Here's an explanation of MatrixOne Intelligence's vector capabilities, including what vectors are, their applications, related concepts, and a practical example of building a RAG application.
Getting Started with Vector Capabilities
This article introduces the vector data features of MatrixOne Intelligence and their applications in relevant domains, aiming to provide users with an entry-level best practice guide.
What are Vectors?
In a database, avector typically represents a one-dimensional array or list where each element is a floating-point or integer number. Vectors can represent various types of data, such as text, images, audio, etc., by transforming these data into vectors through feature extraction techniques.
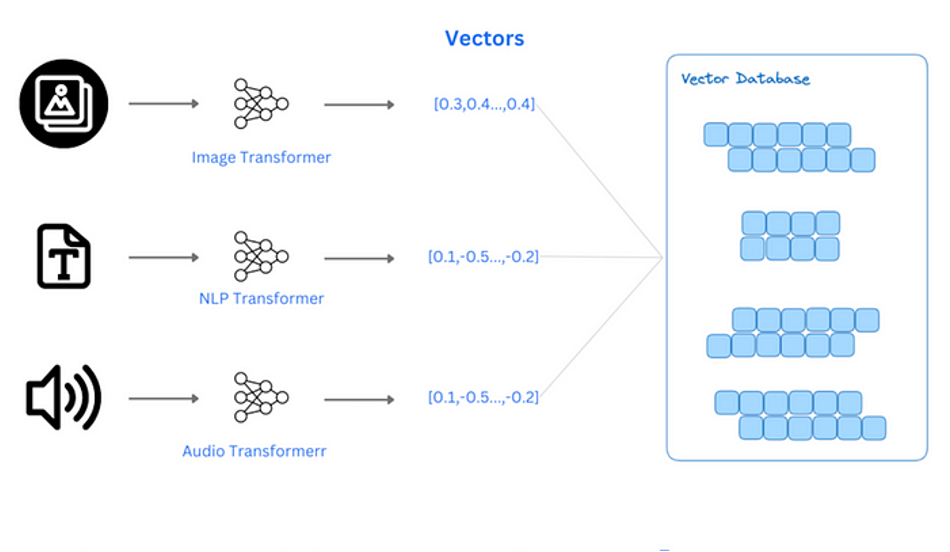
Application Scenarios
Natural Language Processing*: In text databases, vector representation can be used to represent the semantics of text or words. Through word embedding techniques, each word or document can be represented as a vector, allowing the database to perform efficient semantic search or classification based on these vectors. Recommendation Systems: Vectors are used in recommendation systems to represent users and items. By calculating the similarity between user vectors and item vectors, personalized recommendation lists can be generated. Clustering and Classification: Vectors in databases are also used for clustering and classification tasks. Database systems can automatically group or classify data based on vector similarity to discover potential patterns and relationships within the data. *Multimodal Data Processing: Vector representation is also widely applied to processing multimodal data, i.e., scenarios combining different types of data (such as images, text, audio). Vectorized representation allows data from different modalities to be compared and computed in the same space.
Related Concepts
*Vector Type: In a database, a vector type usually refers to a specialized data type used to represent and store vectors.
*Vector Search: Vector search is a retrieval method that compares similarities between vectors. It uses distance measurement algorithms to find vectors most similar to a given query vector. Common distance measures include Euclidean distance (L2 distance), cosine similarity, and inner product. Unlike traditional database retrieval, which primarily focuses on precise data queries for structured data, vector search mainly performs similarity retrieval on vectorized unstructured data, providing only approximate matches.
<div align="center">
<img src=https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/mocdocs/get-started/vecter-vs-scale.png width=80% heigth=80%/>
</div>
* Traditional databases store raw data. For example, user data might be saved in a table format, including fields like name, age, etc. Queries return exact matches. For instance, querying for the age of `name = 'tom'` yields an exact return.
* Vector databases store processed vector data (usually Embedding vectors). These vectors represent the data's position in a high-dimensional space and are used for similarity retrieval. Such queries return records most similar to a given vector, typically as "Top K" most similar results. The results are approximate matches, not exact matches. For example, comparing a table's vectors to the vector `[1,2,1]` returns content most similar to the given vector, such as `[content=pears]`.
*Vector Index: A vector index is an indexing technique specifically designed to handle vector data, aiming to improve the efficiency of high-dimensional vector data retrieval. It allows the database to quickly find vectors most similar to a query vector within a large dataset.
