人才简历信息提取
本模版面向智能文档处理(IDP)场景,帮助构建自动化简历解析与结构化抽取流程,快速识别并提取简历中的关键信息,实现简历到数据库的高效转化,广泛应用于人才筛选、画像分析与智能招聘等业务。
模版详情
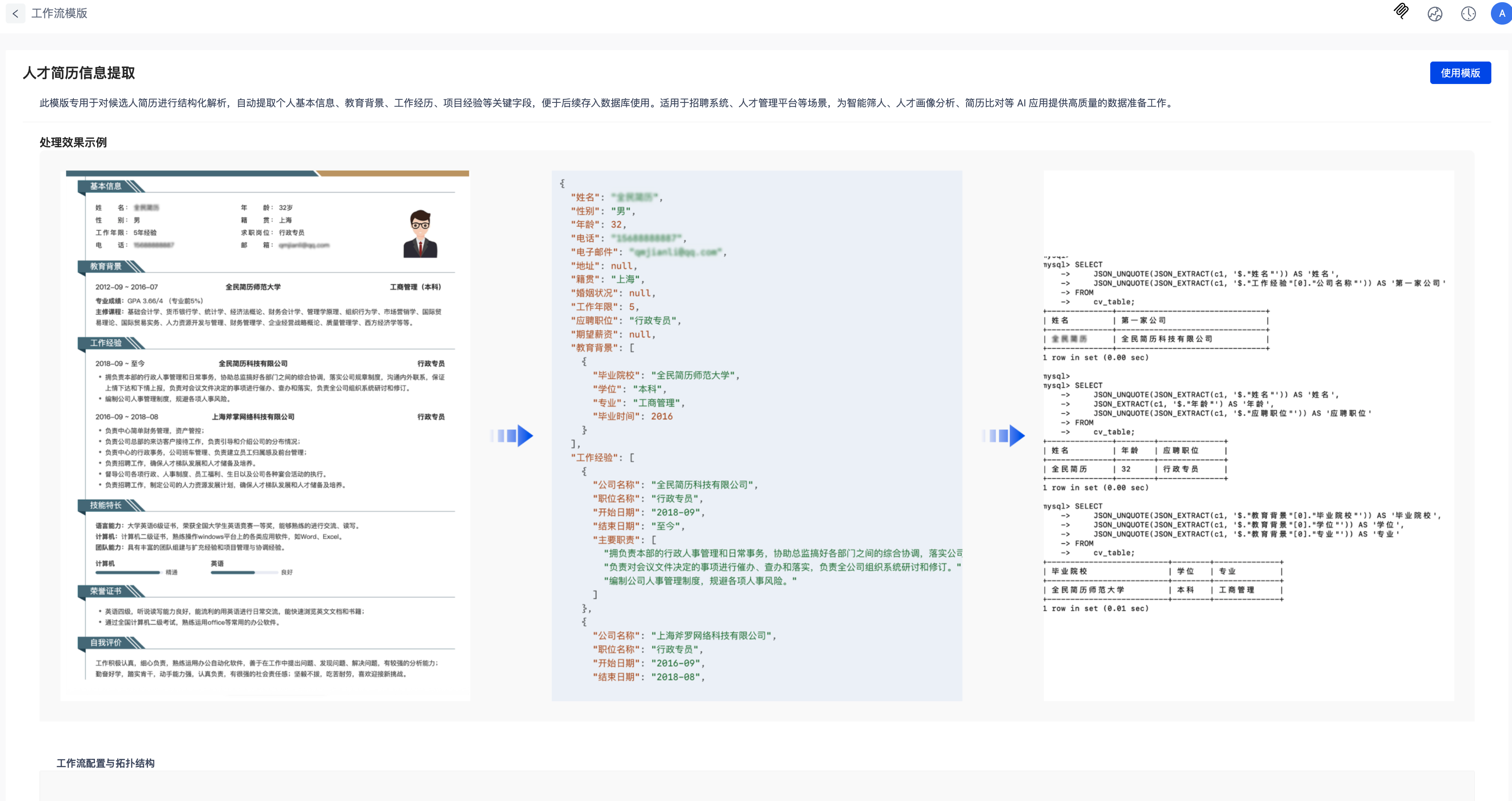
在模版列表点击查看详情进入模版详情页面。在模版详情页面,可以看到处理的效果示例图和工作流拓扑结构。
使用模版
- 在模版列表选择人才简历信息提取模版,在模版列表或详情页点击使用模版,即可创建数据处理任务并快速生成对应工作流。
- 系统内置示例数据,便于快速上手和测试。
- 需要自行创建目标位置
- 支持根据实际需求,自定义调整解析、提取等工作流节点配置。
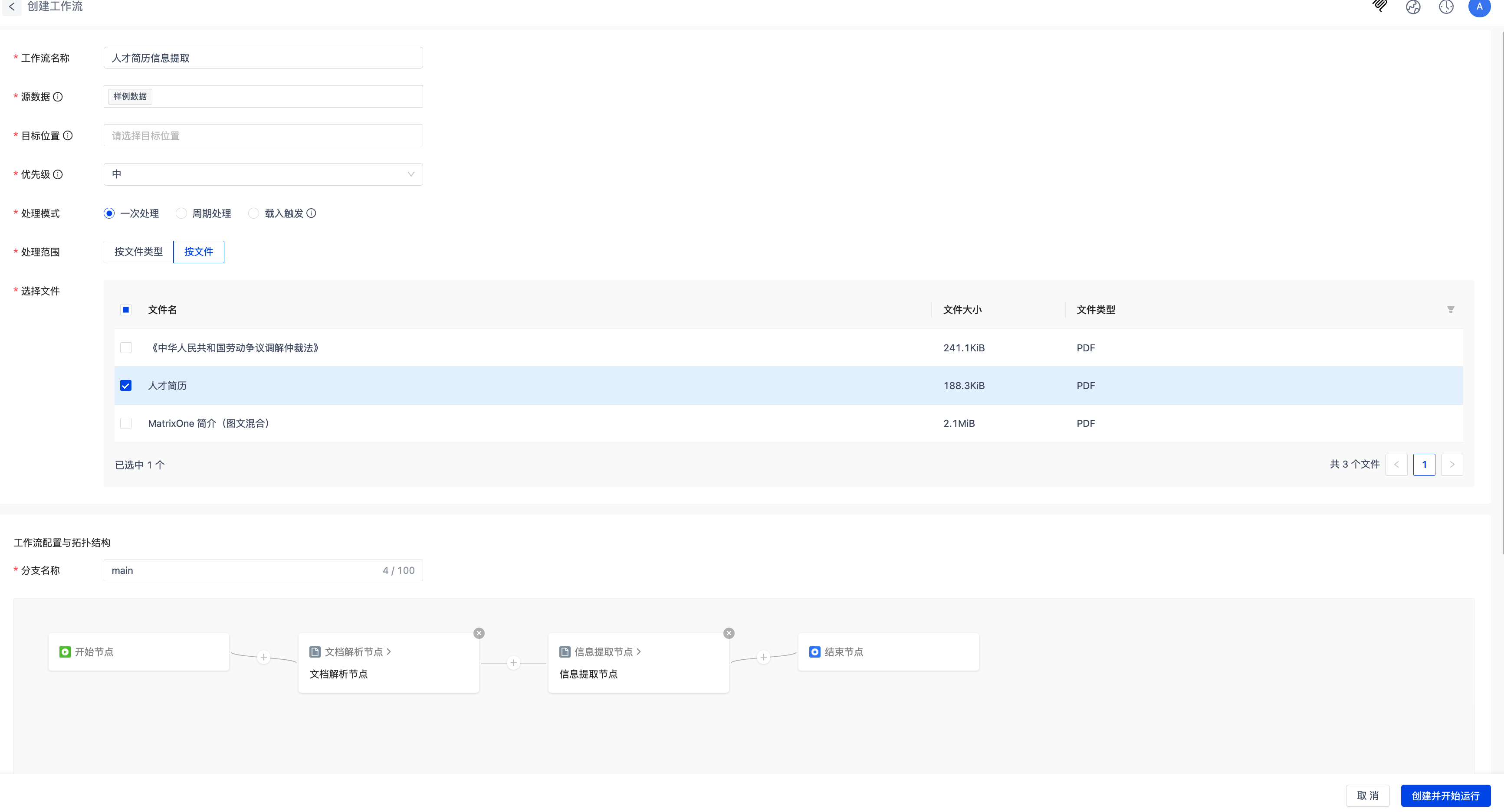
点击创建并开始运行,等待工作流运行完毕。
查看处理结果
导航至数据中心,找到刚才工作流中选择的目标位置,点击文件文件名,查看处理结果

数据导出
处理完成后,可将提取后的 json 文档导出用于后续的检索。这里我们直直接点击数据中心文件右侧的下载按钮,导出完成后,解压后你将获得一个如 人才简历.pdf.json 的 json 文件。
信息查询
完成导出后,可将 json 文件存到数据库通过 SQL 查询调用人才数据,实现多维筛选与分析,以下以 MatrixOne 为例,如果你还没有 MatrixOne 实例,可以参考快速创建数据库实例来创建您的数据库实例:
完成数据导出后,可将 JSON 文件导入数据库,以便通过 SQL 查询直接调用人才数据,实现多维度的筛选与分析。以下示例基于 MatrixOne 数据库进行演示。若您尚未创建 MatrixOne 实例,可参考快速创建数据库实例完成环境搭建。
连接实例创建表:
mysql> CREATE TABLE my_json_data (
-> id INT AUTO_INCREMENT PRIMARY KEY,
-> content JSON
-> );
Query OK, 0 rows affected (0.34 sec)
接下来,新建一个 my_data.py 脚本,用于实现 JSON 数据的插入与查询功能。
import json
import pymysql
