法律知识微调数据生成
本模版提供一个完整的法律数据准备流程,帮助你基于法律文档构建高质量问答对数据集,并在 Hugging Face AutoTrain 平台上完成模型微调。适用于构建具备专业法律理解能力的定制大语言模型,如劳动争议、合同纠纷等法律场景问答应用。
模版详情
在模版列表点击查看详情进入模版详情页面。在模版详情页面,可以看到处理的效果示例图和工作流拓扑结构。
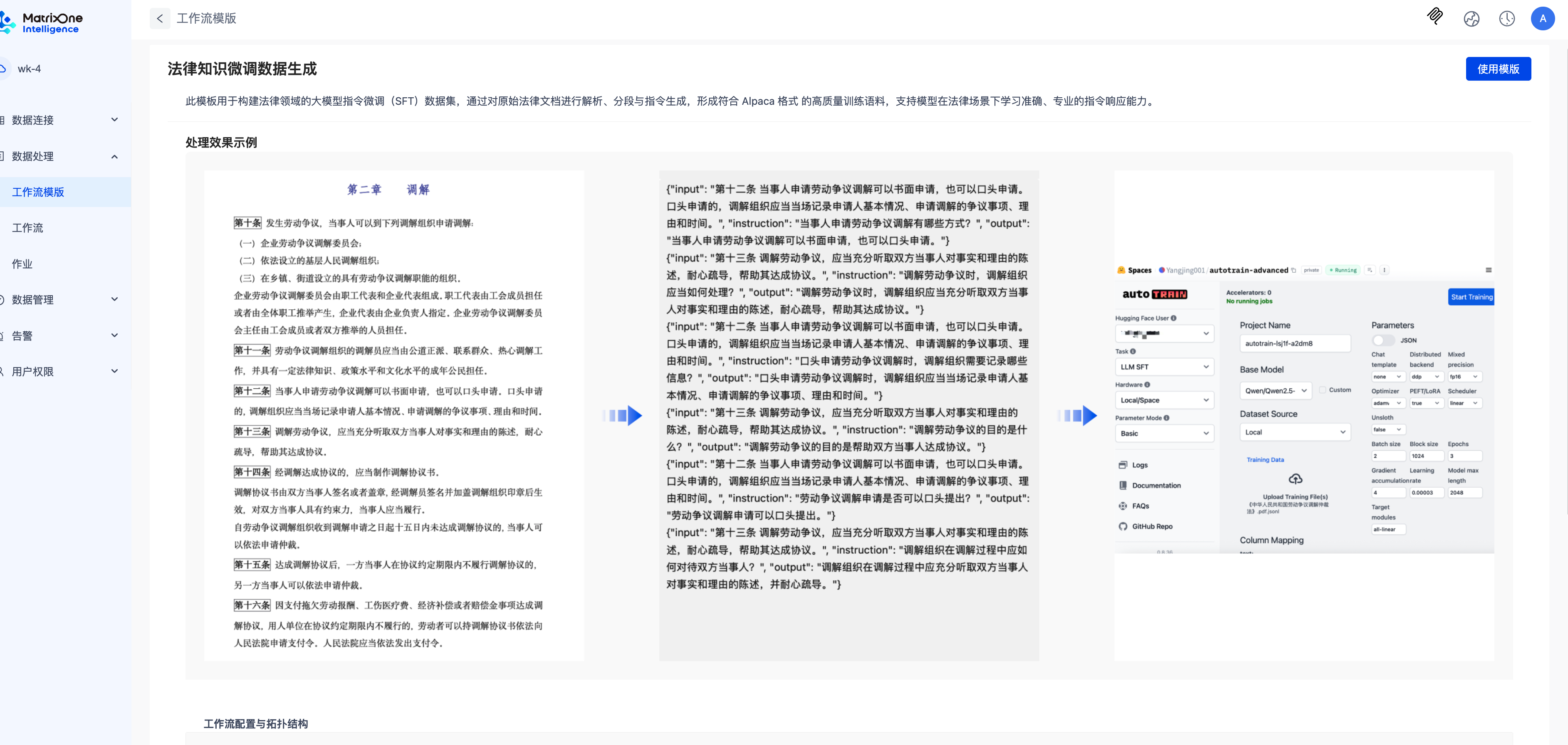
使用模版