Vector Types
In MatrixOne Intelligence, vectors are defined as a special one-dimensional data type, similar to arrays in programming. However, currently,only float32 and float64 numerical types are supported, represented as vecf32 and vecf64 respectively. When creating a vector column, you can specify its dimension, for example, vecf32(3), which means the vector has a length of 3. The maximum supported dimension is 65,535. String or integer vector types are not supported.
create table t1(a int, b vecf32(3), c vecf64(3));
insert into t1 values(1, "[1,2,3]", "[4,5,6]");
mysql> select * from t1;
+------+-----------+-----------+
| a | b | c |
+------+-----------+-----------+
| 1 | [1, 2, 3] | [4, 5, 6] |
+------+-----------+-----------+
1 row in set (0.01 sec)
Vector Search
MatrixOne Intelligence supports various vector similarity functions, such as commoncosine similarity, Euclidean distance (L2 distance), and inner product.
create table vec_table(a int, b vecf32(3), c vecf64(3));
insert into vec_table values(1, "[1,2,3]", "[4,5,6]");
-- 1. Use cosine similarity function for similarity search
mysql> select cosine_similarity(b,"[1,5,6]") from vec_table;
+-------------------------------+
| cosine_similarity(b, [1,5,6]) |
+-------------------------------+
| 0.9843241382880896 |
+-------------------------------+
1 row in set (0.00 sec)
-- 2. Use Euclidean distance function for similarity search
mysql> select l2_distance(b,"[1,5,6]") from vec_table;
+-------------------------+
| l2_distance(b, [1,5,6]) |
+-------------------------+
| 4.242640687119285 |
+-------------------------+
1 row in set (0.01 sec)
-- 3. Use inner product function for similarity search
mysql> select inner_product(b,"[1,5,6]") from vec_table;
+---------------------------+
| inner_product(b, [1,5,6]) |
+---------------------------+
| 29 |
+---------------------------+
1 row in set (0.00 sec)
Vector Index
Vector indexes can efficiently find and retrieve similar vectors in large datasets. Currently, MatrixOne Intelligence supportsIVFFLAT vector indexes with Euclidean distance (L2 distance).
create table vec_table(a int, b vecf32(3), c vecf64(3));
insert into vec_table values(1, "[1,2,3]", "[4,5,6]");
# The parameter experimental_ivf_index must be set to 1 (default 0) to use vector indexes. This takes effect after reconnecting to the database.
SET GLOBAL experimental_ivf_index = 1;
# Create a vector index on the vector column, set the number of partitions to 1, and use Euclidean distance.
create index ivf_idx1 using ivfflat on vec_table(b) lists=1 op_type "vector_l2_ops";
Application Example: Building a RAG Application
RAG, short forRetrieval-Augmented Generation, is a technique that combines information retrieval and text generation to improve the accuracy and relevance of text generated by Large Language Models (LLMs). LLMs, due to the limitations of their training data, may not have access to the latest information.
The RAG workflow typically includes the following steps:
Retrieve*: Find and extract the information most relevant to the current query from a large dataset or knowledge base. Augment: Combine the retrieved information or dataset with the LLM to enhance the LLM's performance and the accuracy of its output. Generate: Use the retrieved information and the LLM to generate new text or responses.
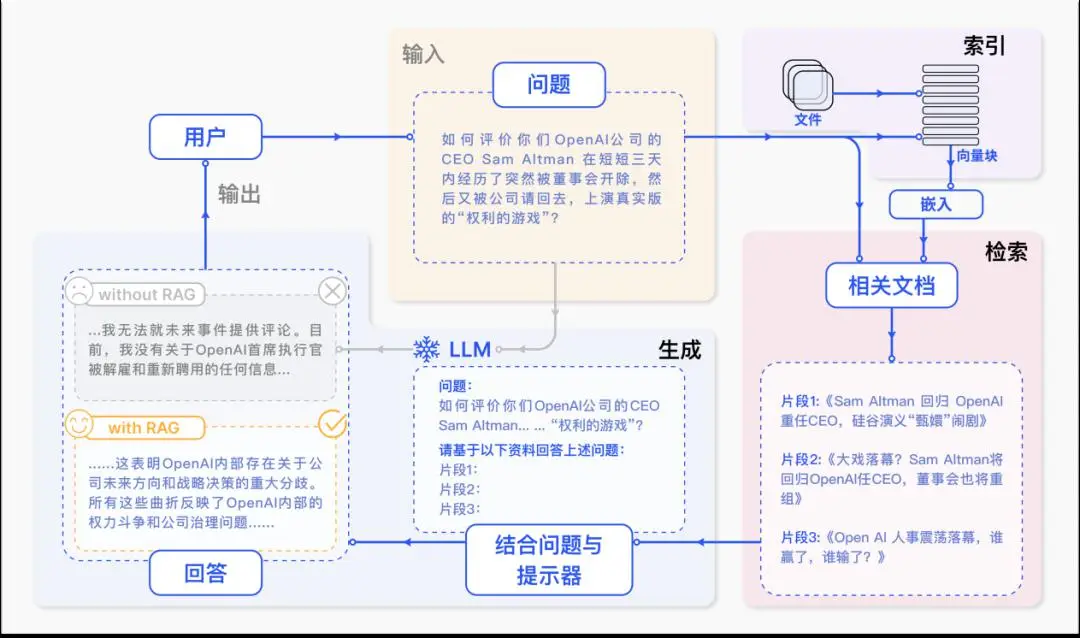
MatrixOne, as a hyper-converged database, inherently possesses vector capabilities, which play a crucial role in RAG applications. Below, we'll leverage MatrixOne Intelligence's vector capabilities to quickly build aNative RAG application.
