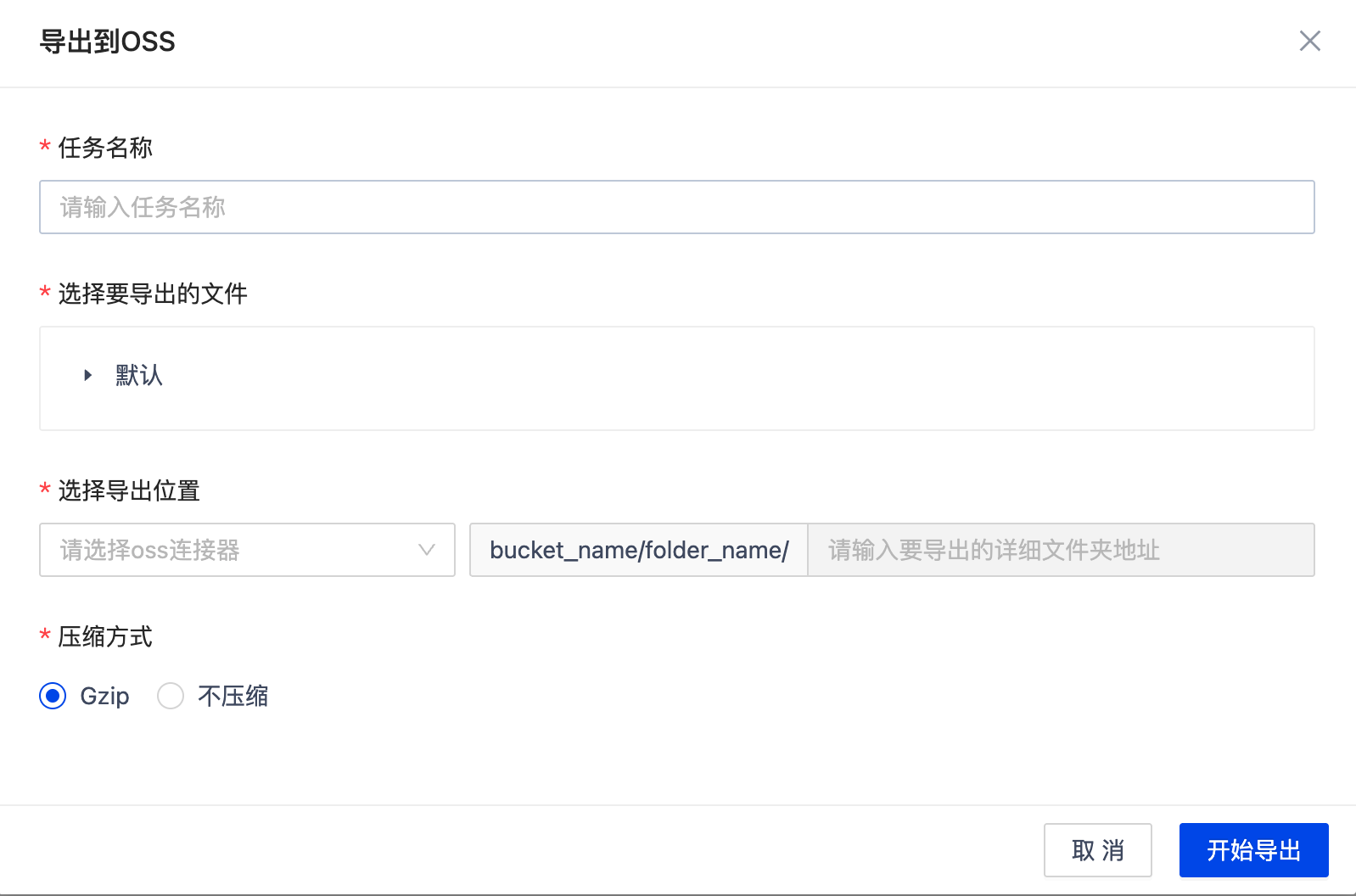
支持将处理后的数据导出到 OSS。导出时需指定以下信息:
- 选择导出的文件:选择要导出的已处理数据
- 选择导出位置:选择已创建的 OSS 连接器,填写在 OSS 中的具体文件夹地址
- 压缩方式:可选择是否启用 Gzip 压缩
导出完成后,数据将以原始或压缩格式写入指定的 OSS 路径中,供后续访问或集成使用。
标准 S3
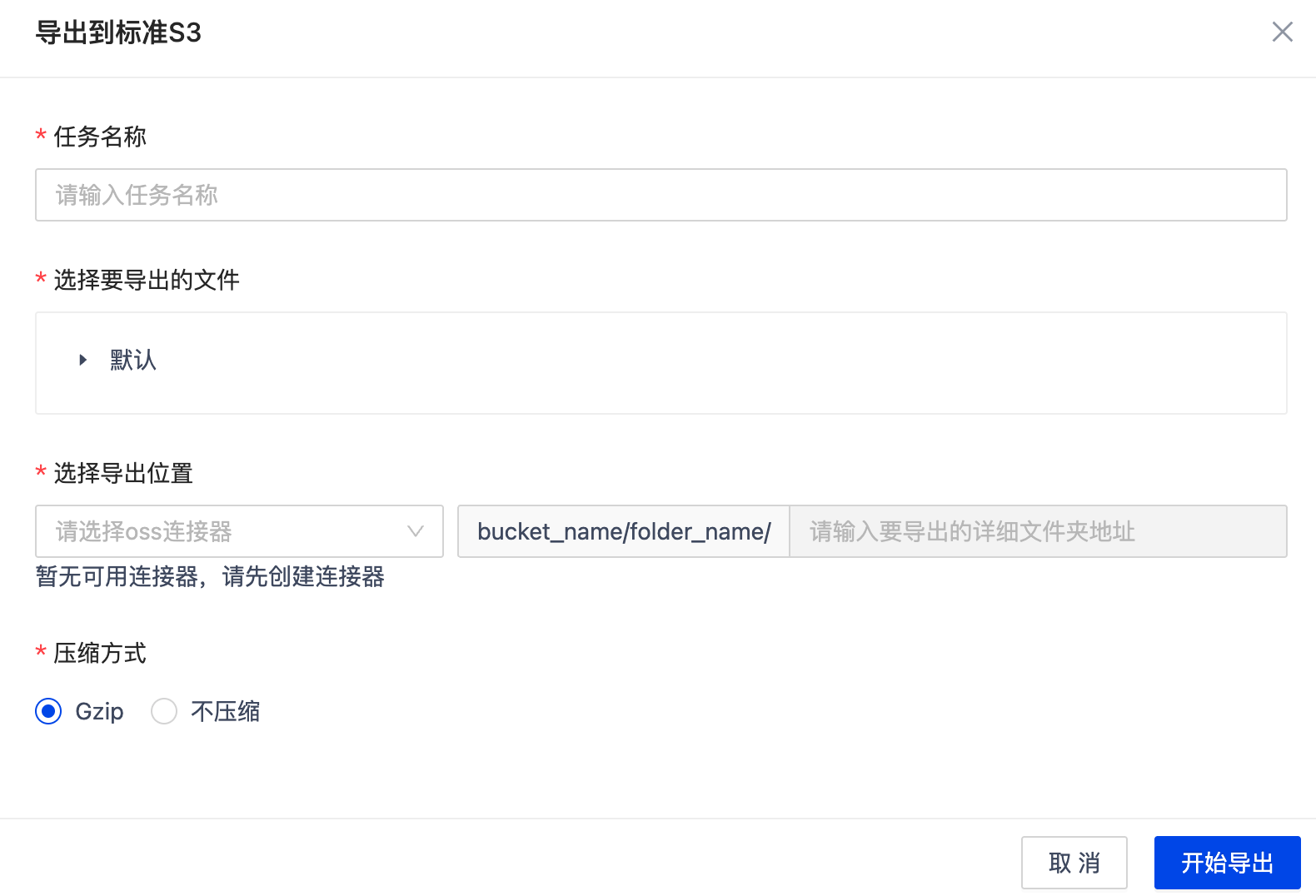
支持将处理后的数据导出至标准 S3 对象存储。导出前需配置以下信息:
- 选择导出的文件:选择需导出的已处理数据
- 选择导出位置:选择已创建的标准 S3 连接器,并填写目标路径(即 S3 中的具体文件夹地址)
- 压缩方式:可选择是否启用 Gzip 压缩导出