- 在模版列表选择法律知识微调数据生成模版,在模版列表或详情页点击使用模版,即可创建数据处理任务并快速生成对应工作流。
- 系统内置示例数据,便于快速上手和测试。
- 需要自行创建目标位置
- 支持根据实际需求,自定义调整解析、增强等工作流节点配置。
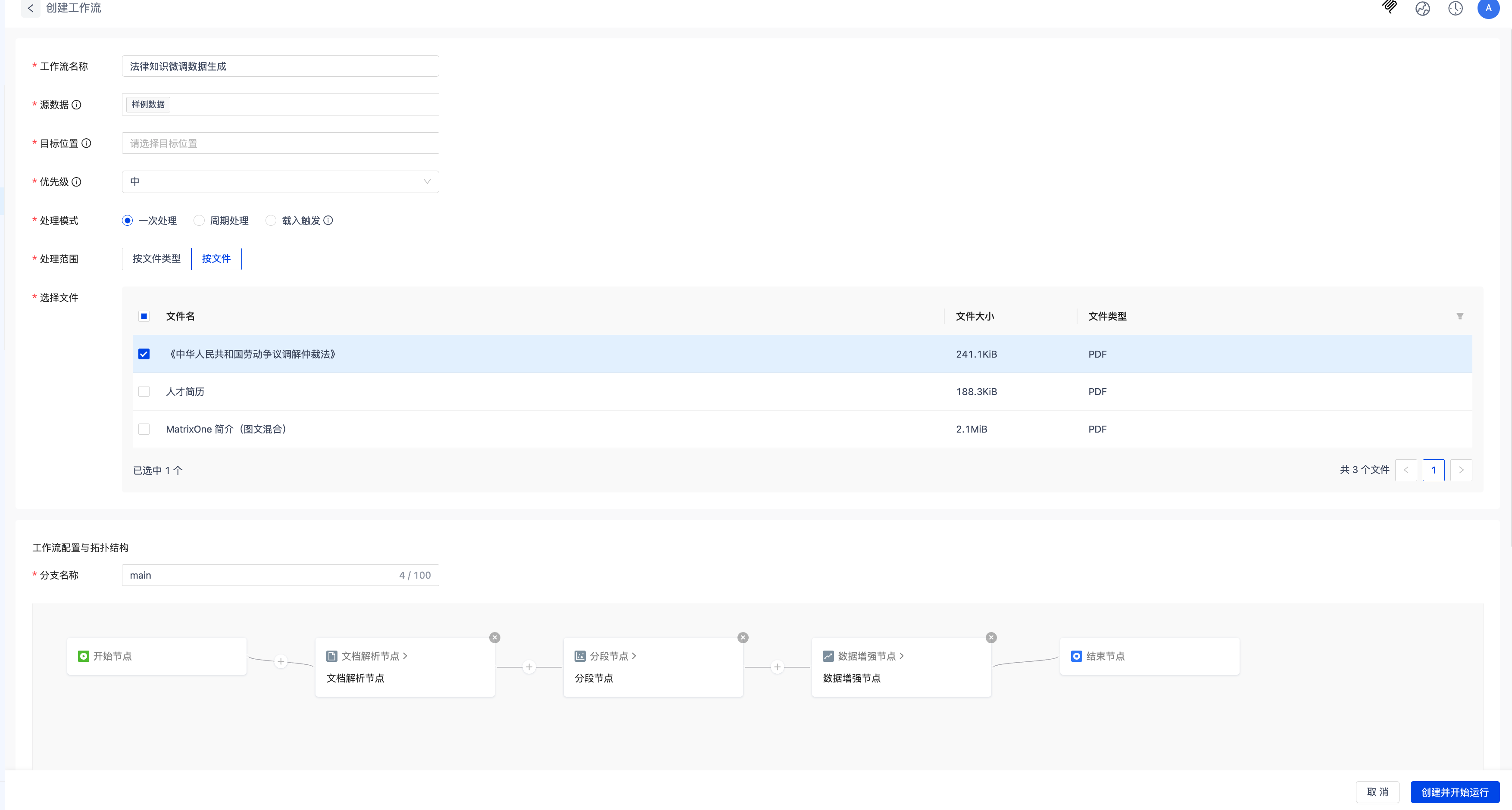
点击创建并开始运行,等待工作流运行完毕。
查看处理结果
导航至数据中心,找到刚才工作流中选择的目标位置,点击文件文件名,查看处理结果
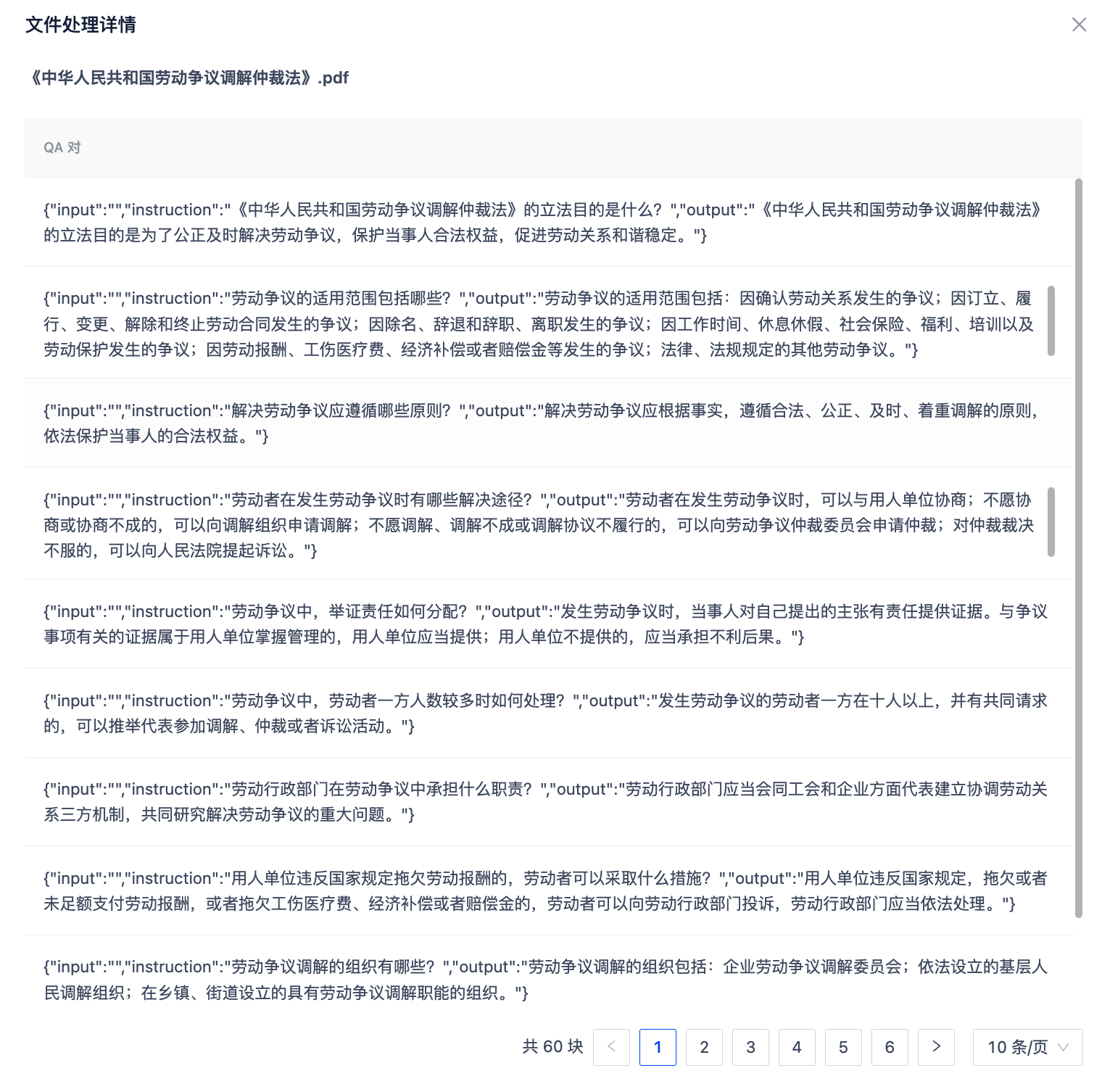
数据导出