Prerequisites
-
Python 3.8 (or plus) version installed
-
MySQL client installed
-
pymysqltool downloaded and installedpip install pymysql -
An API key obtained from Neolink.ai. Neolink.AI is a platform that comprehensively connects computing power, data, knowledge, models, and enterprise applications.
Operational Steps
Step 1: Create a table and enable vector indexing
Connect to MatrixOne Intelligence, create a table named rag_tab to store text information and corresponding vector information, then enable vector indexing.
create table rag_tab(content text,embedding vecf32(1024));
# Reconnect to the database for the setting to take effect
SET GLOBAL experimental_ivf_index = 1;
Step 2: Build the application
Create a Python file named rag_example.py and write the following content. The main purpose of this script is to vectorize text using the mxbai-embed-large embedding model and then store it in the MatrixOne Intelligence table. It then vectorizes the question, uses MatrixOne Intelligence's vector search to find the most similar text blocks, and finally combines them with the large language model llama2 to generate an answer.
vi ./rag_example.py
import time
import requests
import pymysql
conn = pymysql.connect(
host = 'freetier-01.cn-hangzhou.cluster.matrixonecloud.cn',
port = 6001,
user = '585b49fc_852b_4bd1_b6d1_d64bc1d8xxxx:admin:accountadmin', # Replace with your actual username
password = "xxx", # Replace with your actual password
db = 'db1',
autocommit = True
)
cursor = conn.cursor()
api_key='0e972228-0b50-442d-b74c-73f43314xxxx' # Replace with your personal API key
api_url_llm = "https://neolink-ai.com/model/api/v1/chat/completions"
api_url_emb="https://neolink-ai.com/model/api/v1/embeddings"
# Use Neolink.AI's online LLM and embedding models
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
documents = [
"MatrixOne is a hyper-converged cloud & edge native distributed database with a structure that separates storage, computation, and transactions to form a consolidated HSTAP data engine. This engine enables a single database system to accommodate diverse business loads such as OLTP, OLAP, and stream computing. It also supports deployment and utilization across public, private, and edge clouds, ensuring compatibility with diverse infrastructures.",
"MatrixOne touts significant features, including real-time HTAP, multi-tenancy, stream computation, extreme scalability, cost-effectiveness, enterprise-grade availability, and extensive MySQL compatibility. MatrixOne unifies tasks traditionally performed by multiple databases into one system by offering a comprehensive ultra-hybrid data solution. This consolidation simplifies development and operations, minimizes data fragmentation, and boosts development agility.",
"MatrixOne is optimally suited for scenarios requiring real-time data input, large data scales, frequent load fluctuations, and a mix of procedural and analytical business operations. It caters to use cases such as mobile internet apps, IoT data applications, real-time data warehouses, SaaS platforms, and more.",
"Matrix is a collection of complex or real numbers arranged in a rectangular array.",
]
# Text chunking, vectorization, and storage in MO
for i,d in enumerate(documents):
emb_data = {
"input": d,
"model": "BAAI/bge-m3"
}
response = requests.post(api_url_emb, headers=headers, json=emb_data)
embedding = response.json().get('data')[0].get('embedding')
insert_sql = "insert into rag_tab(content,embedding) values (%s, %s)"
data_to_insert = (d, str(embedding))
cursor.execute(insert_sql, data_to_insert)
# Create index
create_sql = 'create index idx_rag using ivfflat on rag_tab(embedding) lists=%s op_type "vector_l2_ops"'
cursor.execute(create_sql, 1)
# Question
prompt = "What is MatrixOne?"
# Vectorize the question and perform similarity search against database vectors
emb_data = {
"input": prompt,
"model": "BAAI/bge-m3"
}
response_emb = requests.post(api_url_emb, headers=headers, json=emb_data)
query_embedding= response_emb.json().get('data')[0].get('embedding')
query_sql = "select content from rag_tab order by l2_distance(embedding,%s) asc limit 3"
data_to_query = str(query_embedding)
cursor.execute(query_sql, data_to_query)
data = cursor.fetchall()
# Use LLM model to return the answer combined with database retrieval results
llm_data = {
"model": "meta-llama/Meta-Llama-3.1-405B-Instruct-FP8",
"messages": [
{
"role": "system",
"content": str(data)
},
{
"role": "user",
"content": prompt
}
]
}
response_llm = requests.post(api_url_llm, headers=headers, json=llm_data)
response_data = response_llm.json()
answer = response_data['choices'][0]['message']['content']
print(answer)
Execute the script
python ./rag_example_2.py
MatrixOne is a hyper-converged cloud & edge native distributed database. It has a structure that separates storage, computation, and transactions to form a consolidated HSTAP (Hybrid Transactional/Analytical Processing) data engine. This engine enables a single database system to accommodate diverse business loads such as OLTP (Online Transactional Processing), OLAP (Online Analytical Processing), and stream computing.