导出完成后,数据将以原始或压缩格式写入指定的 S3 路径,便于后续访问、共享或集成使用。
导出至数据库
MatrixOne
仅支持导出解析分段或提取后的 JSON 文件。
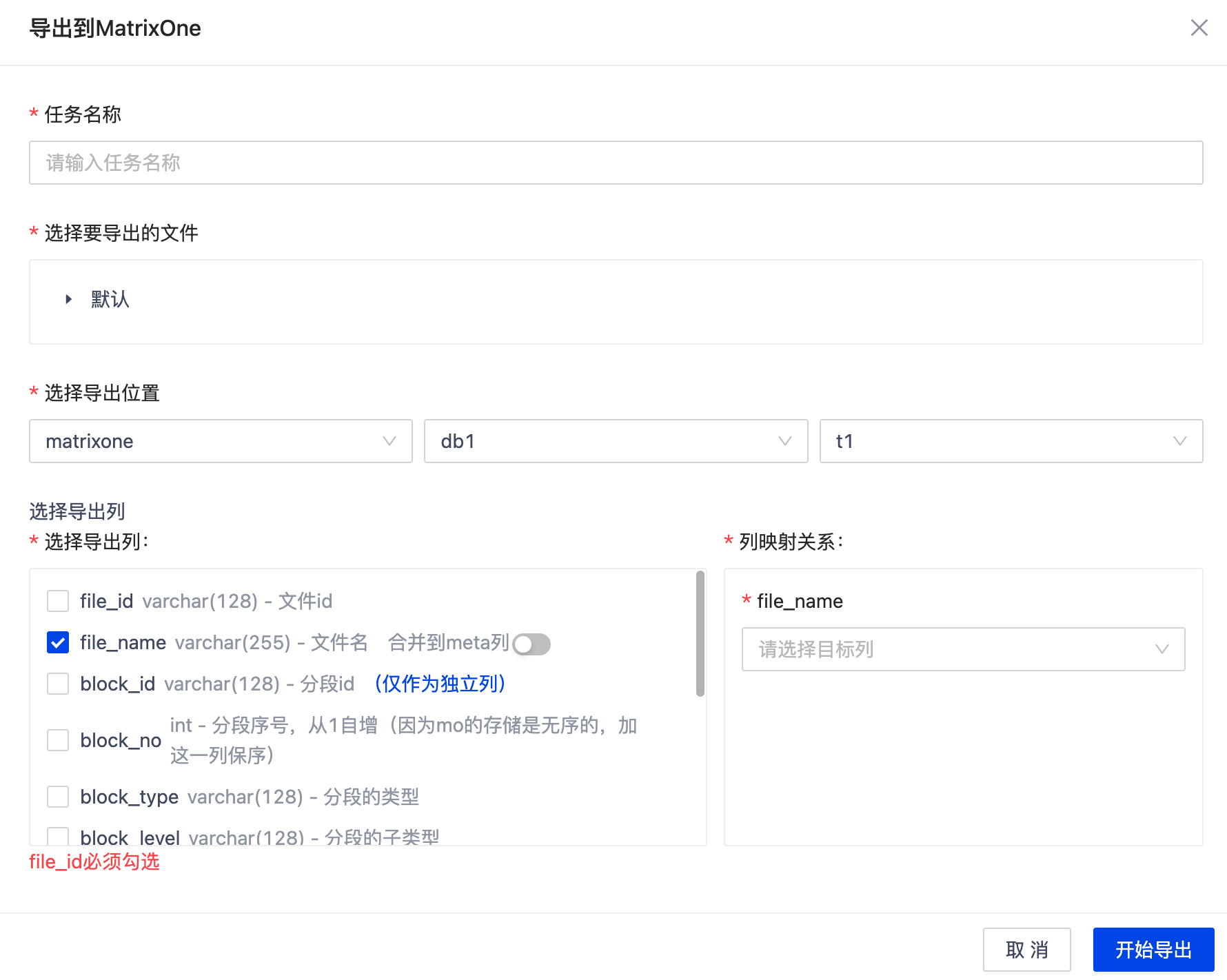
导出模式
-
已有数据表
- 追加写入
- 手动列映射(字段类型需兼容)
- 可选合并字段至
meta列
-
新建数据表
- 自动创建结构匹配的数据表
- 勾选所需导出列
必选字段
file_id(VARCHAR)block_id(VARCHAR)
可导出字段一览
| 列名 | 数据类型 | 含义说明 |
|---|---|---|
file_id |
VARCHAR(128) | 文件 ID |
file_name |
VARCHAR(255) | 文件名 |
block_id |
VARCHAR(128) | 分段 ID |
block_no |
INT | 分段序号(从 1 开始,用于排序) |
block_type |
VARCHAR(128) | 分段类型 |
block_level |
VARCHAR(128) | 分段子类型 |
page_no |
INT | 分段所在页码 |
content |
TEXT | 分段内容文本 |
embedding |
VECF64(1024) | 分段向量 |
image_data |
BLOB | 图片二进制数据 |
created_at |
DATETIME | 首次生成时间 |
updated_at |
DATETIME | 最后更新时间 |
meta |
JSON | 元信息(如文件信息、处理信息) |
重复文件处理策略
| 策略 | 描述 |
|---|---|
| 覆盖 | 用新的数据覆盖已存在的重复文件 |
| 跳过 | 保留现有数据,跳过重复文件 |
| 保留 | 重复数据共存(适用于非主键字段) |