处理完成后,可将数据集导出用于后续模型训练。这里我们直直接点击数据中心文件右侧的下载按钮,导出完成后,解压后你将获得一个如 中华人民共和国劳动争议调解仲裁法.pdf.jsonl 的标准问答对数据集。
模型微调(使用 Hugging Face AutoTrain)
我们将使用 Hugging Face 的 AutoTrain 平台,在线完成微调过程,零代码、全流程可视化。
- 访问 AutoTrain:https://huggingface.co/autotrain
- 创建项目:选择 Text Classification 或 Text Generation;
- 上传数据:将
《中华人民共和国劳动争议调解仲裁法》.pdf.jsonl上传至项目中; - 配置参数:设置训练轮数、学习率、基础模型(如 Mistral、Gemma 等);
- 启动训练:点击
Start Training开始模型微调。
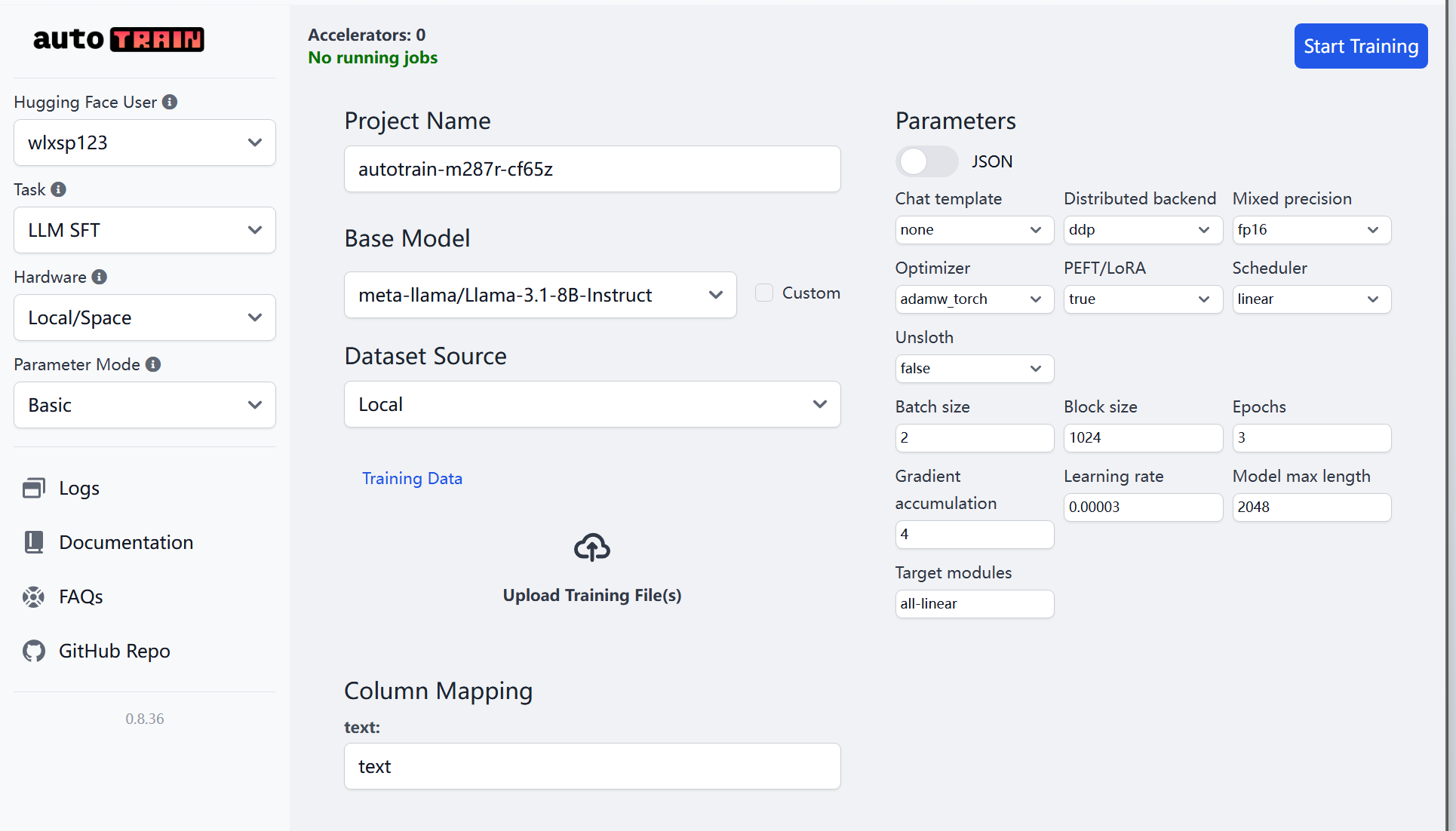
AutoTrain 将自动为你完成环境部署与训练过程。训练完成后,你将得到一个具备专业法律问答能力的微调模型,可直接部署或在平台中调用。