# 读取 JSON 文件
with open("/Users/admin/Downloads/人才简历.pdf-0198acba-2183-7291-9b9c-d32d5c3eb9f5/人才简历.pdf.json", "r", encoding="utf-8") as f:
json_data = json.load(f)
# 连接 MatrixOne
conn = pymysql.connect(
host="xxx",
port=6001,
user="01946e41-6c67-7246-b36a-72619e9fxxxx:admin:accountadmin",
password="xxx",
database="db1",
charset="utf8mb4"
)
cursor = conn.cursor()
# 插入 JSON 数据
insert_sql = "INSERT INTO my_json_data (content) VALUES (%s)"
cursor.execute(insert_sql, (json.dumps(json_data, ensure_ascii=False),))
conn.commit()
print("✅ JSON 数据已插入 MatrixOne")
# 查询
query_sql = """
SELECT
JSON_UNQUOTE(JSON_EXTRACT(content, '$."姓名"')) AS '姓名',
JSON_EXTRACT(content, '$."年龄"') AS '年龄',
JSON_UNQUOTE(JSON_EXTRACT(content, '$."求职意向"')) AS '应聘职位'
FROM my_json_data;
"""
cursor.execute(query_sql)
rows = cursor.fetchall()
# 输出
print("\n🎯 查询结果:")
for name, age, job in rows:
print(f"姓名:{name}, 年龄:{age}, 应聘职位:{job}")
# 关闭
cursor.close()
conn.close()
运行脚本
>python my_data.py
✅ JSON 数据已插入 MatrixOne
🎯 查询结果:
姓名: 全民简历, 年龄: 32, 应聘职位: 行政专员